Building A Multi-Agent System with CrewAI and BentoML
Authors

Last Updated
Share

Imagine you’re a manager who needs a report on the latest trends in AI agents. You might ask a researcher to dig into relevant sources, then hand it off to a data analyst to sift through findings and compile them into a report. Now, imagine both roles could be fulfilled by AI-powered agents.
This is what we mean by a multi-agent system: a group of AI agents, each with unique roles, collaborating to tackle complex projects.
In this blog post, we’ll walk you through how to build a multi-agent system with CrewAI and BentoML. It automates research and reporting tasks, from gathering insights to delivering structured reports. You can use open-source LLMs or proprietary ones to power the agents; we’ll show you examples of both.
We’ll deploy the entire project to BentoCloud, an AI inference platform for deploying and scaling AI models in production. It provides fast and scalable infrastructure for model inference and complicated AI applications.
You can explore the full code here on GitHub.
Architecture#
Let’s first take a look at the architecture:
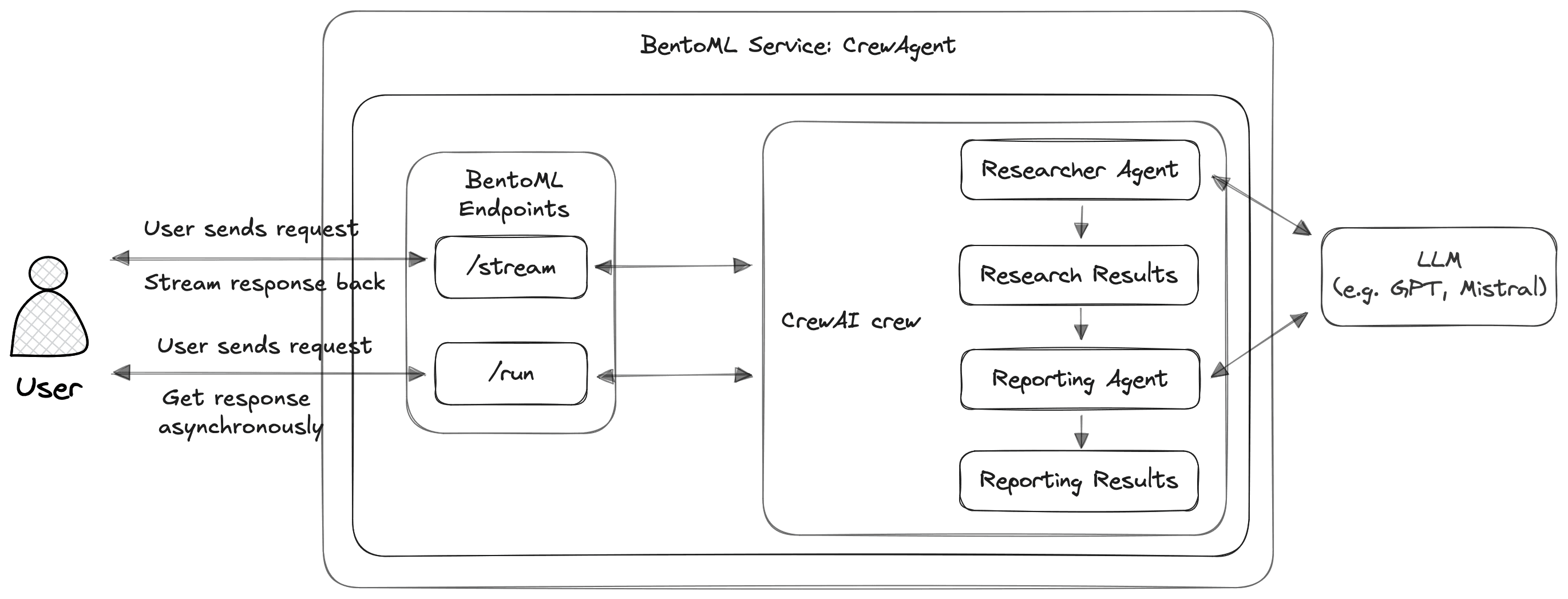
In this project, we define two CrewAI agents, powered by a pre-defined LLM.
- Senior Data Researcher: Gathers information about a specific topic.
- Reporting Analyst: Creates detailed reports from research findings.
When the user sends a request about a topic to a BentoML Service endpoint, the CrewAI workflow begins. First, the Researcher agent performs research on the topic. The Reporting Analyst then creates a detailed report from the research. Lastly, BentoML sends it back to the user.
BentoML exposes two API endpoints in this project:
/stream: A streaming endpoint that shows real-time progress including planning and thinking processes./run: A task endpoint that supports long-running workloads. BentoML tasks ares ideal for workflows that take time to complete, as they allow the system to execute tasks in the background. The user can retrieve the results asynchronously once the task is done.
Explore the code#
Let’s check out the key code implementations in this project.
agents.yaml#
In CrewAI, the agents.yaml file defines the roles and responsibilities of the agents in our multi-agent system. The {topic} placeholder allows the agents to adapt their tasks to each user’s request.
researcher: role: > {topic} Senior Data Researcher goal: > Uncover cutting-edge developments in {topic} backstory: > You're a seasoned researcher with a knack for uncovering the latest developments in {topic}. Known for your ability to find the most relevant information and present it in a clear and concise manner. # llm: mistral reporting_analyst: role: > {topic} Reporting Analyst goal: > Create detailed reports based on {topic} data analysis and research findings backstory: > You're a meticulous analyst with a keen eye for detail. You're known for your ability to turn complex data into clear and concise reports, making it easy for others to understand and act on the information you provide. # llm: mistral
By default, CrewAI uses the gpt-4o-mini model. To switch to open-source LLMs, set the llm parameter. This project uses Mistral 7B as an example.
tasks.yaml#
The tasks.yaml file maps tasks to specific agents. Each task has a description, expected output, and an assigned agent. You can customize it as needed.
research_task: description: > Conduct a thorough research about {topic} Make sure you find any interesting and relevant information given the current year is 2024. expected_output: > A list with 10 bullet points of the most relevant information about {topic} agent: researcher reporting_task: description: > Review the context you got and expand each topic into a full section for a report. Make sure the report is detailed and contains any and all relevant information. expected_output: > A fully fledge reports with the mains topics, each with a full section of information. Formatted as markdown without '```' agent: reporting_analyst
crew.py#
The crew.py file brings everything together. It uses CrewAI to define agents, tasks, and the workflow that ties them into a multi-agent system.
... @CrewBase class BentoCrewDemoCrew(): """BentoCrewDemo crew""" @agent def researcher(self) -> Agent: return Agent( config=self.agents_config['researcher'], # tools=[MyCustomTool()], # Example of custom tool, loaded on the beginning of file verbose=True ) @agent def reporting_analyst(self) -> Agent: return Agent( config=self.agents_config['reporting_analyst'], verbose=True ) @task def research_task(self) -> Task: return Task( config=self.tasks_config['research_task'], ) @task def reporting_task(self) -> Task: return Task( config=self.tasks_config['reporting_task'], output_file='report.md' ) @crew def crew(self) -> Crew: """Creates the BentoCrewDemo crew""" return Crew( agents=self.agents, # Automatically created by the @agent decorator tasks=self.tasks, # Automatically created by the @task decorator process=Process.sequential, verbose=True, # process=Process.hierarchical, # In case you wanna use that instead https://docs.crewai.com/how-to/Hierarchical/ )
To use an open-source LLM to power your agent, add a code block like this.
# Uncomment the code below for using private deployed open-source LLM @llm def mistral(self) -> LLM: model_name="TheBloke/Mistral-7B-Instruct-v0.1-AWQ" return LLM( # add `openai/` prefix to model so litellm knows this is an openai # compatible endpoint and route to use OpenAI API Client model=f"openai/{model_name}", api_key="na", base_url="<deployment_url_on_bentocloud>/v1" )
Note that Mistral 7B is deployed separately on BentoCloud in this example. We recommend you use OpenLLM to run it on BentoCloud for fast and efficient private LLM deployment. It provides OpenAI-compatible APIs so that it can be easily integrated in the CrewAI pipeline.
Use the following commands to deploy it, then obtain the exposed URL on BentoCloud.
# Install libraries pip install -U openllm bentoml openllm repo update # Login/Signup BentoCloud bentoml cloud login # Deploy mistral 7B openllm deploy mistral:7b-4bit --instance-type gpu.t4.1.8x32
service.py#
The service.py file is where you wrap the multi-agent logic into the BentoML framework. It exposes it through two API endpoints accessible to external requests.
First, use the @bentoml.service decorator to mark the CrewAgent class as a BentoML Service. This decorator allows you to configure the server, such as workers and resource allocations on BentoCloud.
@bentoml.service( workers=1, resources={ "cpu": "2000m" # BentoCloud automatically assigns an instance with the required resources }, traffic={ "concurrency": 16, # The number of concurrent requests "external_queue": True # Enable an external queue to handle excess requests } ) class CrewAgent:
For this example, we recommend you set concurrency and enable external_queue. The configurations above mean if the application receives more than 16 requests simultaneously, the extra requests are placed in an external queue. They will be processed once the current ones are completed, allowing you to handle traffic spikes without dropping requests.
Then, define the two endpoints as we mentioned in the Architecture section.
/run: In BentoML, you create a task endpoint with the@bentoml.taskdecorator. This endpoint initiates the workflow by callingBentoCrewDemoCrew().crew()and performs the tasks defined within CrewAI sequentially./stream: A streaming endpoint, marked by@bentoml.api, which continuously returns real-time logs and intermediate results to the client.
from bento_crew_demo.crew import BentoCrewDemoCrew class CrewAgent: @bentoml.task def run(self, topic: str = Field(default="LLM Agent")) -> str: # Initialize the crew workflow with the specified topic return BentoCrewDemoCrew().crew().kickoff(inputs={"topic": topic}).raw # Streams the full Crew output to the client, including all intermediate steps. @bentoml.api async def stream( self, topic: str = Field(default="LLM Agent") ) -> AsyncGenerator[str, None]: # Create a pipe for inter-process communication read_fd, write_fd = os.pipe() async def kickoff(): with os.fdopen(write_fd, "w", buffering=1) as write_file: with redirect_stdout(write_file): # Launch the Crew process asynchronously, passing the specified topic as input await BentoCrewDemoCrew().crew().kickoff_async( inputs={"topic": topic} ) asyncio.create_task(kickoff()) # Continuously read from the pipe and yield each line, providing real-time output to the client async with aiofiles.open(read_fd, mode='r') as read_file: async for line in read_file: if not line: break yield line
For details, check out the full source code.
Cloud deployment#
Now let’s try deploying this project to the cloud.
-
Clone the project repository.
git clone https://github.com/bentoml/BentoCrewAI.git cd BentoCrewAI/src -
We recommend you create a virtual environment.
# Recommend Python 3.11 for this project python -m venv bento-crewai source ./bento-crewai/bin/activate # Install dependencies pip install -r requirements.txt --no-deps -
Optionally, if you want to quickly validate the code locally, run the following command and the server will be available at
http://localhost:3000/.# Set your OpenAI key first if you use GPT as the LLM # export OPENAI_API_KEY='your_openai_key' bentoml serve . -
Log in to BentoCloud. If you don’t already have a BentoCloud account, sign up here. Feel free to skip this step if you are already logged in.
bentoml cloud login -
Choose one of the following depending on the LLM you use:
-
For an open-source model like Mistral, simply run
bentoml deploy. Use-nto customize the name and scaling flags to set allowed replica counts.bentoml deploy . -n crewai-demo --scaling-min 0 --scaling-max 3 -
For the default GPT model, create a BentoCloud secret to store your API key and reference it when deploying the project.
bentoml secret create openai OPENAI_API_KEY='your_openai_key' bentoml deploy . --secret openai -n crewai-demo --scaling-min 0 --scaling-max 3
-
-
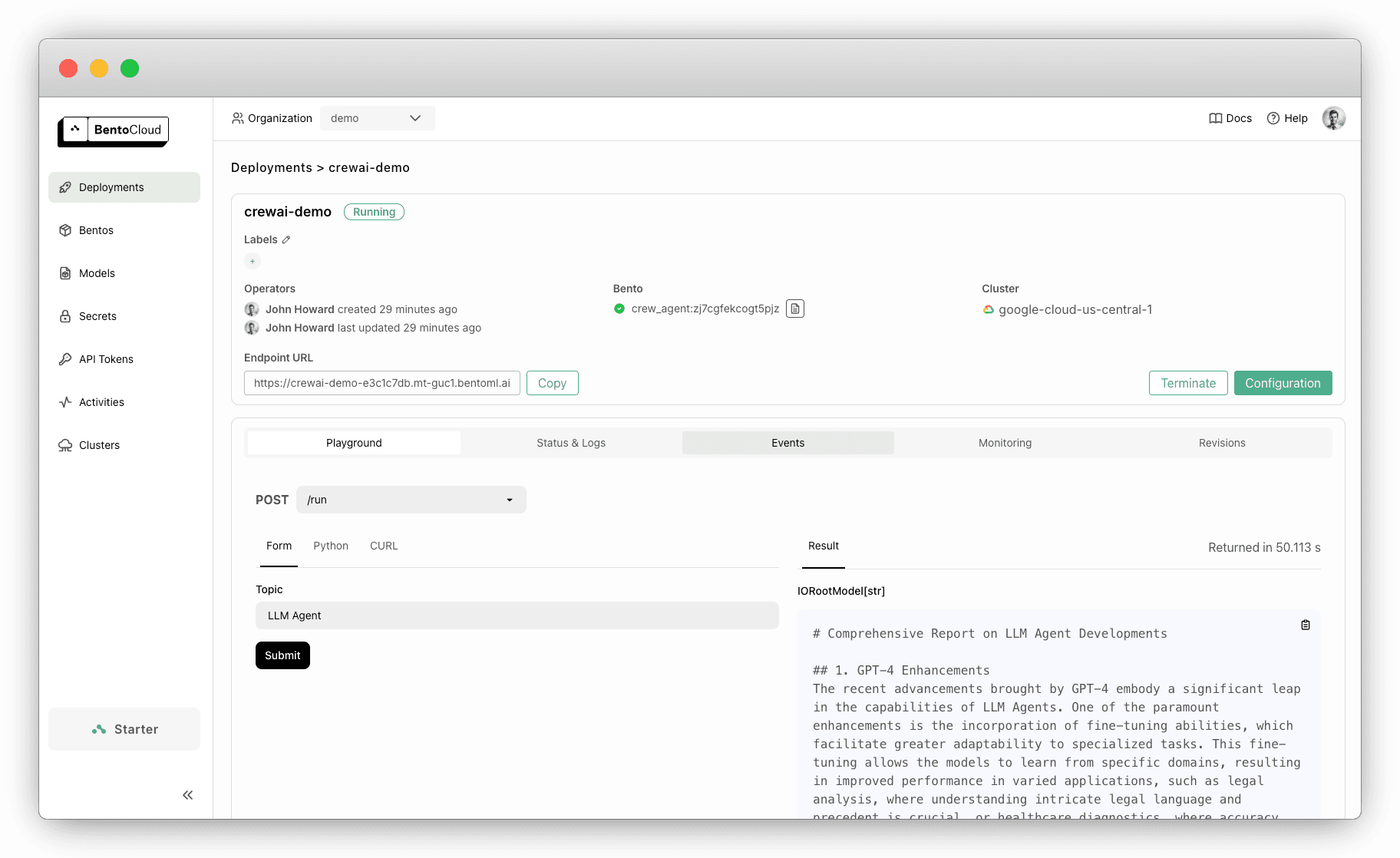
Visit the Deployment details page on the BentoCloud console and run inference with it.
-
You can also send a request to the task endpoint with a Python client. Here is an example and make sure you replace the URL with your own.
import bentoml topic="LLM Agents" client = bentoml.SyncHTTPClient("https://crewai-demo-e3c1c7db.mt-guc1.bentoml.ai") task = client.run.submit(topic=topic)After submitting the query, check the status and retrieve the result at a later time:
status = task.get_status() if status.value == 'success': print("The task runs successfully. The result is", task.get()) elif status.value == 'failure': print("The task run failed.") else: print("The task is still running.")
Conclusion#
By leveraging CrewAI for agent orchestration and BentoML for deployment, we’ve built an adaptable multi-agent system that can dynamically scale to handle real-world demands. This project is designed to be flexible and extendable and we encourage you to customize it. Try using different open-source models, integrating custom tools, or adding more specialized agents to enhance its capabilities.
Check out the following resources to learn more:
- [Doc] More compound AI examples with BentoML
- [Doc] CrewAI documentation
- Sign up for BentoCloud for free to deploy your first multi-agent application
- Join our Slack community
- Contact us if you have any question about deploying multi-agent applications