Building A RAG App with BentoCloud and Milvus Lite
Authors

Last Updated
Share

In this blog post, we will demonstrate how to build a RAG (Retrieval Augmented Generation) app with open-source models deployed on BentoCloud and Milvus Lite. Specifically, we'll use BentoCloud to deploy two AI models:
- all-MiniLM-L6-v2: Generates vector embeddings for our text data.
- Meta-Llama-3-8B-Instruct: Responds to queries about the knowledge base.
Milvus Lite is a lightweight vector database. In this demo, we use it to efficiently store vector embeddings and conduct vector similarity search.
We'll connect to model endpoints on BentoCloud and Milvus Lite using their respective Python libraries (bentoml and pymilvus) to perform model inference, data processing, and vector search.
Concepts#
First, let’s briefly explore the main concepts involved.
BentoCloud#
BentoCloud is an AI Inference Platform for enterprise AI teams, offering fully-managed infrastructure tailored for model inference. Developers use it alongside BentoML, an open-source model serving framework, to build and deploy performant, scalable, and cost-efficient model inference services. See the BentoCloud documentation to learn more.
Milvus Lite#
Milvus Lite is the lightweight version of Milvus, an open-source vector database that powers AI applications with vector embeddings and similarity search. Milvus Lite can be imported into Python apps, providing the core vector search functionality of Milvus. See the Milvus Lite documentation to learn more.
Now, let’s see how to integrate BentoCloud and Milvus Lite for RAG.
Setting up the environment#
First, install the required packages.
pip install -U pymilvus bentoml
We recommend creating a virtual environment for better package management:
python -m venv milvus-bentoml source milvus-bentoml/bin/activate
You can find all the source code for this project here.
Deploying an embedding server with BentoCloud#
BentoCloud provides a variety of state-of-the-art open-source AI models, such as Llama 3, Stable Diffusion, CLIP, and Sentence Transformers. These models are pre-built and can be deployed with a single click on the inference platform.
Sign up for BentoCloud first. After your account is activated, go to the Explore page, and deploy Sentence Transformers (We use all-MiniLM-L6-v2 for embeddings).
Once the Deployment is ready, you can interact with its on the Playground tab.
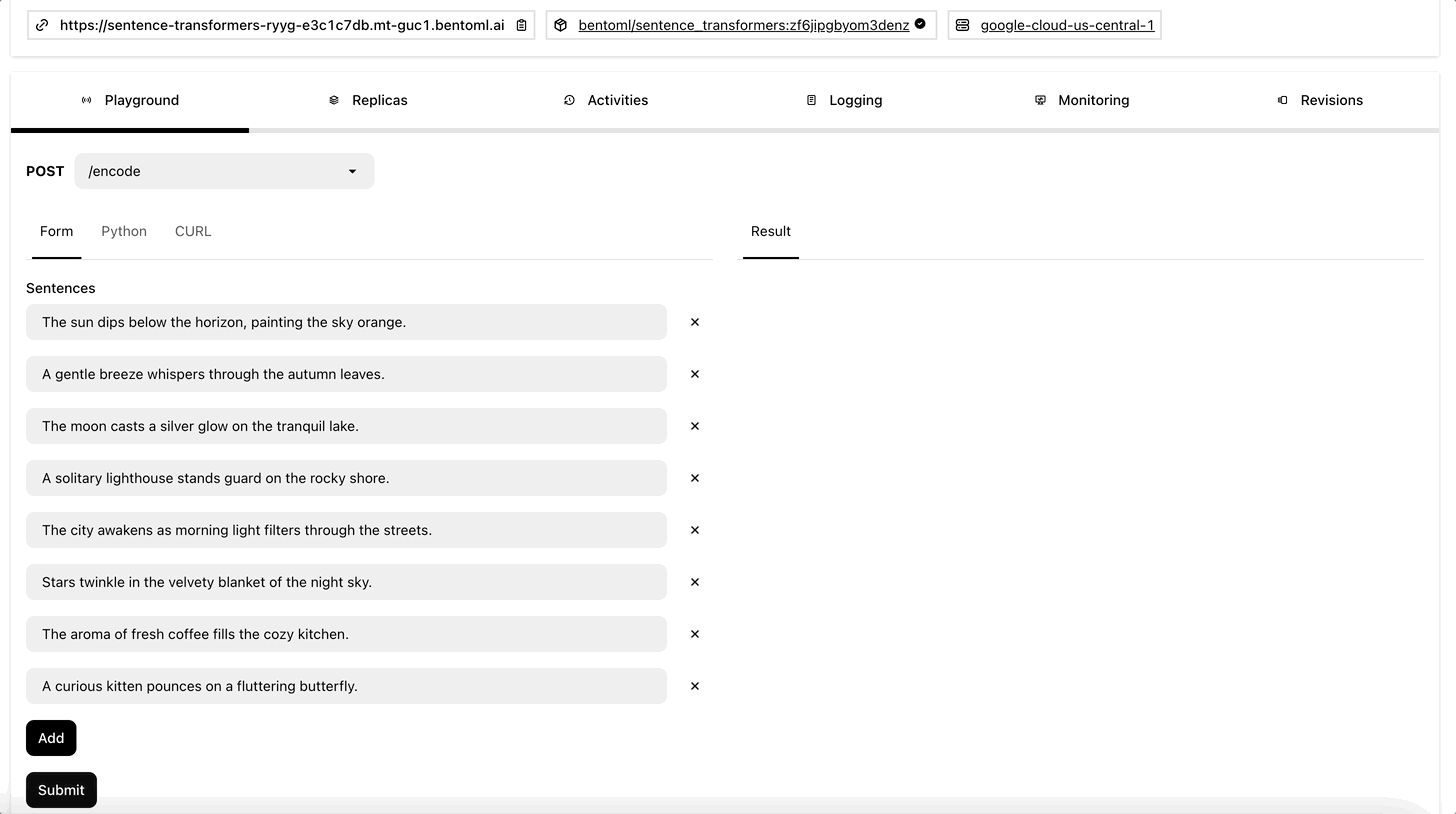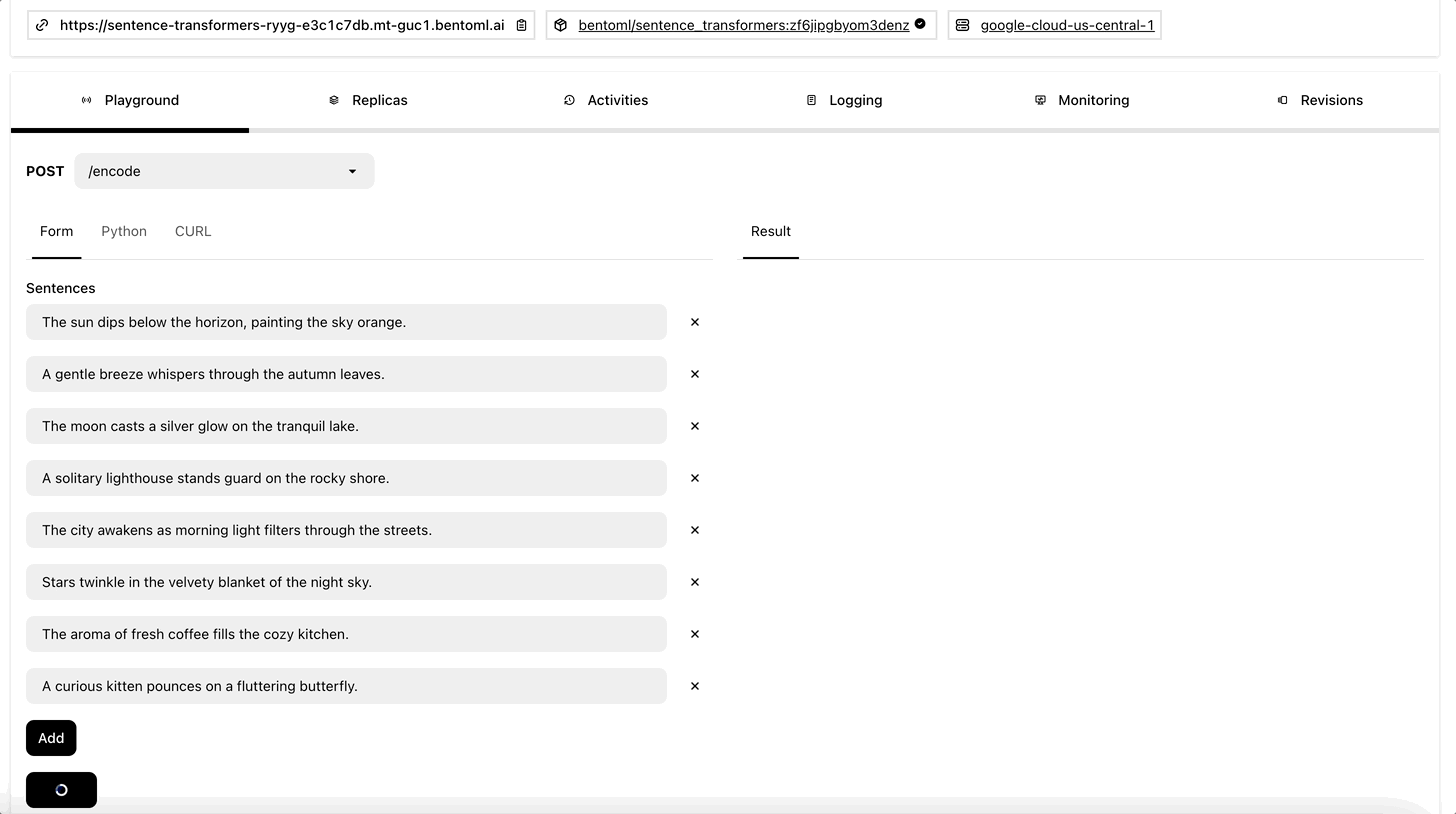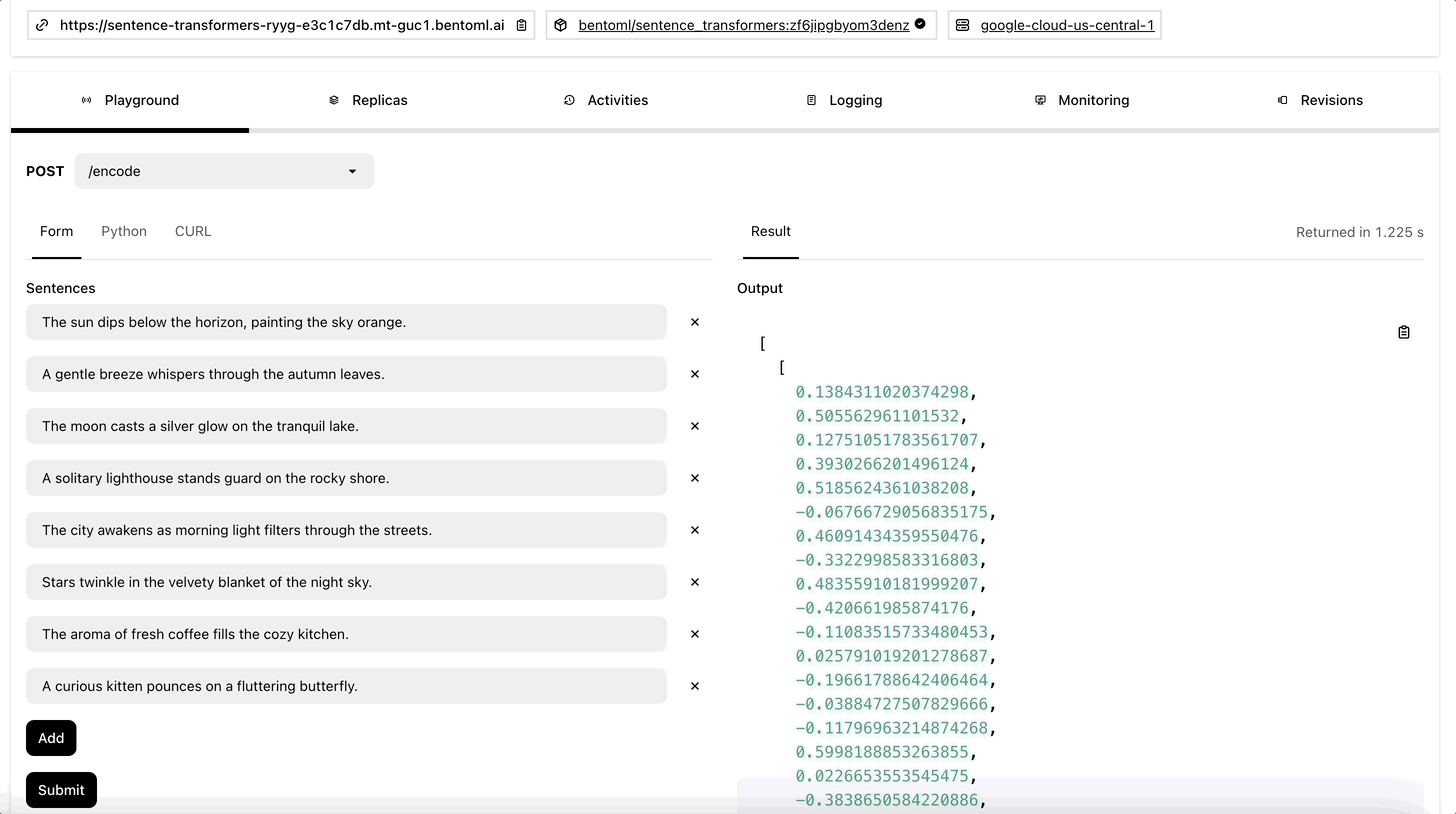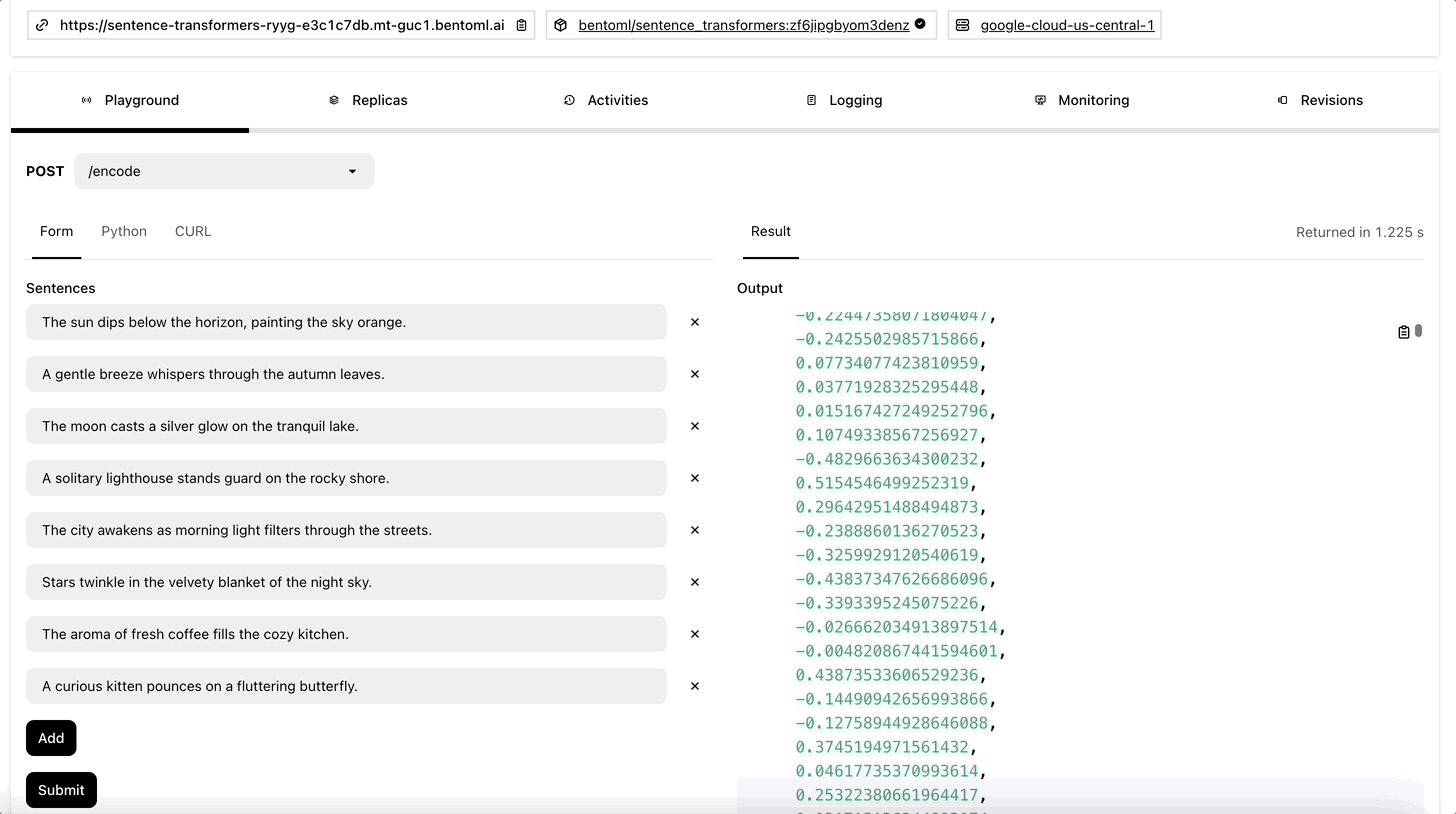
To run inference with it programmatically, create an HTTP client using SyncHTTPClient by specifying the endpoint URL (the link above the Playground tab). This embedding service has a function encode that you can call to create embeddings for a list of sentences:
import bentoml BENTO_EMBEDDING_MODEL_END_POINT = "BENTO_EMBEDDING_MODEL_END_POINT" embedding_client = bentoml.SyncHTTPClient(BENTO_EMBEDDING_MODEL_END_POINT)
Note: Alternatively, you can self-host the same embedding service provided by the BentoML community. BentoCloud is used in this article as it provides fully-managed infrastructure with advanced features like autoscaling and observability.
With the embedding model ready, implement some logic to perform data splitting and embedding.
Create a function to preprocess the input text into a list of strings.
# Function to chunk text def chunk_text(filename: str) -> list: with open(filename, "r") as f: text = f.read() sentences = text.split("\n") return sentences
Process the files in the knowledge base. For this example, city_data is the directory containing a set of city data:
# Process files and chunk text # Add your own files to this directory cities = os.listdir("city_data") # Store chunked text for each of the cities in a list of dicts city_chunks = [] for city in cities: chunked = chunk_text(f"city_data/{city}") cleaned = [chunk for chunk in chunked if len(chunk) > 7] mapped = { "city_name": city.split(".")[0], "chunks": cleaned } city_chunks.append(mapped)
Split a list of strings into a list of embeddings, each grouping 25 text strings.
# Function to get embeddings def get_embeddings(texts: list) -> list: if len(texts) > 25: splits = [texts[x:x+25] for x in range(0, len(texts), 25)] embeddings = [] for split in splits: embedding_split = embedding_client.encode(sentences=split) if embedding_split.size > 0: # Check if the split is not empty embeddings.extend(embedding_split) else: print(f"Warning: No embeddings returned for split: {split}") return embeddings return embedding_client.encode(sentences=texts)
Match up embeddings and text chunks. Since the list of embeddings and the list of sentences should match by index, you can enumerate through either list to pair them:
# Prepare entities with embeddings entities = [] id = 0 for city_dict in city_chunks: embedding_list = get_embeddings(city_dict["chunks"]) for i, embedding in enumerate(embedding_list): entity = { "id": id; "vector": embedding, "sentence": city_dict["chunks"][i], "city": city_dict["city_name"] } entities.append(entity) id += 1 # Print entities to verify # print(entities)
Inserting data into the vector database#
With embeddings and data ready, it's time to insert the vectors along with metadata into Milvus for vector search later. The first step is to start a client and connect to Milvus.
Import the MilvusClient module and initialize a Milvus client with a file name to create a vector database. The vector dimension is determined by the embedding model; for example, the Sentence Transformers model all-MiniLM-L6-v2 produces vectors with 384 dimensions.
from pymilvus import MilvusClient COLLECTION_NAME = "Bento_Milvus_RAG" # A name for your collection DIMENSION = 384 # Initialize a Milvus client milvus_client = MilvusClient("milvus_demo.db") # Create collection milvus_client.create_collection( collection_name=COLLECTION_NAME, dimension=DIMENSION ) # Insert data res = milvus_client.insert( collection_name=COLLECTION_NAME, data=entities ) # Verify the insertion print(str(res["insert_count"]) + " entities inserted.")
Deploying an LLM server with BentoCloud#
Now, let’s set up the LLM server. Go to BentoCloud, and deploy the Llama 3 8B Instruct Bento on the Explore page.
Note: Alternatively, you can self-host the same LLM service provided by the BentoML community.
Similarly, you can interact with its on the Playground tab once it is ready.
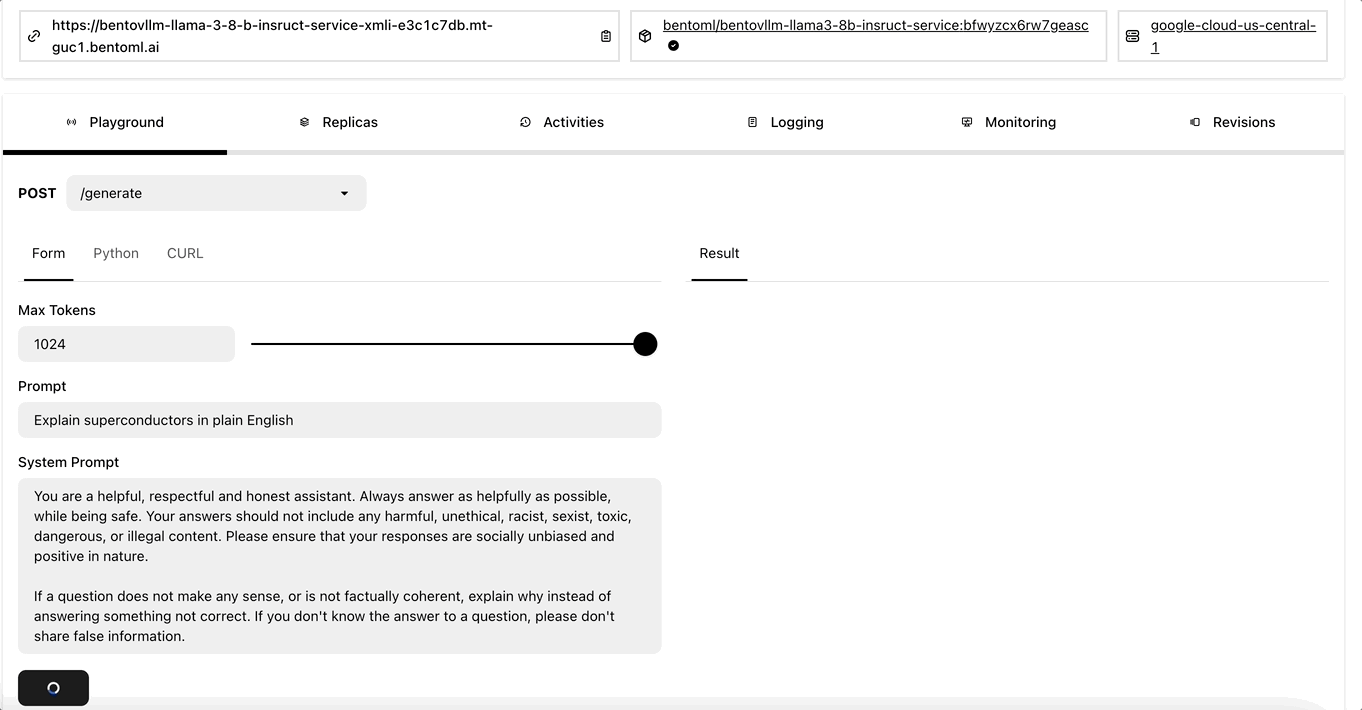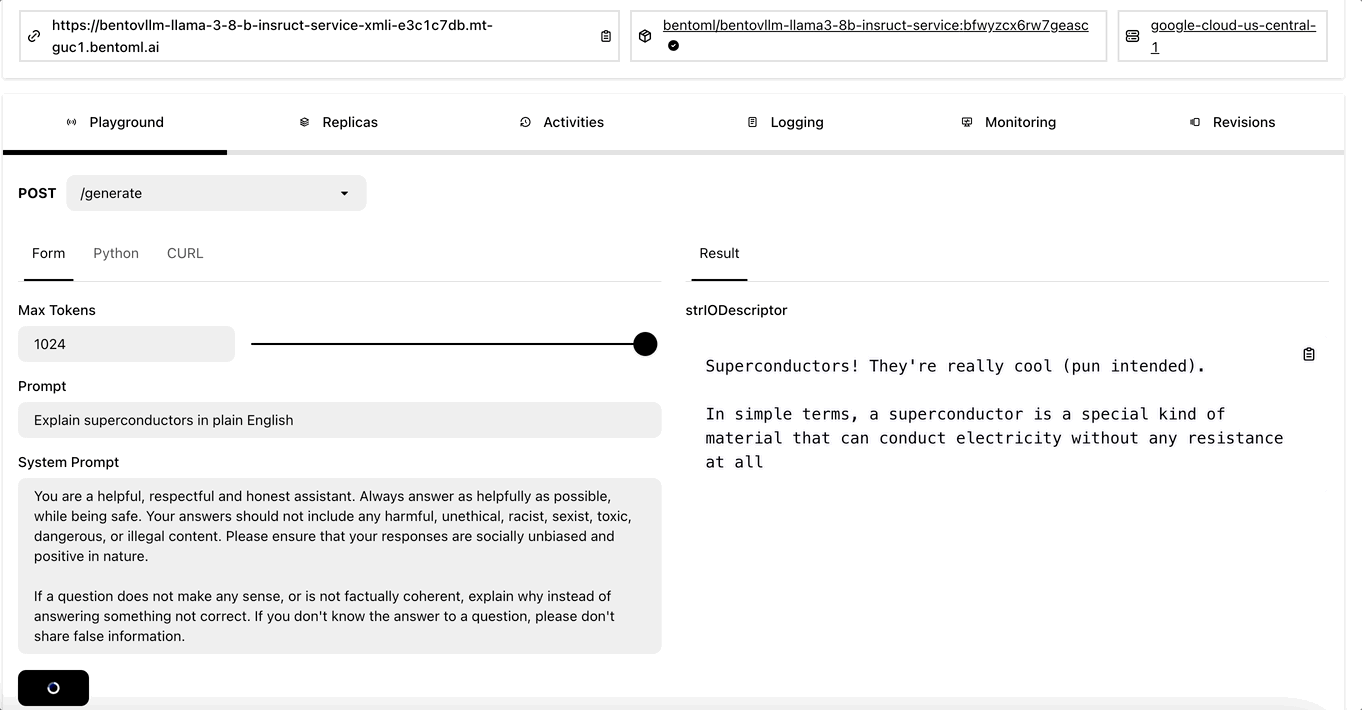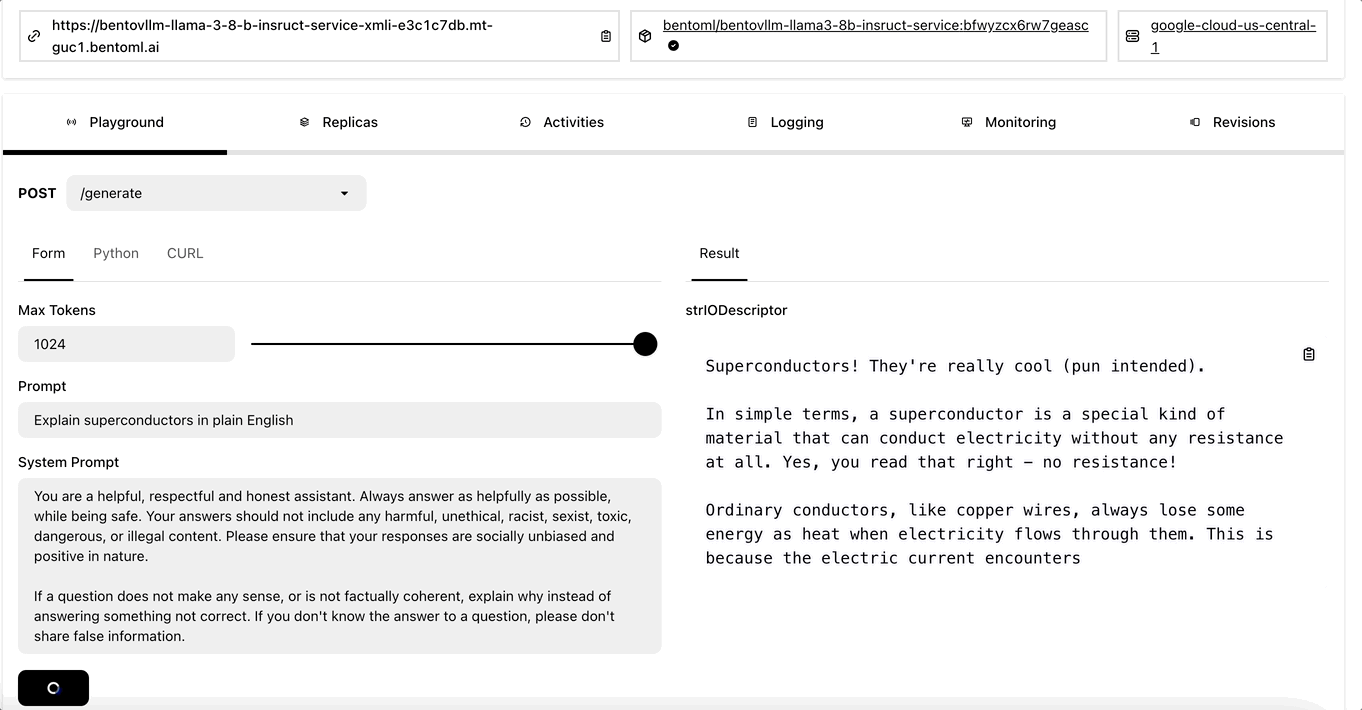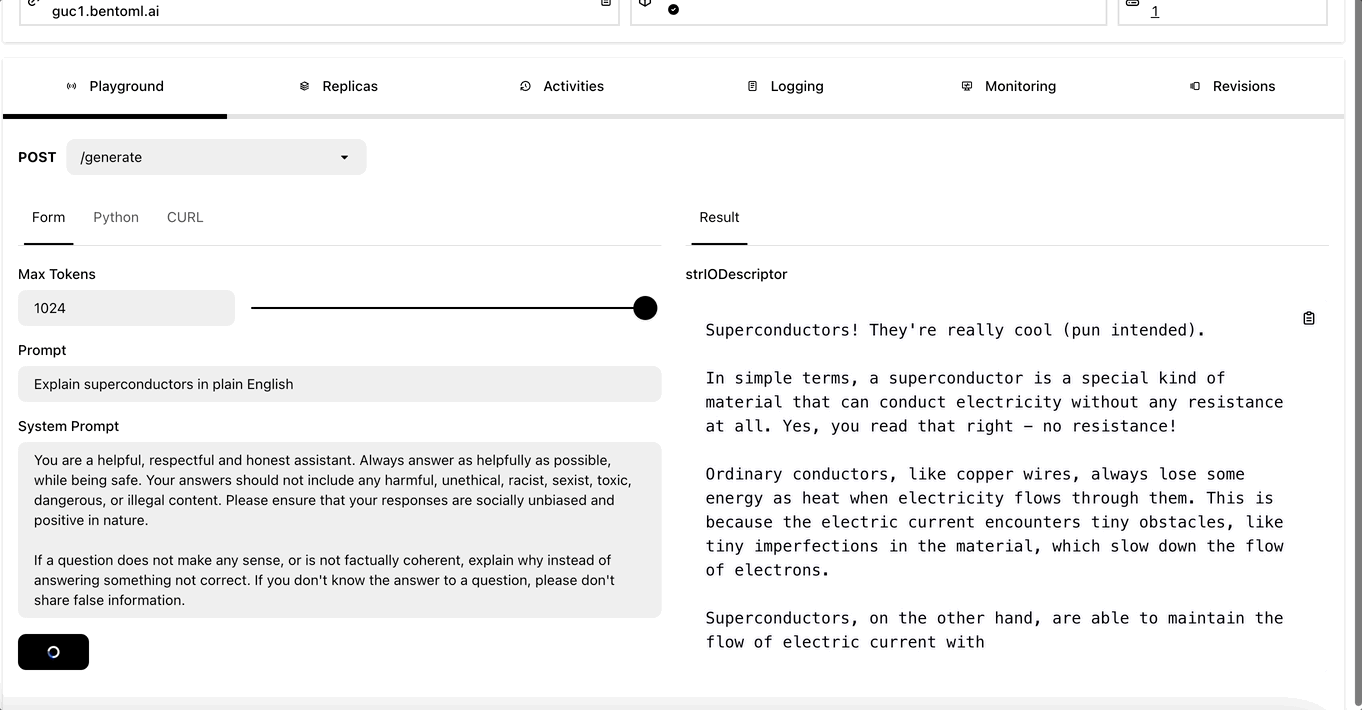
Interacting with the RAG app#
Now that we have inserted data into Milvus Lite and set up our LLM, let's move on to interacting with this RAG app.
First, retrieve the LLM server endpoint on BentoCloud and create a client:
import bentoml BENTO_LLM_END_POINT = "BENTO_LLM_END_POINT" llm_client = bentoml.SyncHTTPClient(BENTO_LLM_END_POINT)
Set up instructions for the LLM with the prompt, context, and question. The following function uses the LLM and returns the output from the client as a string:
def dorag(question: str, context: str): prompt = (f"You are a helpful assistant. The user has a question. Answer the user question based only on the context: {context}. \n" f"The user question is {question}") results = llm_client.generate( max_tokens=1024, prompt=prompt, ) res = "" for result in results: res += result return res
You are now ready to ask a question. This function takes a question, performs RAG to generate the relevant context from the background information, and then passes the context and the question to dorag() to get the result.
def ask_a_question(question): embeddings = get_embeddings([question]) res = milvus_client.search( collection_name=COLLECTION_NAME, data=embeddings, # Search for the one (1) embedding returned as a list of lists anns_field="embedding", # Search across embeddings limit = 5, # Get me the top 5 results output_fields=["sentence"] # Get the sentence/chunk and city ) sentences = [] for hits in res: for hit in hits: print(hit) sentences.append(hit['entity']['sentence']) context = ". ".join(sentences) return context question = input("Ask a question about the knowledge base: ") # Example question: "What state is Cambridge in?" context = ask_a_question(question=question) response = dorag(question=question, context=context) print(response)
After sending a query, here is the example result:
Based on the context, I can help you with that! According to the information provided, Cambridge is located in eastern Massachusetts, which implies that Cambridge is located within the state of Massachusetts.
Conclusion#
By leveraging BentoCloud's fully-managed infrastructure and Milvus Lite, you can build private RAG with custom AI models and efficient vector search. We hope this guide has been helpful, and we encourage you to explore further possibilities with BentoML, BentoCloud, and Milvus Lite.
More on BentoML, BentoCloud and Milvus Lite#
Check out the following resources to learn more:
- [Blog] Building RAG with Open-Source and Custom AI Models
- [Blog] Scaling AI Models Like You Mean It
- Join the BentoML Slack community, where thousands of AI/ML engineers help each other, contribute to the project, and talk about building AI products.
- BentoCloud is a production AI Inference Platform for fast moving AI teams. Sign up now to deploy your first AI model on the cloud and schedule a call with our experts if you have any questions.
- Milvus Lite documentation