Benchmarking LLM Inference Backends
Authors




Last Updated
Share

Choosing the right inference backend for serving large language models (LLMs) is crucial. It not only ensures an optimal user experience with fast generation speed but also improves cost efficiency through a high token generation rate and resource utilization. Today, developers have a variety of choices for inference backends created by reputable research and industry teams. However, selecting the best backend for a specific use case can be challenging.
To help developers make informed decisions, the BentoML engineering team conducted a comprehensive benchmark study on the Llama 3 serving performance with vLLM, LMDeploy, MLC-LLM, TensorRT-LLM, and Hugging Face TGI on BentoCloud. These inference backends were evaluated using two key metrics:
- Time to First Token (TTFT): Measures the time from when a request is sent to when the first token is generated, recorded in milliseconds. TTFT is important for applications requiring immediate feedback, such as interactive chatbots. Lower latency improves perceived performance and user satisfaction.
- Token Generation Rate: Assesses how many tokens the model generates per second during decoding, measured in tokens per second. The token generation rate is an indicator of the model's capacity to handle high loads. A higher rate suggests that the model can efficiently manage multiple requests and generate responses quickly, making it suitable for high-concurrency environments.
Key benchmark findings#
We conducted the benchmark study with the Llama 3 8B and 70B 4-bit quantization models on an A100 80GB GPU instance (gpu.a100.1x80) on BentoCloud across three levels of inference loads (10, 50, and 100 concurrent users). Here are some of our key findings:
Llama 3 8B#
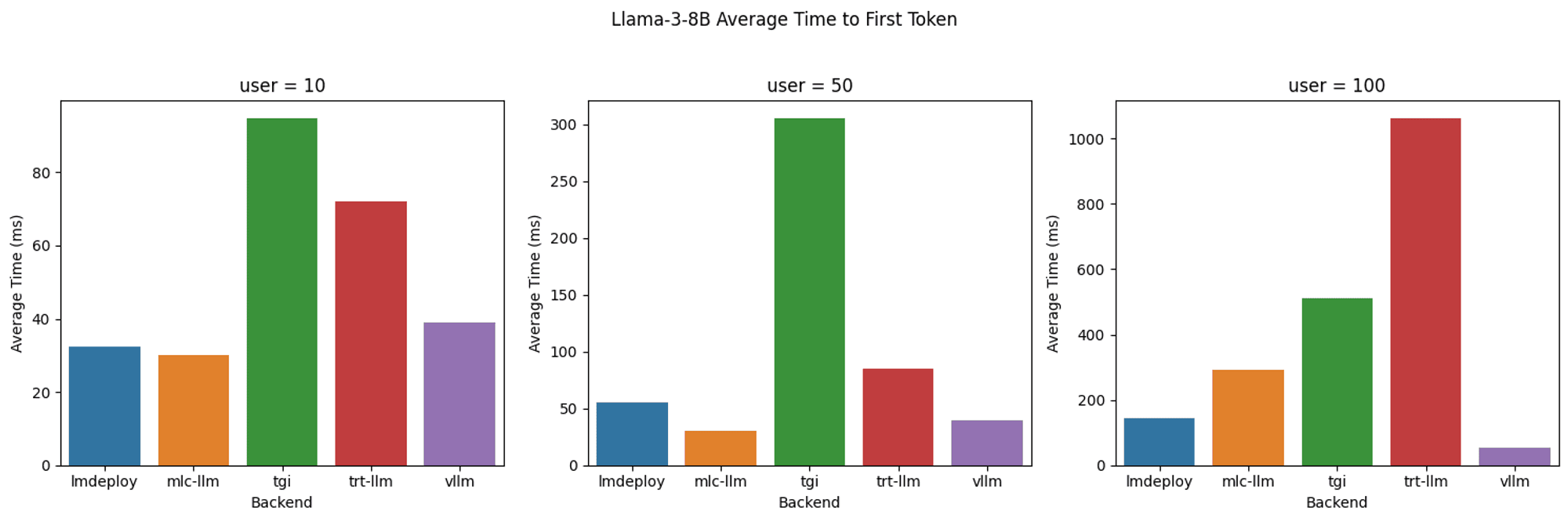

- LMDeploy: Delivered the best decoding performance in terms of token generation rate, with up to 4000 tokens per second for 100 users. Achieved best-in-class TTFT with 10 users. Although TTFT gradually increases with more users, it remains low and consistently ranks among the best.
- MLC-LLM: Delivered similar decoding performance to LMDeploy with 10 users. Achieved best-in-class TTFT with 10 and 50 users. However, it struggles to maintain that efficiency under very high loads. When concurrency increases to 100 users, the decoding speed and TFTT does not keep up with LMDeploy.
- vLLM: Achieved best-in-class TTFT across all levels of concurrent users. But decoding performance is less optimal compared to LMDeploy and MLC-LLM, with 2300-2500 tokens per second similar to TGI and TRT-LLM.
Llama 3 70B with 4-bit quantization#
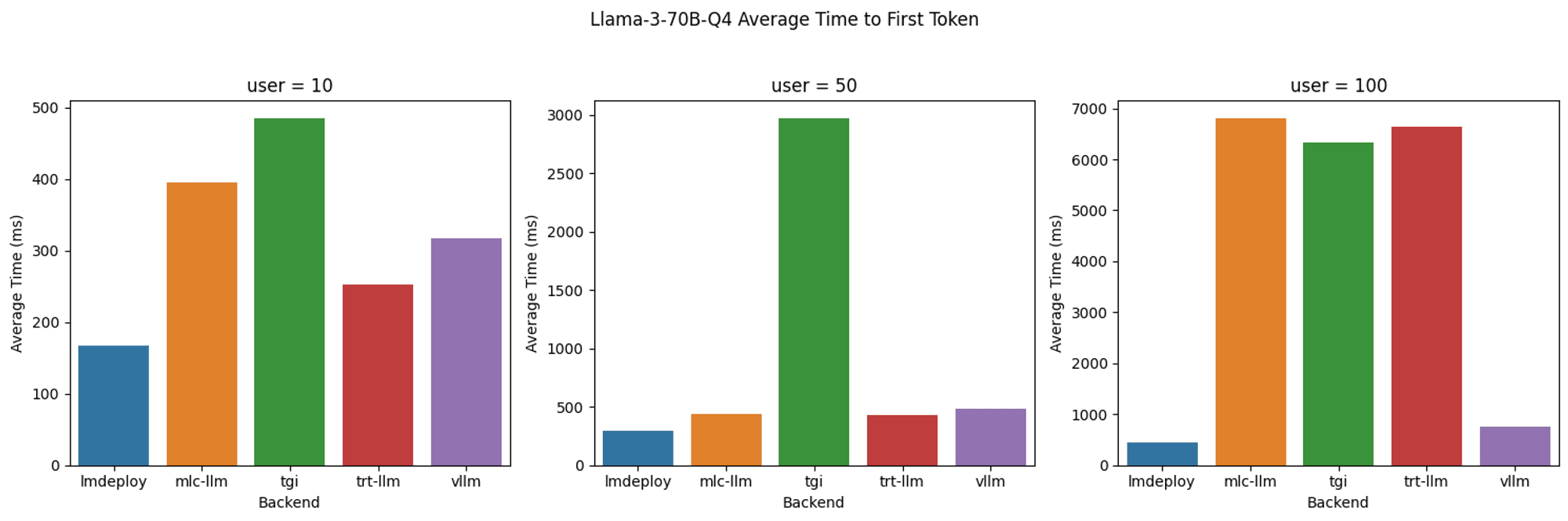
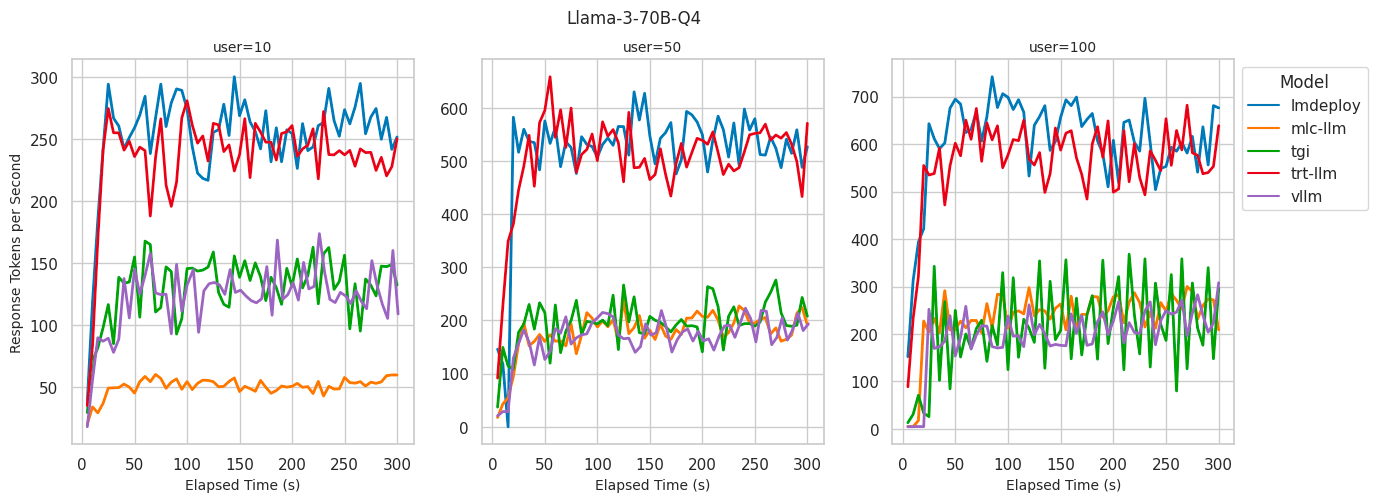
- LMDeploy: Delivered the best token generation rate with up to 700 tokens when serving 100 users while keeping the lowest TTFT across all levels of concurrent users.
- TensorRT-LLM: Exhibited similar performance to LMDeploy in terms of token generation rate and maintained low TTFT at a low concurrent user count. However, TTFT increased significantly to over 6 seconds when concurrent users reach 100.
- vLLM: Demonstrated consistently low TTFT across all levels of concurrent users, similar to what we observed with the 8B model. Exhibited a lower token generation rate compared to LMDeploy and TensorRT-LLM, likely due to a lack of inference optimization for quantized models.
We discovered that the token generation rate is strongly correlated with the GPU utilization achieved by an inference backend. Backends capable of maintaining a high token generation rate also exhibited GPU utilization rates approaching 100%. Conversely, backends with lower GPU utilization rates appeared to be bottlenecked by the Python process.
Beyond performance#
When choosing an inference backend for serving LLMs, considerations beyond just performance also play an important role in the decision. The following list highlights key dimensions that we believe are important to consider when selecting the ideal inference backend.
| LMDeploy | TensorRT-LLM | vLLM | MLC-LLM | TGI | |
|---|---|---|---|---|---|
| Quantization | Supports 4-bit AWQ, 8-bit quantization, and 4-bit KV quantization. | Supports quantization via modelopt, and note that quantized data types are not implemented for all the models. | Users need to quantize models with AutoAWQ or find pre-quantized models on HF. Performance is under-optimized. | Supports 3-bit and 4-bit group quantization. AWQ quantization support is still experimental. | Supports AWQ, GPTQ, and bits-and-bytes quantization. |
| Models | About 20 models supported by TurboMind engine. | 30+ models supported | 30+ models supported | 20+ models supported | 20+ models supported |
| Hardware limitations | Only optimized for Nvidia CUDA | Only supports Nvidia CUDA | Nvidia CUDA, AMD ROCm, AWS Neuron, CPU | Nvidia CUDA, AMD ROCm, Metal, Android, IOS, WebGPU | Nvidia CUDA, AMD ROCm, Intel Gaudi, AWS Inferentia |
Developer experience#
A user-friendly backend should provide rapid development and high code maintainability for AI applications running on top of LLMs.
-
Stable releases: LMDeploy, TensorRT-LLM, vLLM, and TGI all offer stable releases. MLC-LLM does not currently have stable tagged releases, with only nightly builds; one possible solution is to build from source.
-
Model compilation: TensorRT-LLM and MLC-LLM require an explicit model compilation step, which could potentially introduce additional cold-start delay during deployment.
-
Documentation:
- LMDeploy, vLLM, and TGI were all easy to learn with their comprehensive documentation and examples.
- MLC-LLM presented a moderate learning curve, primarily due to the necessity of understanding the model compilation steps.
- TensorRT-LLM was the most challenging to set up in our benchmark test. Without enough quality examples, we had to read through the documentation of TensorRT-LLM, tensorrtllm_backend and Triton Inference Server, convert the checkpoints, build the TRT engine, and write a lot of configurations.
Concepts#
Llama 3#
Llama 3 is the latest iteration in the Llama LLM series, available in various configurations. We used the following model sizes in our benchmark tests.
- 8B: This model has 8 billion parameters, making it powerful yet manageable in terms of computational resources. Using FP16, it requires about 16GB of RAM (excluding KV cache and other overheads), fitting on a single A100-80G GPU instance.
- 70B 4-bit Quantization: This 70 billion parameter model, when quantized to 4 bits, significantly reduces its memory footprint. Quantization compresses the model by reducing the bits per parameter, providing faster inference and lowering memory usage with minimal performance loss. With 4-bit AWQ quantization, it requires approximately 37GB of RAM for loading model weights, fitting on a single A100-80G instance. Serving quantized weights on a single GPU device typically achieves the best throughput of a model compared to serving on multiple devices.
BentoML and BentoCloud#
- BentoML: A unified model serving framework that allows developers to build model inference APIs and multi-model serving systems with any open-source or custom AI models. Developers can package all the dependencies, runtime configurations and models into a self-contained unit called Bento.
- BentoCloud: An AI Inference Platform for enterprise AI teams, offering fully-managed infrastructure tailored for model inference. Developers use it together with BentoML to deploy AI models in a scalable and secure way, with advanced features like autoscaling, built-in observability, and multi-model orchestration.
We ensured that the inference backends served with BentoML added only minimal performance overhead compared to serving natively in Python. The overhead is due to the provision of functionality for scaling, observability, and IO serialization. Using BentoML and BentoCloud gave us a consistent RESTful API for the different inference backends, simplifying benchmark setup and operations.
Inference backends#
Different backends provide various ways to serve LLMs, each with unique features and optimization techniques. All of the inference backends we tested are under Apache 2.0 License.
- LMDeploy: An inference backend focusing on delivering high decoding speed and efficient handling of concurrent requests. It supports various quantization techniques, making it suitable for deploying large models with reduced memory requirements.
- vLLM: A high-performance inference engine optimized for serving LLMs. It is known for its efficient use of GPU resources and fast decoding capabilities.
- TensorRT-LLM: An inference backend that leverages NVIDIA's TensorRT, a high-performance deep learning inference library. It is optimized for running large models on NVIDIA GPUs, providing fast inference and support for advanced optimizations like quantization.
- Hugging Face Text Generation Inference (TGI): A toolkit for deploying and serving LLMs. It is used in production at Hugging Face to power Hugging Chat, the Inference API and Inference Endpoint.
- MLC-LLM: An ML compiler and high-performance deployment engine for LLMs. It is built on top of Apache TVM and requires compilation and weight conversion before serving models.
Integrating BentoML with various inference backends to self-host LLMs is straightforward. The BentoML community provides the following example projects on GitHub to guide you through the process.
- BentoVLLM: https://github.com/bentoml/BentoVLLM
- BentoMLCLLM: https://github.com/bentoml/BentoMLCLLM
- BentoLMDeploy: https://github.com/bentoml/BentoLMDeploy
- BentoTRTLLM: https://github.com/bentoml/BentoTRTLLM
- BentoTGI: https://github.com/bentoml/BentoTGI
Benchmark setup#
We set up the testbed as follows.
Models#
We tested both the Meta-Llama-3-8B-Instruct and Meta-Llama-3-70B-Instruct 4-bit quantization models. For the 70B model, we performed 4-bit quantization so that it could run on a single A100-80G GPU. If the inference backend supports native quantization, we used the inference backend-provided quantization method. For example, for MLC-LLM, we used the q4f16_1 quantization scheme. Otherwise, we used the AWQ-quantized casperhansen/llama-3-70b-instruct-awq model from Hugging Face.
Note that other than enabling common inference optimization techniques, such as continuous batching, flash attention, and prefix caching, we did not fine-tune the inference configurations (GPU memory utilization, max number of sequences, paged KV cache block size, etc.) for each individual backend. This is because this approach is not scalable as the number of LLMs we serve gets larger. Providing an optimal set of inference parameters is an implicit measure of performance and ease-of-use of the backends.
Benchmark client#
To accurately assess the performance of different LLM backends, we created a custom benchmark script. This script simulates real-world scenarios by varying user loads and sending generation requests under different levels of concurrency.
Our benchmark client can spawn up to the target number of users within 20 seconds, after which it stress tests the LLM backend by sending concurrent generation requests with randomly selected prompts. We tested with 10, 50, and 100 concurrent users to evaluate the system under varying loads.
Each stress test ran for 5 minutes, during which time we collected inference metrics every 5 seconds. This duration was sufficient to observe potential performance degradation, resource utilization bottlenecks, or other issues that might not be evident in shorter tests.
For more information, see the source code of our benchmark client.
Prompt dataset#
The prompts for our tests were derived from the databricks-dolly-15k dataset. For each test session, we randomly selected prompts from this dataset. We also tested text generation with and without system prompts. Some backends might have additional optimizations regarding common system prompt scenarios by enabling prefix caching.
Library versions#
- BentoML: 1.2.16
- vLLM: 0.4.2
- MLC-LLM: mlc-llm-nightly-cu121 0.1.dev1251 (No stable release as of this writing)
- LMDeploy: 0.4.0
- TensorRT-LLM: 0.9.0 (with Triton v24.04)
- TGI: 2.0.4
Recommendations#
The field of LLM inference optimization is rapidly evolving and heavily researched. The best inference backend available today might quickly be surpassed by newcomers. Based on our benchmarks and usability studies conducted at the time of writing, we have the following recommendations for selecting the most suitable backend for Llama 3 models under various scenarios.
Llama 3 8B#
For the Llama 3 8B model, LMDeploy consistently delivers low TTFT and the highest decoding speed across all user loads. Its ease of use is another significant advantage, as it can convert the model into TurboMind engine format on the fly, simplifying the deployment process. At the time of writing, LMDeploy offers limited support for models that utilize sliding window attention mechanisms, such as Mistral and Qwen 1.5.
vLLM consistently maintains a low TTFT, even as user loads increase, making it suitable for scenarios where maintaining low latency is crucial. vLLM offers easy integration, extensive model support, and broad hardware compatibility, all backed by a robust open-source community.
MLC-LLM offers the lowest TTFT and maintains high decoding speeds at lower concurrent users. However, under very high user loads, MLC-LLM struggles to maintain top-tier decoding performance. Despite these challenges, MLC-LLM shows significant potential with its machine learning compilation technology. Addressing these performance issues and implementing a stable release could greatly enhance its effectiveness.
Llama 3 70B 4-bit quantization#
For the Llama 3 70B Q4 model, LMDeploy demonstrates impressive performance with the lowest TTFT across all user loads. It also maintains a high decoding speed, making it ideal for applications where both low latency and high throughput are essential. LMDeploy also stands out for its ease of use, as it can quickly convert models without the need for extensive setup or compilation, making it ideal for rapid deployment scenarios.
TensorRT-LLM matches LMDeploy in throughput, yet it exhibits less optimal latency for TTFT under high user load scenarios. Backed by Nvidia, we anticipate these gaps will be quickly addressed. However, its inherent requirement for model compilation and reliance on Nvidia CUDA GPUs are intentional design choices that may pose limitations during deployment.
vLLM manages to maintain a low TTFT even as user loads increase, and its ease of use can be a significant advantage for many users. However, at the time of writing, the backend's lack of optimization for AWQ quantization leads to less than optimal decoding performance for quantized models.
More resources#
We hope this benchmark will be helpful to developers when choosing the ideal inference backend. In our benchmarking process, BentoML and BentoCloud played an important role, allowing us to easily integrate different backends with Llama 3 and focus on performance assessment. If you have any questions about using them or self-serving LLMs, check out the following resources and don’t hesitate to contact us.
- LLM performance benchmarks
- Choose the right NVIDIA or AMD GPUs for your LLM
- Join our community forum
- Schedule a call with our experts
- Sign up for our inference platform and deploy the latest LLMs with just a few clicks