Deploying Llama 3.2 Vision with OpenLLM: A Step-by-Step Guide
Authors

Last Updated
Share

Llama 3.2 from Meta introduces the first multimodal models in the series. The vision-enabled 11B and 90B parameter multimodal LLMs can now process and understand both text and images! This makes Llama 3.2 great for tasks such as:
- Information extraction from image/PDF files
- Understanding image and ask questions about it (e.g. Visual QA, Image captioning, Accessibility, Medical imaging)
- Quality control automation (e.g. software UI, manufactured products)
This tutorial will guide you through the process of self-hosting Llama 3.2 Vision as a private API endpoint using OpenLLM.
Get Access to the Model#
Llama 3.2 models are gated and require users to agree to the Llama 3.2 community license agreement. Follow these steps to get access:
- Go to the Llama-3.2-11B-Vision model page on HuggingFace.
- Apply for access by agreeing to the license terms.
- Once approved, generate a read token from your HuggingFace account.
- Set the token as an environment variable:
export HF_TOKEN=<YOUR READ TOKEN>
Installing OpenLLM#
To get started with OpenLLM, install it using pip:
pip install openllm # Update supported models list openllm repo update
Running Locally#
In this tutorial, we are using the meta-llama/Llama-3.2-11B-Vision-Instruct model. To run this model locally, a GPU with at least 40GB GPU memory, such as Nvidia A100 or L40S, is required. Spin up the LLM API server with OpenLLM:
openllm serve llama3.2:11b-vision
Visit http://localhost:3000/ to see API specification details.
No GPU on your local machine? No problem! Move forward to the Cloud Deployment section.
We're working on supporting quantization for the Llama3.2 Vision model, which would allow it to run on smaller GPUs.
For text-generation only, tryopenllm serve llama3.2:1b.
API Usage#
OpenLLM provides an OpenAI-compatible API for easy integration. Here's how you can use it with Image and Text input:
from openai import OpenAI client = OpenAI(base_url="http://localhost:3000/v1") # get the available models # model_list = client.models.list() # print(model_list) response = client.chat.completions.create( model="meta-llama/Llama-3.2-11B-Vision-Instruct", messages=[ { "role": "user", "content": [ {"type": "text", "text": "What’s in this image?"}, { "type": "image_url", "image_url": { "url": "https://upload.wikimedia.org/wikipedia/commons/e/ea/Bento_at_Hanabishi%2C_Koyasan.jpg", }, }, ], } ], max_tokens=300, ) print(response.choices[0])
Example output from the Llama3.2 Vision model:
Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='The image shows a traditional Japanese lunchbox, called a bento, which is a self-contained meal typically served in a wooden or plastic box. The bento in the image consists of various small dishes arranged in separate compartments, including rice, miso soup, and other side dishes such as vegetables, fish, and meat. The bento is placed on a tray with chopsticks and a small bowl of soup. The overall presentation of the bento suggests that it is a carefully prepared and visually appealing meal, likely intended for a special occasion or as a gift.', refusal=None, role='assistant', function_call=None, tool_calls=[]), stop_reason=None)
Cloud Deployment#
BentoCloud offers a hassle-free way to deploy your Llama 3.2 Vision model, providing fast deployment times and flexible customization without the need to manage infrastructure. You can deploy to compute resources available on BentoCloud, or Bring Your Own Cloud, which brings the BentoCloud serving & inference stack to your AWS, GCP or Azure cloud environment.
Here's how to get started:
1. Log in to BentoCloud and create an API token:
bentoml cloud login
2. Deploy the model:
openllm deploy llama3.2:11b-vision
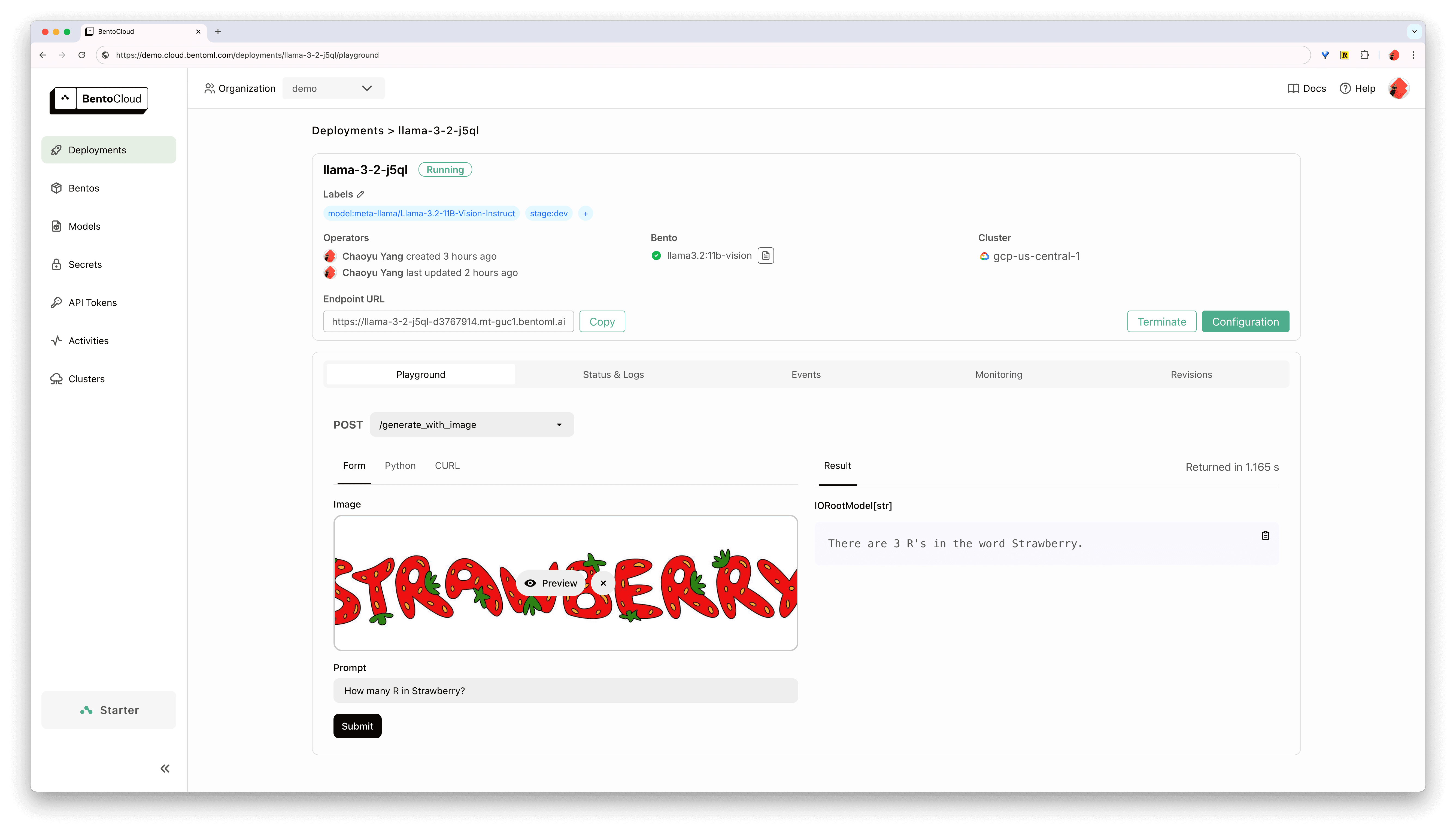
Once deployed, you can interact with your API endpoint using the BentoCloud UI:
To access your deployed API, simply change the base_url to the deployed endpoint URL:
from openai import OpenAI client = OpenAI( base_url="https://{replace-with-your-deployment-endpoint}.bentoml.ai/v1", api_key="n/a" # set to your BentoCloud API token when endpoint protection is enabled )
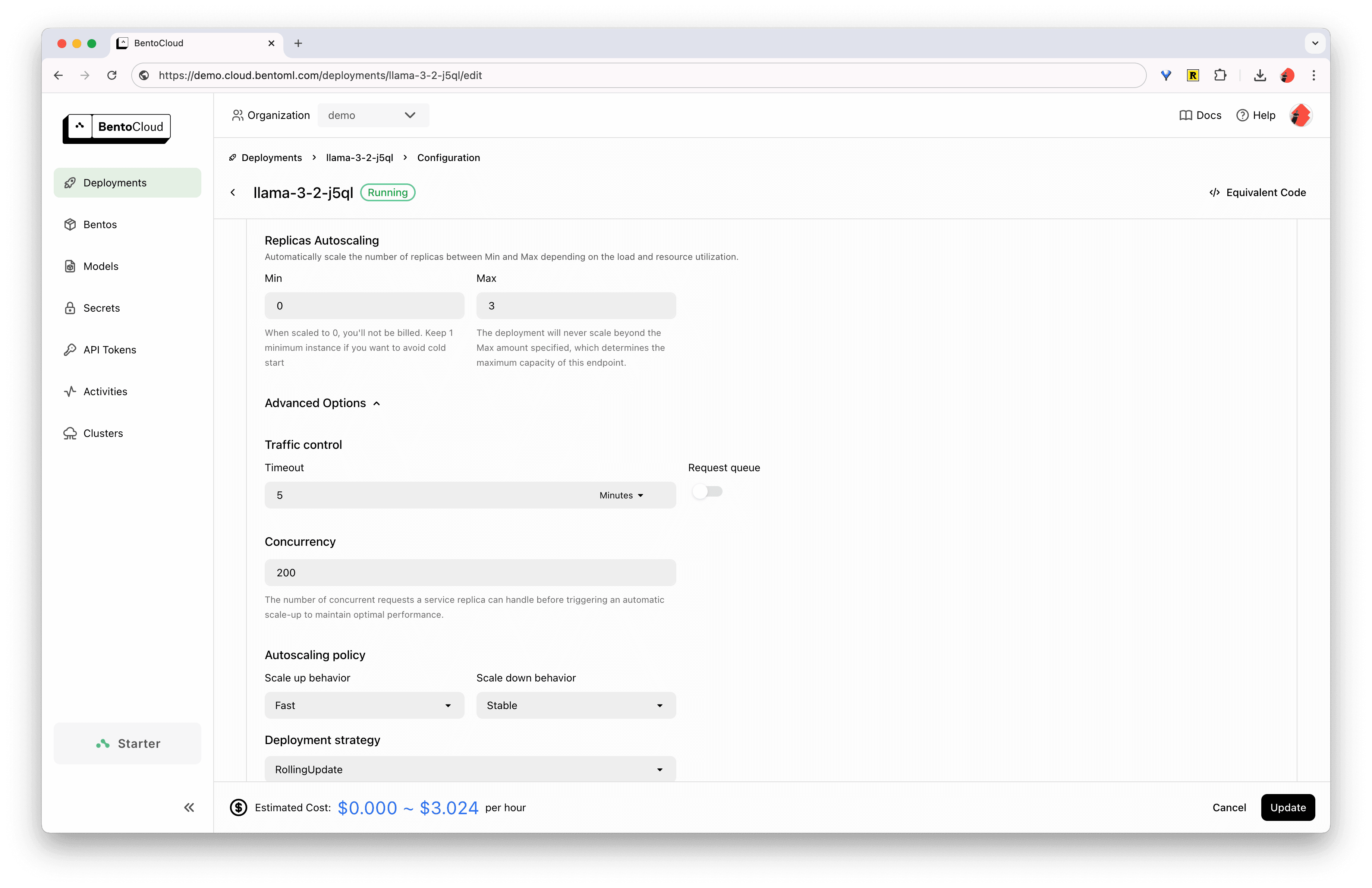
You can further configure the deployment’s scaling behavior, concurrency control and endpoint protection from the BentoCloud UI:
For those interested in using the 90B instruct model, check out the BentoVLLM repository for more information.
Conclusion#
Deploying Llama 3.2 Vision with OpenLLM and BentoCloud provides a powerful and easy-to-manage solution for working with open-source multimodal LLMs. By following this guide, you've learned how to set up, deploy, and interact with a private deployment of Llama 3.2 Vision model, opening up a world of possibilities for multimodal AI applications. If you’re deciding between using an LLM API provider or self-hosting dedicated LLM deployment, check out our analysis here.
Ready to get started? Sign up for BentoCloud today and join the BentoML developer community on Slack for more support and discussions!