6 Infrastructure Pitfalls Slowing Down Your AI Progress
Authors


Last Updated
Share

AI teams today face constant pressure to move faster. There’s always a new AI initiative that needs to launch quickly, a cutting-edge open-source model worth integrating, or a novel inference setup that could improve performance. But instead of shipping these ideas quickly, many get stuck in backlog while teams report: “Infrastructure is slowing us down.”
Sound familiar? The core issue is that AI systems have grown increasingly complex, making deployment on traditional infrastructure an uphill battle. Unlike conventional applications, modern AI systems require:
- Frequent updates and one-off evaluation runs before reaching production
- Large models running on one or multiple GPUs
- Infrastructure setup for data parallelism, batching, request routing, queuing, autoscaling, micro-services, etc.
These are critical considerations for AI teams, but implementation often falls to dedicated infrastructure teams, which means extra delays and costs.
Ideally, AI teams would have infrastructure that provides:
- Flexibility to integrate any code, model, and runtime environment
- Rapid development iterations with immediate feedback
- Quick cloud deployment for testing, evaluation and production
- Flexible abstractions for defining AI infrastructure without complex configuration
When AI teams get mired in infrastructure tasks, innovation suffers. That’s why we built BentoML — to remove infrastructure roadblocks and help AI teams move faster. In working with enterprises deploying AI at scale, we’ve identified the six common pitfalls that slow AI teams down. In this post, we’ll share what we’ve learned and how you can fix them.
1. Your AI team is wasting time on manual infrastructure work#
Your team has just delivered a new model that could improve customer experience. But when you ask when it can go live, the answer is deflating: “We need to set up the infrastructure, which will take a couple of weeks.”
AI workloads require specialized infrastructure that demands extra engineering effort, including:
- Accelerator configurations (NVIDIA GPUs, AMD, TPUs, etc.)
- Concurrency control for reliable batching and autoscaling (including scale-to-zero)
- Compute provisioning (cross-region capacity, mixing on-demand and spot instances, shared capacity pools, etc.)
- ML/AI-specific monitoring and performance tracing
- Model-specific features, such as LLM caching, routing, and streaming mechanisms
Beyond setup, AI engineers must also learn and adapt to custom infrastructure, from building container images in a specific way to implementing metrics collection code and handling boilerplate configurations. These efforts are often duplicated across different projects with minor tweaks, requiring back-and-forth coordination between multiple teams. Over time, they have serious business implications:
- Slow innovation. Time spent on infrastructure setup is time not spent on AI development. Every week lost to deployment delays slows down innovation and reduces business impact.
- Rising talent costs. Infrastructure specialists with AI deployment expertise command premium salaries, often 30-50% higher than standard DevOps roles. This drives up project costs significantly.
- Reliability risks. Without specialized knowledge, manual configuration introduces human errors, increasing the risk of misconfiguration, unstable deployments, and system failures. Without robust observability, issues can go undetected until they impact customers.
AI teams can’t afford to spend weeks managing infrastructure. They need to focus on building, iterating, and deploying models.
BentoML solution#
BentoML transforms the infrastructure burden from weeks of manual work to simple, automated processes. The fully-managed AI inference platform provides:
- Automated deployment: Developers don’t need to manually build, configure, or push Docker images, since BentoML automates packaging, containerization, and deployment.
- Built-in autoscaling & Request queueing: Concurrency-based autoscaling responds to different traffic patterns with fast cold starts. Additionally, you can enable a request queue to buffer incoming traffic, preventing any single server from being overwhelmed.
- Comprehensive observability: BentoML provides out-of-the-box dashboards for real-time model performance insights. These include LLM-specific metrics to track inference efficiency, latency, and errors.
“BentoML’s infrastructure gave us the platform we needed to launch our initial product and scale it without hiring any infrastructure engineers. As we grew, features like scale-to-zero and BYOC have saved us a considerable amount of money.”
—— Patric Fulop, CTO of Neurolabs
2. Your infrastructure limits what ML tools you can use#
Most AI/ML infrastructure implementations lock runtimes (e.g., PyTorch and vLLM) to specific versions. The primary reason is to cache container images and ensure compatibility with infrastructure-related components. While this simplifies deployment in clusters, it also restricts flexibility when you need to test or deploy newer models or frameworks that fall outside the supported list.
As the AI runtime space rapidly evolves, this limitation becomes an even bigger challenge. For LLMs alone, teams must choose from a growing number of implementations (e.g. vLLM, LMDeploy, MLC-LLM, TensorRT-LLM, and TGI), each with different trade-offs in performance, throughput, and latency.
When AI teams are forced to work within rigid, outdated environments, it means:
- Competitive disadvantage. When your team can't leverage cutting-edge models/tools, you lose the race to deliver AI innovations. This is particularly damaging in fast-moving sectors like finance, retail, and healthcare.
- Increased engineering effort and tech debt. Without an easy way to update runtimes, teams are forced to build workarounds. These quick fixes pile up, creating long-term technical debt that makes future deployments even harder.
- Delayed AI deployments. Runtime compatibility issues can add 2-4 weeks to deployment timelines as teams either wait for infrastructure updates or develop complex workarounds.
BentoML solution#
BentoML gives AI teams the freedom to use any ML tool, model, or framework without waiting on infrastructure updates.
- Unified AI serving infrastructure. BentoML lets developers bring their own inference code and custom libraries, with community driven docs and examples providing best practices for working with common ML/AI libraries.
- Customizable runtimes. Developers can easily customize runtime environments with a single line of Python code. BentoML automates the rest, ensuring a reproducible environment across development and deployment.
"BentoML provides our research teams a streamlined way to quickly iterate on their POCs and when ready, deploy their AI services at scale. In addition, the flexible architecture allows us to showcase and deploy many different types of models and workflows from Computer Vision to LLM use cases.”
—— Thariq Khalid, Senior Manager, Computer Vision, ELM Research Center
3. Your infrastructure is built for models, not AI systems#
AI models alone don’t deliver business value. They need to be integrated into a broader AI system. Beyond simply loading model weights, you may also need additional components, such as:
- Pre-processing logic to clean, format, or enrich input data
- Post-processing logic to refine model outputs for end-users
- Inference code that implements complex pipelines, particularly for GenAI models
- Business logic for validation, internal API calls, or data transformations
- Data fetching to retrieve additional information from a feature store or database
- Model composition to build multi-model pipelines
- Custom API specifications to ensure the right request/response format
But here’s the challenge: Traditional frameworks and tools aren’t built for advanced code customization; they only offer rigid, predefined API structures with limited flexibility. Adding custom logic often means hacking together workarounds or spreading business logic across multiple services. This results in unnecessary complexity and maintenance overhead.
- Increased engineering effort. Custom API configurations often require extra engineering work, slowing down development and delaying time to market.
- Poor developer experience. If AI services can’t format responses to fit business needs, developers may struggle to leverage deployed AI services and integrate them into applications.
- Innovation barriers. Limited customization prevents teams from creating truly differentiated AI products that solve specific business problems in unique ways.
BentoML solution#
BentoML provides first-class support for custom code.
-
Custom code lives with the model. Instead of defining preprocessing, postprocessing and business logic across different services and managing them via completely different processes, BentoML lets developers customize these steps directly within the model deployment pipeline using idiomatic Python.
-
Multi-model pipelines & distributed AI services. BentoML provides simple abstractions for building workflows where:
- Multiple models work together, either in sequence (one after another) or in parallel (at the same time).
- AI services can be easily distributed for advanced use cases like pipelining CPU and GPU processing and optimizing resource utilization and scalability.
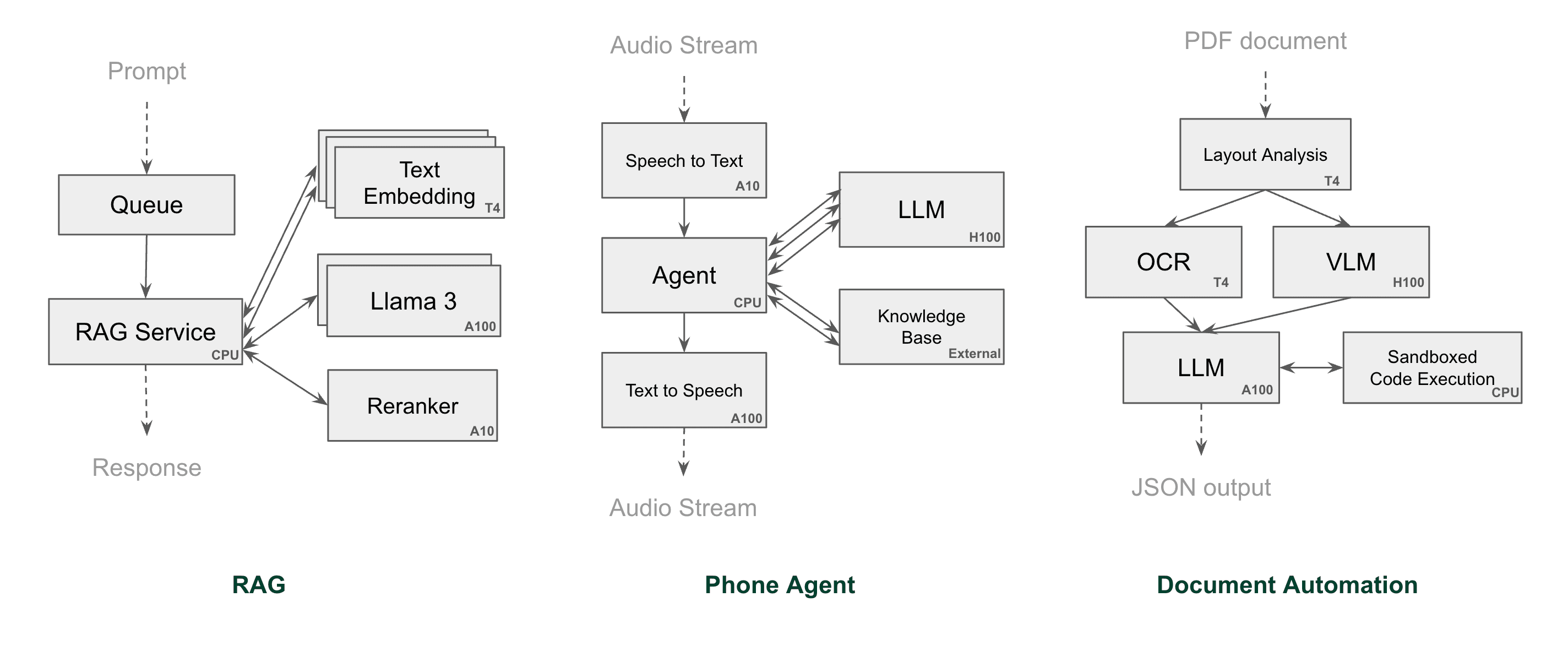
4. Long dev iteration cycles kill innovation#
You’re deep in development, refining your model inference code and business logic. You change a few lines of code but hesitate before testing: it can take tens of minutes or even hours to get it up and running again.
Why? Your model requires GPUs, and your laptop simply doesn’t have the power. That means you need to redeploy everything to the cloud, a process that involves:
- Releasing code to a custom Git branch for deployment
- Waiting for a new container image to build with the latest changes
- Uploading the image to a cloud registry
- Navigating multiple complex YAML files to update the container image tag, model version, instance type, or secrets
- Waiting for compute resources to be ready
- Waiting for the image and model to be downloaded onto the node
- Waiting for the code and model to load
- Searching through logs for debugging
By the time you see an error message about a simple config mistake, 30 minutes has passed. But it’s not just code iteration that suffers. Any adjustment to inference setup, model configurations, or infrastructure faces the same problem. For every single iteration, you need a complete end-to-end evaluation run.
Such development iteration is just painfully slow.
When AI teams are forced to work within slow iteration loops, the consequences go beyond just wasted time:
- High deployment risks. Slow iteration discourages frequent testing. This increases the risk of shipping untested models into production, leading to costly fixes and unstable releases.
- Engineering talent drain. AI engineers thrive in fast, iterative environments. When forced to work with slow feedback loops, morale and productivity plummet.
- Limited innovation. The longer iteration takes, the slower your AI team moves, and the harder it is to stay ahead of the competition.
BentoML solution#
BentoML gives developers instant feedback loops for code, model, and infrastructure changes.
-
Local development. BentoML supports running and testing code locally, when the development environment has the necessary compute resources.
-
Cloud development with BentoML Codespaces. It allows you to run your development environment instantly in the cloud and:
- Access various powerful cloud GPUs from your favorite IDE.
- Make changes locally and see them reflected in the cloud in real time.
- Eliminate dependency headaches with an auto-provisioned environment that just works.
- Deploy models to production via one click with guaranteed consistency between dev and prod.
Here is a demo of adding function calling to a phone calling agent built with Codespaces.
-
Fast cold starts. Your code and models reload quickly upon changes, minimize waiting time.
“BentoML allows us to build and deploy AI services with incredible efficiency. What used to take days, now takes just hours. In the first four months alone, we brought over 40 models to production, thanks to BentoML’s inference platform.”
—— Director of Data Science at NYSE listed Technology Company
5. You don’t have enough GPUs#
Typical AI infrastructure is tied to a single cloud provider and region, which may not have the GPU capacity you need. If you switch to another provider, it often means rebuilding your infrastructure stack from scratch, a process that could take months.
When your team doesn’t have the compute resources they need, the impact goes far beyond just waiting in a queue:
- Slower AI feature releases. Weeks of waiting for GPUs delay product launches and stifle innovation.
- Inflated costs. To avoid being caught without compute resources, many companies over-provision GPUs (e.g. for scaling during traffic peaks). Sometimes they must pay for 2-3x more resources than they actually need. This can add hundreds of thousands of dollars to annual AI infrastructure costs.
- Security & compliance risks. Many businesses must keep AI workloads in specific regions or private infrastructure due to data privacy regulations (e.g. GDPR). If their primary cloud provider runs out of GPUs, they can’t just switch without violating security policies.
BentoML solution#
BentoML gives your team the freedom to deploy models anywhere, without re-engineering your stack.
- Cloud-agnostic. BentoML allows you to deploy your models on any public cloud, AI NeoCloud, or on-premises infrastructure. You can select the desired provider and region, and let BentoML manage compute provisioning, balancing availability and cost.
- Maximized GPU utilization. Instead of over-provisioning to ensure capacity, BentoML ensures you only pay for what you use. It dynamically scales GPUs to meet demand with fast cold starts. Most teams using BentoML see GPU utilization rates averaging 70% or higher.
- Compliance without compromise. The BentoCloud's BYOC option ensures you can keep sensitive data within your private VPC without sacrificing GPU access.
6. Fragmented InferenceOps limits your growth#
You finally deployed a few models in the cloud. Congratulations! At first, everything seemed fine. But soon, the operational chaos begins:
- Head of AI: “How many models do we have running in production? And how much does running model A cost us?”
- Application Developer: “This model isn’t responding, and now the entire application is down. What happened?”
- DevOps Engineer: “There is a GPU instance that’s been running for months. Is anyone even using it?”
- AI Intern: “I fixed a small bug in this ML service. How do I deploy it?”
These questions highlight a fundamental problem: lack of standardization. Without unified AI operations - what we call InferenceOps, routine tasks turn into painful cross-team coordination.
As you scale AI deployments, the fragmentation worsens. More models and types, more frequent updates, and more clouds and regions all require standardized workflows and centralized management. Otherwise, maintenance issues can compound, leading to:
- Operational inefficiencies. Manual handoffs between ML, DevOps, and security teams slow down iteration cycles and limit your ability to scale AI workloads.
- Performance degradation. Without proper observability, AI models can drift and degrade, leading to less accurate predictions and poor business outcomes.
- Increased costs and risk of downtime. Mismanaged GPU instances, unused resources, and lack of automation lead to wasted infrastructure costs and greater risk of service disruptions. They impact both revenue and end-user experience.
BentoML solution#
BentoML provides a future-proof infrastructure to support scalable AI maintenance and InferenceOps.
- Simplified deployment management. Developers can run and manage deployments with a set of CLI and Python APIs, directly from GitHub or a local development environment.
- Centralized observability. Teams can detect drift, track inference quality, monitor GPU utilization, and ensure AI models stay optimized over time.
- Scalable InferenceOps. With standardized workflows for development, deployment, and maintenance, BentoML ensures teams can efficiently manage multiple AI models and systems in a unified fashion.
Conclusion#
Bringing AI models from development to production shouldn’t take months. For many teams, however, it does. The above-mentioned six pitfalls often hold teams back, delaying innovation and increasing costs.
BentoML removes these roadblocks by automating deployment, scaling, and infrastructure management. This allows AI teams to focus on what they do best: building innovative AI solutions that drive business value. With BentoML, teams can speed up AI development by up to 20x, delivering models to production faster and staying ahead of the competition.
Ready to deploy AI models faster?
- Contact us for expert guidance on shipping AI models to production.
- Join our community to stay updated on the latest AI developments.
- Sign up for our inference platform and start building today.