BentoML: Past and Present
November 9, 2023 • Written By Eric Liu
How things started#
Back in 2015 and 2016, our CEO and co-founder of BentoML, Chaoyu Yang, was an early Databricks engineer and the first part-time PM of the MLflow project. While assisting clients such as Riot Games and Capital One, he recognized the challenges in taking machine learning models to production. The process was fraught with conflicts due to the involvement of various personas: data engineers, data scientists, ML engineers, DevOps engineers, and product managers.
For example, before data scientists could train models, data engineers might need to clean the data; after training the models, data scientists needed to ask the ML engineers to take the models into a callable web service API. The ML engineers also needed to talk to DevOps engineers to make sure the service was reliable and scalable. At the same time, the PM wanted to access the data of the machine learning services.
The evolution of machine learning wasn't just about the code; it also involved data and models, making the CI/CD process complex. This led to the emergence of a new concept back then: MLOps. This concept was designed to make sure the machine learning assets are treated as other software assets, like code within a CI/CD environment. This required us to make ML assets versionable and testable with an automated and reproducible process in place to leverage these assets.
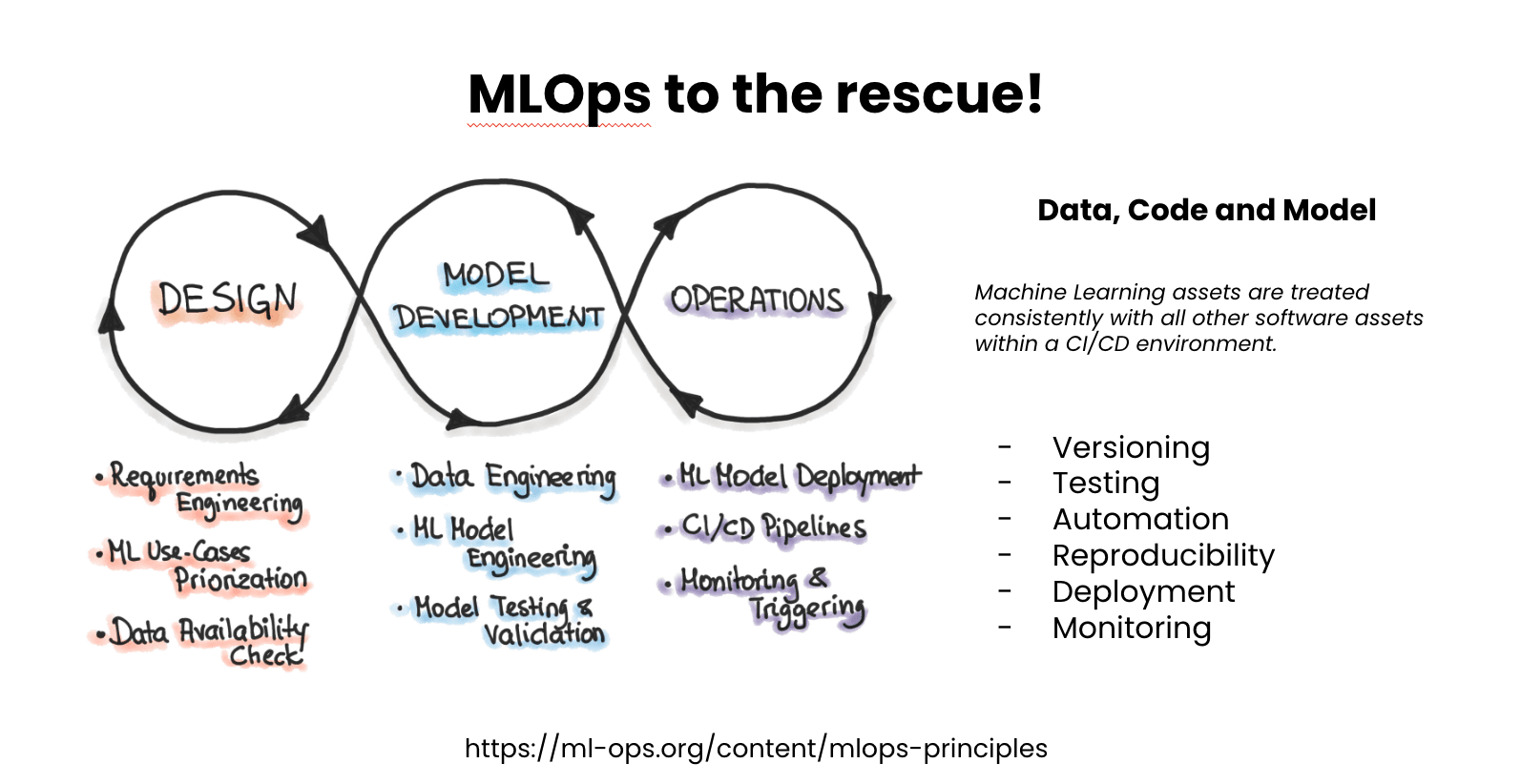
Developing BentoML: Off-the-shell, in-house, and the dream#
When we started BentoML, we interviewed different users deploying various solutions. Each company had its own implementation, which we categorized based on two dimensions: ease of use and flexibility.
Off-the-shelf solutions#
In terms of ease of use, the most direct solution came from ML training frameworks. For example, TensorFlow offers TensorFlow Serve, PyTorch comes with Torch Serve, and NVIDIA provides the Triton Inference Server. The key advantage of such off-the-shelf solutions is their simplicity, allowing data scientists to quickly get started for simple use cases. Specialized runtimes also ensure low-latency serving, especially tailored to specific frameworks.
However, as ML organizations expand, the limitations of these solutions become evident:
- Framework specific and configuration bound: These solutions are specific to frameworks and you might find yourself stuck with their configurations. This means they might not be applicable to certain ML use cases.
- Inflexible for customizing inference logic: Off-the-shelf solutions may not allow for intricate inference logic modifications or seamless integration with other training frameworks.
- Limited multi-model inference: They might not support multiple models working in tandem, especially when scaling.
In-house solutions#
Our investigation revealed a trend: many technology-driven companies with strong engineering teams might develop their in-house solutions. Such solutions offer high flexibility, adapting not just to different frameworks but also aligning with the company’s specific infrastructure. Nevertheless, not every enterprise, especially those non-tech ones, have the required engineering resources or expertise. Building such infrastructure could cost 6 to 9 months, which means lost opportunities and revenue.
Moreover, many ML organizations begin with data teams comprising data engineers and data scientists. Due to the skill gap, most data scientists, with their backgrounds in statistics or mathematics, need considerable time to acquire the necessary DevOps or engineering expertise.
The dream#
Our solution emerged from these insights. At that time, we envisioned a framework balancing flexibility with user-friendliness.
- Python-centric. Python, we believe, offers a more intuitive progression for data scientists moving from training to inference than declarative YAMLs.
- Optimized runtimes and hardware scheduling. Our goal was to ensure auto-scalability, supporting different ML frameworks across varied deployment environments.
- Environment-agnostic. Deployment should be simplified and seamless, whether on-cloud, on-premises, or in containerized environments like Kubernetes.
- Cost efficiency. An ideal solution should be not only efficient but also economically viable, ensuring companies can scale based on their actual needs.
BentoML#
BentoML, our open-source AI application framework, is the realization of this vision with the following highlighted features.
- Diverse framework support. It supports a vast array of data science libraries and ML frameworks, making it ideal even for large teams with different ML requirements, be it PyTorch, SK-learn, or Transformers.
- Flexible service API. BentoML offers support for both REST APIs and gRPC. You can easily implement pre/post processing logic and data validation into its API Servers.
- Distributed Runner architecture. BentoML API Servers route traffic to an abstraction called Runners to run model inference. Separating API Servers and Runners means you can run them on different hardware settings based on their resource requirements (for example, API Servers on CPU and Runners on GPU) and scale them independently. Runners are designed to accommodate various runtimes, such as ONNX and NVIDIA Triton.
- Deployment flexibility. BentoML's standardized format, the Bento, encapsulates source code, configurations, models, and environment packages. This artifact can be containerized and deployed anywhere.
Today, with over 3000 community members, BentoML serves billions of predictions daily, empowering over 1000 organizations in production. Here's what our users share:
"BentoML enables us to deliver business value quickly by allowing us to deploy ML models to our existing infrastructure and scale the model services easily." - Shihgian Lee, Senior Machine Learning Engineer, Porch
"We achieved big speedups migrating from FastAPI to BentoML recently, 5-10x with some very basic tuning." - Axel Goblet, Machine Learning Engineer, BigData Republic
"BentoML 1.0 is helping us future-proof our ML deployment infrastructure at Mission Lane. It is enabling us to rapidly develop and test our model scoring services, and to seamlessly deploy them into our dev, staging, and production Kubernetes clusters." - Mike Kuhlen, Data Science & ML Lead, Mission Lane
A case study: Why and How NAVER uses BentoML#
When expanding into the Asian market, particularly with the open-source community, having a champion in the region is vital. A prime example is Sungjun Kim, a software engineer from LINE. In 2019, Mr. Kim came across BentoML and began implementing it to build what they called the "ML universe" within LINE. A year later, BentoML had been integrated into at least three use cases (shopping-related search, content recommendations, and user targeting) within the LINE application and its associated organizations. Later on, we found that another individual, Woongkyu Lee from LINE (though not from the same division as Mr. Kim, given LINE's vast organizational structure) also adopted BentoML with their machine learning team, mainly to calculate credit scores.
The popularity of BentoML continued to grow, particularly in South Korea, attracting a large number of internet companies, including the tech giant, NAVER.
About NAVER#
Founded in 1999, NAVER stands as South Korea's largest search engine and is the country's most frequented website. Globally, NAVER boasts over 6,000 employees, with over half of them based in its headquarters in Seongnam, South Korea. In 2020, NAVER generated revenues surpassing 5.5 trillion Korean won (approximately US$4.8 billion), making it the largest internet company in Korea by market capitalization.
At NAVER, each team selects their own framework based on their specific needs. SoungRyoul Kim, an MLOps engineer at the AI Serving Dev team of NAVER, shares their story of how and why they use BentoML.
Why BentoML?#
Kim’s team selects BentoML for the following reasons:
-
Simplicity. Kim’s team follows the standard BentoML workflow to build a Bento and containerize it to create a Docker image. This process only takes them a handful of commands like
bentoml buildandbentoml containerize. After that, they can easily retrieve the Docker image to deploy their AI application anywhere. -
Inference flexibility. BentoML Runners can work in either distributed or embedded mode.
- Distributed Runners. Typically, ML serving supports multi-threading for model inference. Compared with tools like FastAPI, which is a web framework and does not support multi-threading, BentoML Runners can run model inference as single processes and communicate with API Servers to handle multiple requests concurrently. See Resource scheduling strategy for details.
- Embedded Runners. In some cases, Kim’s team need to run inference on lightweight models. By setting
.to_runner(embedded=True), they run the API Server and the Runner within the same process, reducing the communication overhead and achieving better performance. See Embedded Runners for more information.
How does NAVER use BentoML?#
One of their use cases is running distributed Runners for online serving. In this scenario, Kim’s team spawn two identical Runners and then distribute inference requests to both Runners. “In a Kubernetes environment where each Runner is deployed independently, this approach can efficiently improve the performance of the model server, especially useful for inference requests with a large batch size,” Kim explains.
The image below is a simple example of using two distributed Runners. Each of them handles 100 rows when the size is 200. To further reduce latency, you can spawn more Runners to handle inference requests. “When you use this strategy, there is only few code changes,” Kim says.
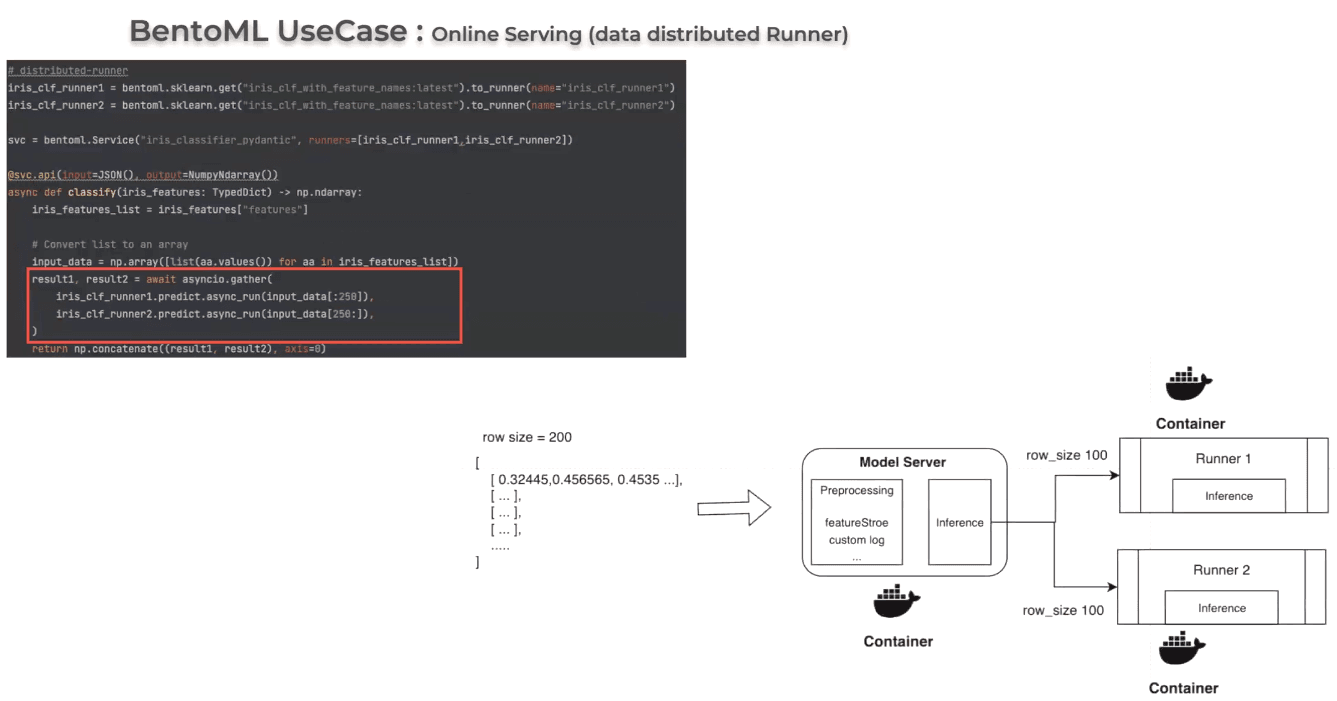
For Kim’s team, BentoML is more than a unified model serving framework. It also allows them to implement preprocessing logic. In practical ML serving scenarios, incoming inference requests often don't contain data in an ideal format. The raw data is rarely a neatly packaged tensor ready for the model. This means you often need to preprocess the data before it can be fed into the model for inference.
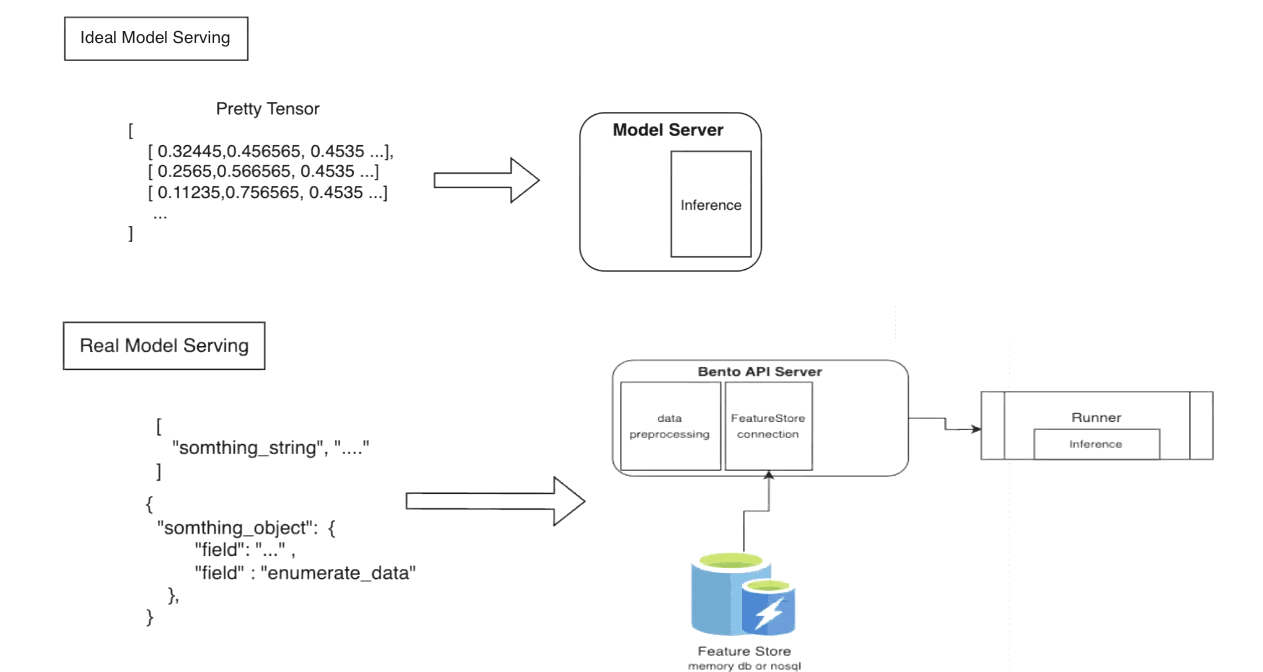
In this connection, BentoML provides an easy way to implement pre-processing logic in the Service with Python. “We need to add preprocessing logic and Feature Store connections. In this case, you may need FastAPI and other server tools with pre-processing logic, but BentoML supports this,” Kim says.
We believe that an ideal solution for production model serving should have optimized runtimes and hardware scheduling, which allows for independent and automatic scaling. This is why we created the Runner architecture.
Conclusion#
Reflecting on BentoML's journey from its inception to its current standing is a testament to the power of community-driven development and the necessity for a robust, flexible ML serving solution. Today, we are glad to see significant contributions from adopters like LINE and NAVER who not only utilize the framework but also enrich it.
This year, we've continued to push the boundaries of what the BentoML ecosystem can do. With OpenLLM, users can serve and deploy any large language model with ease and efficiency. OneDiffusion allows us to tackle the challenges of deploying Stable Diffusion models in production. Moreover, the launch of BentoCloud marks a significant milestone, offering a serverless platform tailored for AI application production deployment.
We invite practitioners, enthusiasts, and organizations to join our thriving community, shaping the future of MLOps. Let's build, share, and innovate together.
More on BentoML#
To learn more about BentoML and its ecosytem tools, check out the following resources:
- [Blog] Deploying Code Llama in Production with OpenLLM and BentoCloud
- [Blog] From Models to Market: What's the Missing Link in Scaling Open-Source Models on Cloud?
- [Blog] BYOC to BentoCloud: Privacy, Flexibility, and Cost Efficiency in One Package
- Don’t miss out on the chance to be an early adopter! BentoCloud is still open for early sign-ups. Experience a serverless platform tailored to simplify the building and management of your AI applications, ensuring both ease of use and scalability.