Accelerate AI Application Development with BentoML Codespaces
Authors

Last Updated
Share

⚠️ Note: Bento is now part of Modular! Sign up for the Modular Platform and schedule a call with us to learn how Bento and Modular can help you serve high-performance inference in production.
Modern AI applications are becoming increasingly sophisticated, often incorporating multiple components. This is because the true power of AI lies not just in the capabilities of individual models, but in how effectively they are orchestrated within a larger system.
A typical example of such an application is a phone calling AI agent. At a high level, this system relies on three key models:
- Speech-to-Text (STT): Converts the user’s voice input into text.
- Large Language Model (LLM): Acts as the "brain" of the agent, interpreting user queries and generating appropriate responses.
- Text-to-Speech (TTS): Streams the LLM's text response back into audio for the user.
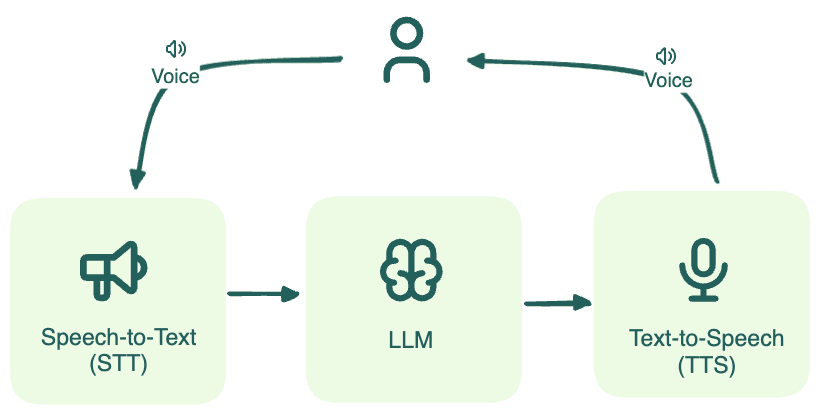
Both open-source models and closed-source model APIs can be utilized for building the voice agent. In this article, we focus on open-source models because they offer better control over data security and privacy, support advanced customization, and ensure more predictable behaviors in production environments. For a deeper exploration of this topic, refer to our blog post Serverless vs. Dedicated LLM Deployments: A Cost-Benefit Analysis.
Run each component on designated hardware#
When designing a voice agent, simply having AI models is not enough. We need an architecture where each component integrates seamlessly and is matched to the most suitable hardware.
In addition to the models mentioned above, a voice agent should also include the following elements:
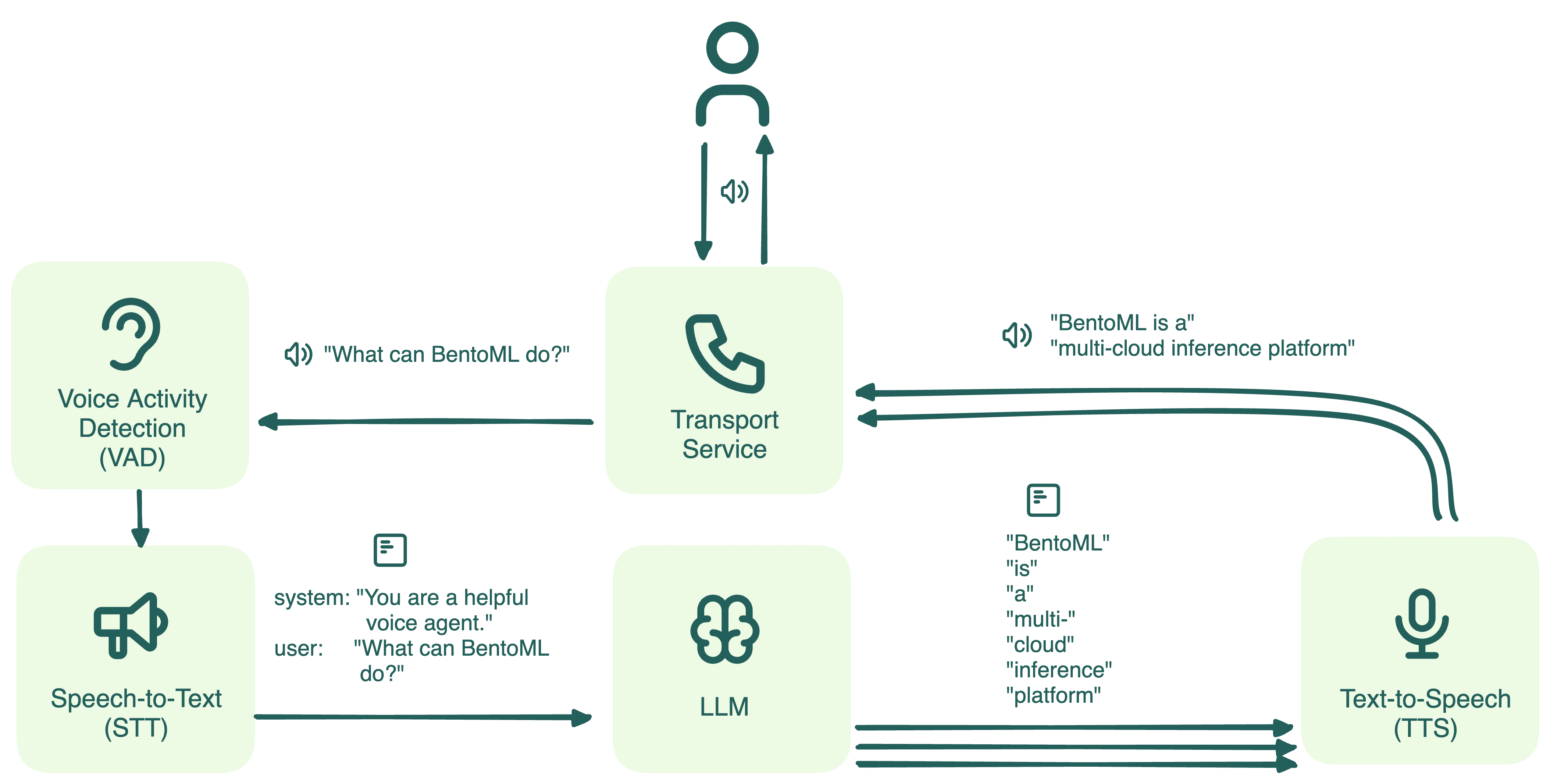
- Voice Activity Detection (VAD): Detects when the agent should speak and when it should listen, managing interruptions from the user. In this example, we implement VAD using Silero.
- Transport Service: Manages the transmission of voice data between the user and the backend system. We use Twilio as the transport service and WebSocket as the communication protocol.
- Voice Pipeline: Orchestrates the interaction between components, coordinating when to pause for additional input or initiate output generation. By streaming the LLM's output to the TTS model in real-time, the pipeline ensures that voice responses are generated progressively, reducing wait times and allowing the user to hear responses as they are being generated. In this example, we use the Pipecat framework.
By combining BentoML with these elements, we propose the following deployment topology for the phone calling agent:
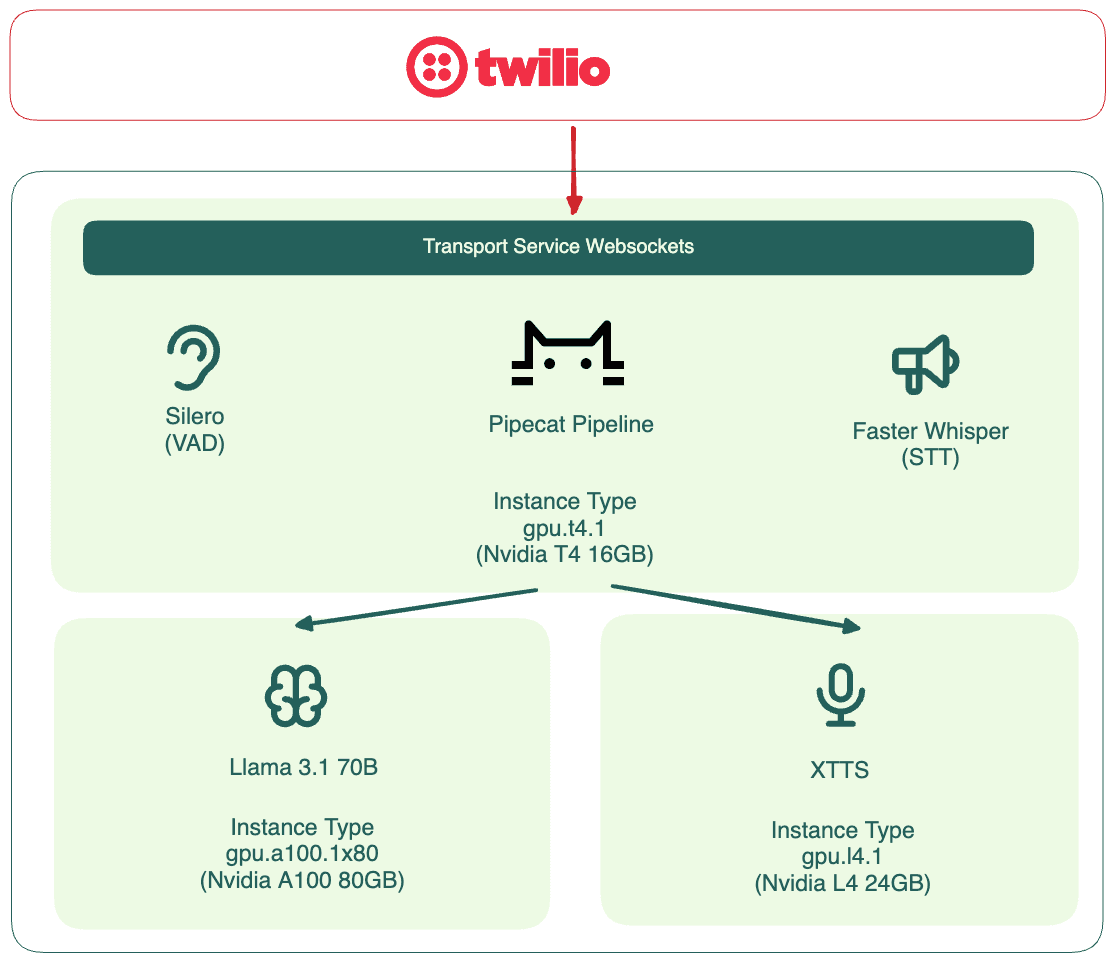
In addition to Twilio for voice transmission, this architecture includes three major components, each abstracted into a BentoML Service. A key benefit of BentoML is its support of selecting dedicated GPU types for each AI service:
- The LLM Service, powered by Llama 3.1 70B, can run on an NVIDIA A100 80GB GPU for efficient inference.
- The XTTS Service may not require as much concurrency as the LLM, so it can run and scale independently on a lighter GPU like an NVIDIA L4 24GB GPU.
- VAD, Pipecat and STT are more lightweight so they can share a T4 16GB GPU.
This architecture is beneficial because it ensures each model runs on the most suitable hardware, thus maximizing performance. Moreover, it allows each component to scale independently based on its unique workload characteristics. For detailed insights into scaling, see the article Scaling AI Models Like You Mean It.
See this GitHub repository to explore the complete code of this voice agent example.
The challenges of AI application development#
Now that we've explored the ideal setup, let's examine the common challenges developers encounter during AI application development.
Limited access to a variety of powerful GPUs#
AI applications like the phone calling agent often require different types of powerful GPUs for specific tasks, such as A100, L4 and T4. In development environments, even if developers have access to a GPU locally, they often lack the variety needed to simulate production. This prevents them from testing and developing the application effectively. The complexity is further compounded by the challenge of coordinating inter-service communication across different models and GPUs.
Slow iteration cycles#
AI application development is highly iterative and requires frequent updates and tweaks to models, code, or configurations. For every change, no matter how small, you may need to:
- Rebuild container images
- Redeploy to a cloud GPU for testing
This process can take several minutes to tens of minutes, depending on the size of your codebase and the resources available. These delays can slow down development, making experimentation and rapid iteration difficult. In the case of the voice agent, adjusting the response or optimizing the pipeline could take much longer than necessary, disrupting your development flow.
Inconsistent behaviors between development and production environments#
For complex applications, developers may use simplified setups locally for testing purposes. A common approach is running all models on a single GPU. However, in production, different components need to run and scale independently across multiple GPUs to handle the actual workloads.
This mismatch between development and production environments can lead to inconsistent behaviors and unexpected errors. It also means you need additional tweaking when moving from development to production, which will further slow down your iteration cycle.
How Codespaces solves the problems#
To address these challenges, we developed Codespaces, a development platform built on BentoCloud. BentoCloud is our inference platform designed to build and deploy scalable AI applications with production-grade reliability, without the complexity of managing infrastructure. See BentoCloud: Fast and Customizable GenAI Inference in Your Cloud for more details.
Here’s how Codespaces helps:
Access to various powerful GPUs#
Codespaces synchronizes your local development environment with BentoCloud. This means you can continue using your preferred IDE while leveraging a range of powerful cloud GPUs (e.g. A100, L4 and T4) best suited to your needs.
20x faster iteration#
Codespaces dramatically accelerates iteration cycles. Every time you update your local code, the changes are automatically pushed to BentoCloud and applied instantly. This means you can view live logs and debug your application in real-time via a cloud dashboard. This gives you immediate feedback, making it easier to troubleshoot and iterate quickly.
Here is an example of adding function calling capabilities to the phone calling agent. You can see the result of the change immediately.
Once you’re happy with your change, Codespaces enables you to build your Bento and deploy it to production with just one click. The entire process is 20x faster than traditional methods, saving significant time during the development cycle.
Consistent and predictable performance across environments#
When you connect your local environment with Codespaces, it automatically provisions the necessary environments. This ensures all dependencies are managed consistently and that your code runs on the same infrastructure in both development and production environments.
With consistent setups, you no longer need to waste time tweaking configurations for production. This approach also gives you the confidence that your code will perform as expected when deployed to production.
Conclusion#
BentoML Codespaces empowers developers to accelerate iteration by focusing on building innovative AI solutions, free from infrastructure concerns. It represents the ideal platform for rapidly and confidently deploying scalable AI models.
Get started with Codespaces today! More resources: