AMA With Hamza Tahir from ZenML
Dec 20, 2022
We regularly invite ML practitioners and industry leaders to share their experiences with our Community. Want to ask questions to our next guest? Join BentoML Community Slack

We recently invited Hamza Tahir. Hamza is the co-founder of ZenML. ZenML is an open-source MLOps framework to create reproducible Machine Learning pipelines. A reoccurring struggle in machine learning is the large gap between the training part of the ML development and the post-training/deployment phase. ZenML aims to bridge that gap, by building a simple, open-source, pipeline framework aimed toward data scientists to create ML workflows that can be taken to production with minimum effort.
Key Takeaways:
- MLOps orchestration
- The emerging MLOps toolchain
- What’s the missing gap in MLOps
What Is ZenML?
ZenML is an extensible, open-source MLOps framework for creating portable, production-ready MLOps pipelines. It's built for data scientists, ML Engineers, and MLOps Developers to collaborate as they develop to production. ZenML has simple, flexible syntax is cloud- and tool-agnostic, and has interfaces/abstractions that are catered towards ML workflows. ZenML brings together all your favorite tools in one place so you can tailor your workflow to cater to your needs
What Is The Value Added Of ZenML For Users Who Have Already Set Up A Workflow (Mlflow -> BentoML -> AWS)?
I view ZenML as a tool that 'sits between' different MLOps tools and allows it to chain together different parts of the workflow seamlessly. It not only allows you to string together various MLOps tooling in a standardized, clean manner but also allows you to 'delay' MLOps decisions that you might not be willing to make depending on where you are in the journey.
Additionally, ZenML provides a simple, intuitive interface to write your pipelines and lets users utilize deep integrations into standard tools like Mlflow and BentoML to really focus on the actual value part, which sits on top of these tools.
Are There Any Video Tutorials You Recommend For Someone Wanting To Get Started With Zenml?
Yes indeed, ZenML has its own YouTube channel that we keep updated regularly and have big plans for! For beginners, I particularly like the 101 workshops hosted by my colleague @Safoine EL KHABICH for the ZenML Month of MLOps Competition which has recently concluded: https://www.youtube.com/watch?v=Ca7-kb21A6k&ab_channel=ZenML
There are also other places to start if you prefer anything other than video:
- 📒 ZenML Docs is a great entry point to learn about ZenML
- 🍰 ZenBytes - A guided and in-depth tutorial on MLOps and ZenML
- 🗂 ZenFiles - End-to-end projects using ZenML
Who Is Your Target Audience, And Why Do They Need It?
We find that many different sorts of teams like to use ZenML, but I think currently, ZenML is most useful for teams that have a few tools already using and are progressing into their MLOps journey. For example, suppose you are using MLflow for experiment tracking and BentoML for deployment. In that case, ZenML can be used to orchestrate a workflow that connects these two seamlessly into a unified pipeline.
As for persona, we usually find people who have the job to serve internal data scientists gravitate the most towards ZenML as it gives a great overview of your MLOps stack and workflows
Do You See The Future Of Mlops As More Of End To End Or Modular Approach?
I think so - The problem with ML in production is that different use cases and problems depending on the use case, the knowledge of the people in the company, the legacy tech architecture, and the inherent complexity of the data being learned on.
This has lead to an explosion of tools in space, thousands of tools from labeling to monitoring, and few leaders. I believe this will consolidate to some extent every year moving forward, but there will always be a need for flexibility in the MLOps workflow toolchain, just given the complexity of the problems being solved.
On a side note, that’s why I feel like platform plays that are lock-in and non open-source are quite risky given that fact.
Which Tools In The MLOps Space Do You Like The Most?
I like the aesthetic of Explosion, their tools including spaCy are delightful. Hugging Face is not far behind. MLflow, I believe, is just so intuitive, and there is a reason they now reached 100 million monthly downloads today, so I believe that tool has a bright future.
From Your Observation, What’s The Part Of The ML Workflow That Gives The Biggest Problem To People?
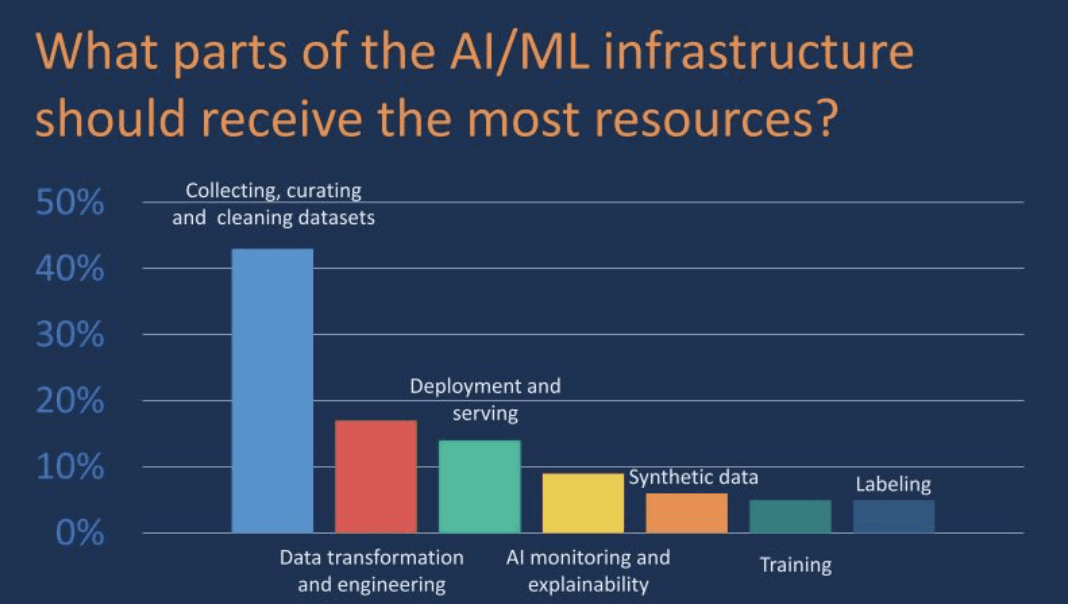
That’s a good one. Today, I saw the r survey by Themis (a think tank in Berlin) with c. 300 responses (part of the AI Infrastructure report 2022). See the report attached.
That says that "Collecting, curating, and cleaning datasets" is by far the biggest problem in productionalizing ML, followed by data transformation and engineering. While this may be true, I feel like respondents might mean different things when answering such a question in a survey. The real question is, What is the actual problem in collecting, curating, and cleaning datasets. Is it the size of the data? Is it the nature of the transformations? Is it the access to the data itself?
I feel like the main problem is that all of these are intertwined. You can collect, curate, and clean datasets, but you can only do that once at a certain quality, and then after the model is deployed, the real trouble begins. How do you set up a repeatable, high velocity, high-quality MLOps process that allows you to do these individual challenging things again and again with full visibility and reproducibility. That’s the real challenge
What Was Your Impression Of BentoML Compared To Other Serving Frameworks?
I find BentoML very intuitive and well-designed. Before starting ZenML, it was the framework I used the most because I simply found it easier to work with than other tools in the space. This is where I feel like it shines: The barrier of entry is low for beginners, unlike maybe other tools.
On the feature side, Bento is also useful if you are not tied to a K8s setup. Also, I feel like the performance boosts in 1.0 are worth keeping an eye out for and would be helpful for teams that are senstitive to latency requirements.
One thing I do find sometimes challenging with Bento, however, the input and output data types. It would be easier to use native data types for setting up the svc.api function but I’m sure the team had a technical reason for imposing that!
How Do You Handle Breaking Changes With The Integrations That You Support?
We have a suite of unit tests and an internal integration/system testing harness that we trigger on certain events via GitHub Actions. You can see some of these here. We try to make sure that we pin dependencies and communciate which dependencies are installed (e.g. We make users go through zenml integration install rather than pip install to hook into the pip install process and pin the right libraries that we have tested.
Ultimately though, things slip through the cracks, and we rely on our community for reporting and helping us out when that does happen!
What Advice Would You Give To Someone Starting Out In MLOps?
- Learn software engineering principles first - Ensure you understand standard DevOps principles that are tried and tested (testing, CI/CD, robustness, 12 factor app, etc)
- Employ empathy for the stakeholders involved. Understand what data scientists, ops, engineers want in their daily life and what they are fulfilled by
- Practice and play around with many tools and make end-to-end projects in your spare time.
Some resources I always share:
- • A Chat with Andrew on MLOps: From Model-centric to Data-centric AI https://www.youtube.com/watch?v=06-AZXmwHjo
- • Why data scientists don’t need to know Kubernetes https://huyenchip.com/2021/09/13/data-science-infrastructure.html
- MLOps Course MadeWithML https://madewithml.com/
- • CS 329S: Machine Learning Systems Design https://mlsys.stanford.edu/
I’ve Seen More Open Source Activities In Germany Lately. Could You Help Give A Brief View Of The OSS Community In Germany Or In Europe?
It’s booming! There are so many cool companies here, like Explosion (spaCy), Jina AI, Gitpod, deepset, etc., and I believe the more there are, the more people believe they can do it too. The open-source startup play is becoming increasingly well-established, and people are willing to back pre-revenue bottoms-up open-source companies more than ever.
* The discussion was lightly edited for better readability.