Building and Deploying an Image Embedding Application with CLIP-API-Service
Authors

Last Updated
Share

⚠️ Outdated content#
Note: This blog post is not applicable any more. Please refer to the BentoML documentation to learn how to deploy a CLIP model.
In my previous blog post, I briefly explained embeddings in machine learning and walked you through an example of how to build a sentence embedding service with BentoML. Similar to sentence embeddings, image embeddings are numerical representations of visuals that enable a computer to “see” and “understand” images similar to the way humans do. By translating images into numbers, you can build sophisticated AI applications for tasks like matching images with text descriptions, sorting photo libraries, and even conducting nuanced searches that go beyond keywords to understand content.
In this connection, you can choose OpenAI CLIP (Contrastive Language–Image Pre-training), an open-source, multi-modal model that is capable of understanding and connecting text and images. By leveraging a vast dataset of images paired with textual descriptions, CLIP excels in various image-based tasks such as categorization, object recognition, and image retrieval aligned with textual queries. You can find detailed information on its official website.
Now, here comes the question again: how can you easily serve and deploy such sophisticated models in production? This is where BentoML steps in with CLIP-API-Service, an open-source tool that integrates CLIP with its streamlined API service. It provides a straightforward and user-friendly interface for leveraging the CLIP model without any setup hassles. Following the general workflow in BentoML, you can serve a CLIP model locally, package it into a Bento, and containerize it as a Docker image or distribute it to BentoCloud for better management and scaling in production.
In this blog post, let’s see how to build a production-ready CLIP application for efficient image embeddings and visual reasoning.
Setting up CLIP-API-Service#
Create a virtual environment first for dependency isolation.
python -m venv venv source venv/bin/activate
Note: Make sure you have installed Python 3.8 or newer and pip.
To install CLIP-API-Service, run the following command to install it from the GitHub source code.
pip install git+https://github.com/bentoml/CLIP-API-service.git
View supported models:
$ clip-api-service list-models ['openai/clip-vit-large-patch14-336', 'openai/clip-vit-large-patch14', 'openai/clip-vit-base-patch16', 'openai/clip-vit-base-patch32', 'ViT-B-32:openai', 'RN50x4:openai', 'ViT-L-14-336:openai', 'ViT-L-14:laion2b_s32b_b82k', 'ViT-g-14:laion2b_s12b_b42k', 'ViT-B-32:laion400m_e31', 'ViT-B-16-plus-240:laion400m_e31', 'RN50:yfcc15m', 'ViT-B-16-plus-240:laion400m_e32', 'ViT-B-16:openai', 'ViT-B-32:laion400m_e32', 'RN50x16:openai', 'RN101:openai', 'ViT-L-14:laion400m_e31', 'RN50x64:openai', 'ViT-H-14:laion2b_s32b_b79k', 'ViT-B-16:laion400m_e32', 'ViT-B-32:laion2b_e16', 'RN101:yfcc15m', 'ViT-bigG-14:laion2b_s39b_b160k', 'xlm-roberta-base-ViT-B-32:laion5b_s13b_b90k', 'ViT-B-32:laion2b_s34b_b79k', 'roberta-ViT-B-32:laion2b_s12b_b32k', 'RN50:cc12m', 'RN50:openai', 'ViT-L-14:openai', 'xlm-roberta-large-ViT-H-14:frozen_laion5b_s13b_b90k', 'ViT-g-14:laion2b_s34b_b88k', 'ViT-B-16:laion400m_e31', 'ViT-L-14:laion400m_e32']
The output includes various configurations of the CLIP model, which you can choose based on your requirements.
Testing a CLIP service locally#
Start a local HTTP server with a model of your choice by running clip-api-service serve --model-name. The following command uses openai/clip-vit-base-patch32.
$ clip-api-service serve --model-name=openai/clip-vit-base-patch32 2023-11-21T03:38:09+0000 [INFO] [cli] Environ for worker 0: set CUDA_VISIBLE_DEVICES to 0 2023-11-21T03:38:09+0000 [INFO] [cli] Prometheus metrics for HTTP BentoServer from "clip_api_service._service:svc" can be accessed at http://localhost:3000/metrics. 2023-11-21T03:38:10+0000 [INFO] [cli] Starting production HTTP BentoServer from "clip_api_service._service:svc" listening on http://0.0.0.0:3000 (Press CTRL+C to quit)
The CLIP service will be active at http://0.0.0.0:3000, handling requests with two endpoints.
-
encode: Transforms text or images into embeddings. You can then use them to power search engines that understand and index visual content through text or develop systems to sort data based on contextual relevance.This endpoint accepts JSON with the following available fields:
img_uri: An image URL.text: A string of textual description.img_blob: Base64 encoded string.
-
rank: Capable of performing Zero-Shot Image Classification (for example, classifying images into categories without prior training) and providing reasoning about visual scenarios.This endpoint accepts a list of
queriesand a list ofcandidates, which can be specified in one of the following:img_uri: An Image URLtext: A string of textual description.img_blob: Base64 encoded string.
You can interact with the Swagger UI or send a request via curl as below:
curl -X 'POST' \ 'http://0.0.0.0:3000/rank' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "queries": [ { "img_uri": "https://hips.hearstapps.com/hmg-prod/images/dog-puppy-on-garden-royalty-free-image-1586966191.jpg" } ], "candidates": [ { "text": "picture of a dog" }, { "text": "picture of a cat" }, { "text": "picture of a bird" }, { "text": "picture of a car" }, { "text": "picture of a plane" }, { "text": "picture of a boat" } ] }'
Expected output:
{ "probabilities": [ [ 0.9967791438102722, 0.0013982746750116348, 0.001299688476137817, 0.00017045278218574822, 0.00021614260913338512, 0.0001364690251648426 ] ], "cosine_similarities": [ [ 0.27583953738212585, 0.21014663577079773, 0.2094154953956604, 0.18910127878189087, 0.19147609174251556, 0.18687766790390015 ] ] }
The response includes probabilities and cosine similarities, helping you determine the best match between images and textual descriptions.
- Probabilities: Each value corresponds to the probability that the query image matches the text candidates in the same order. The highest probability (closest to 1) suggests the best match. In the output, the first candidate "picture of a dog" has the highest probability, indicating that the image is most likely a picture of a dog.
- Cosine similarities: These values measure how similar the image embedding is to the text embeddings. A higher cosine similarity score indicates a closer match. The first candidate again has the highest score, which supports the conclusion made by the probability.
Building and pushing the Bento#
As the CLIP model is functioning properly locally, you can build a Bento based on it and deploy the standardized distribution package anywhere you want.
-
Build a Bento and allow it to run on GPU settings by adding
--use-gpu. If your machine does not have any GPU resources, you can omit it. The build command uses--no-use-gpuby default.clip-api-service build --model-name=openai/clip-vit-base-patch32 --use-gpu -
View the Bento created:
bentoml list Tag Size Model Size Creation Time clip-api-service:zoh2csuiicbjvz4w 47.73 KiB 578.54 MiB 2023-11-21 07:37:39 -
Make sure you have already logged in to BentoCloud, then push the Bento to the serverless platform for advanced features like automatic scaling and observability.
bentoml push clip-api-service:latestAlternatively, run
bentoml containerize clip-api-service:latestto create a Bento Docker image, and then deploy it to any Docker-compatible environment. -
On the BentoCloud console, you can find the uploaded Bento on the Bentos page.
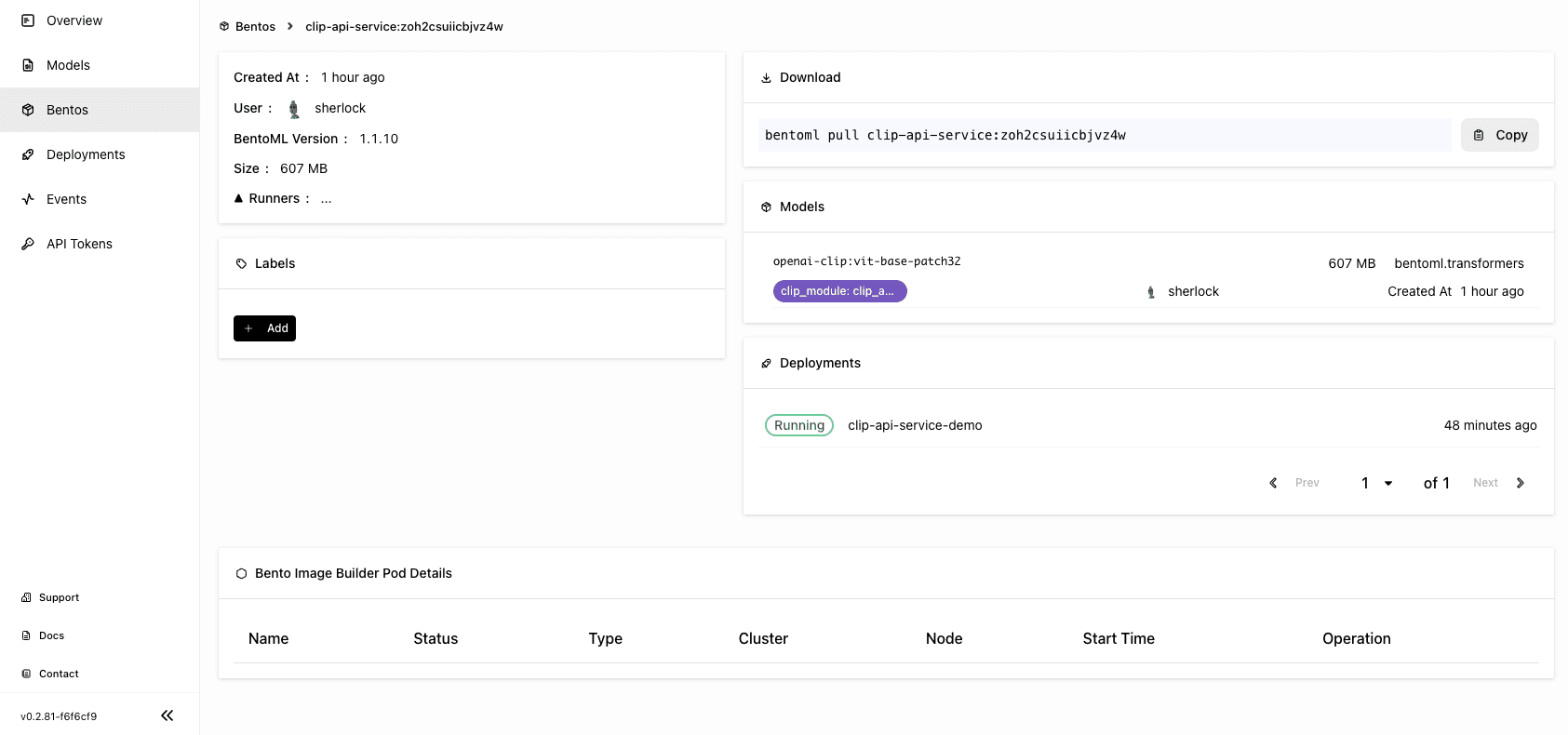
Deploying the Bento#
Do the following to deploy the Bento:
-
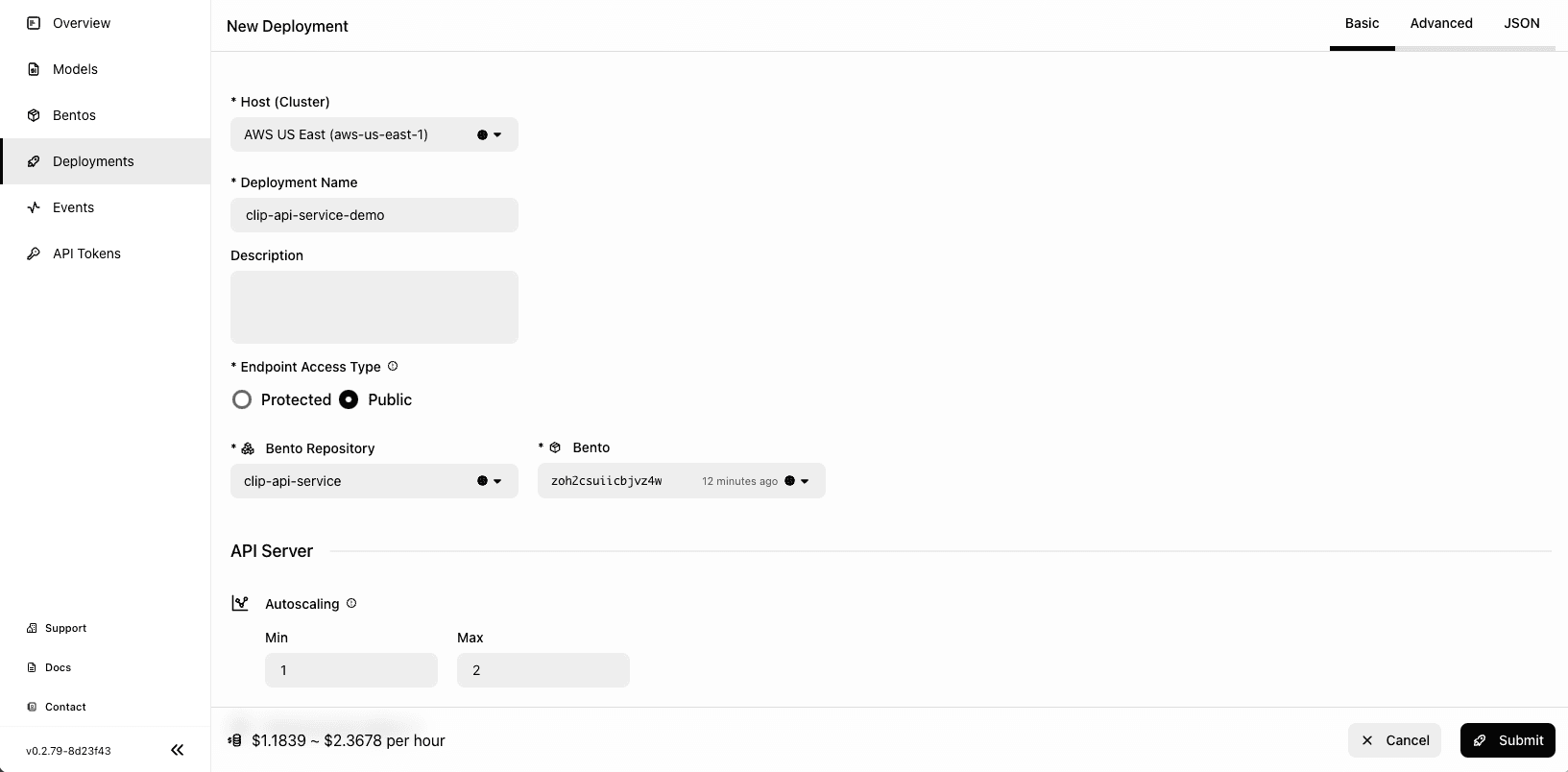
Navigate to the Deployments page and click Create.
-
Select On-Demand Function, which is useful for scenarios with loose latency requirements and sparse traffic.
-
Specify the required fields for the Bento Deployment on the Basic tab and click Submit. For your reference, I selected cpu.small and gpu.a10g.xlarge for both the API Server and Runner Pods. For more information, see Deployment creation and update information.
-
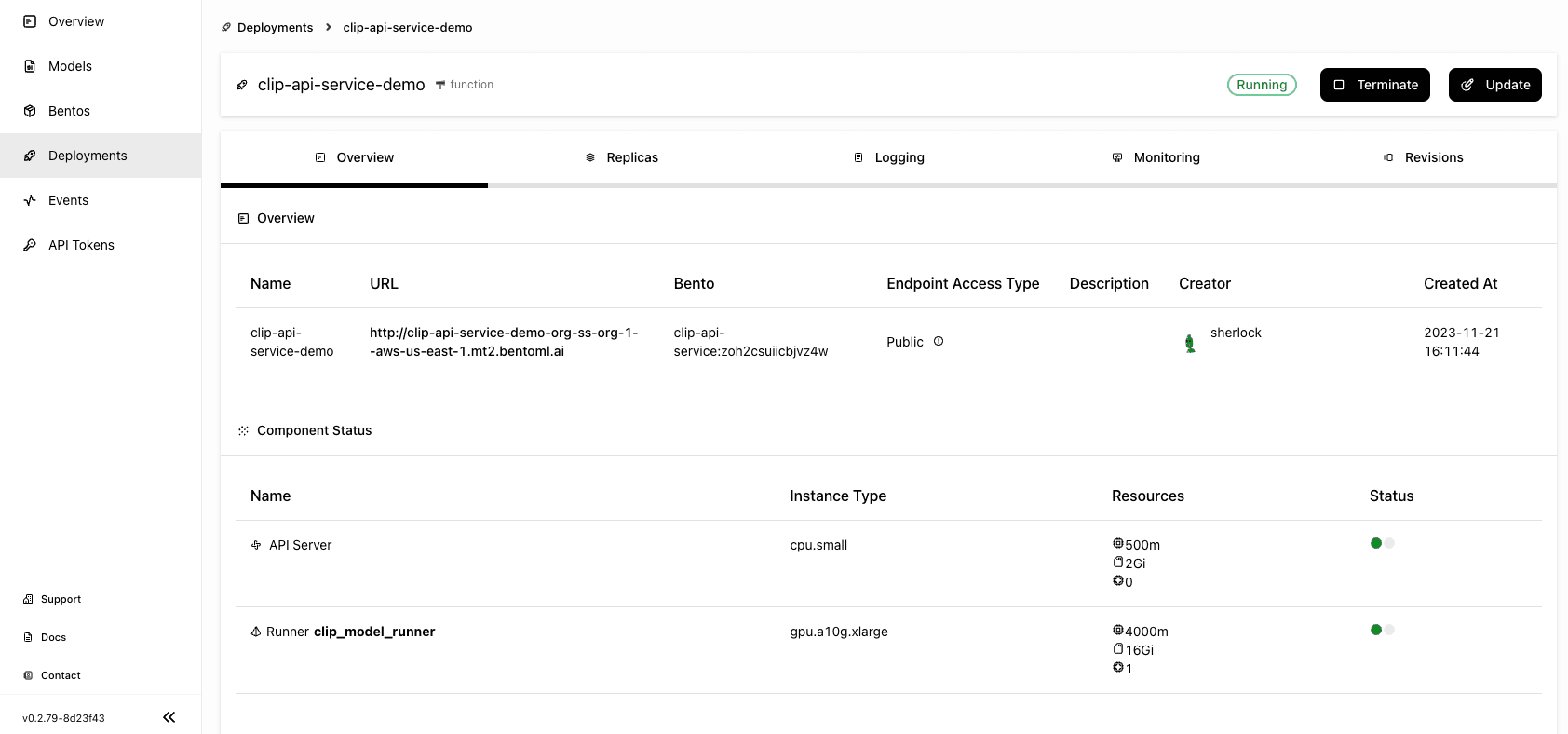
Wait for the application to be up and running.
-
The exposed URL is displayed on the Overview tab. Similarly, you can either run inference on the Swagger UI or send requests via
curl. Let’s interact with the application using the UI this time. Scroll down to the Service APIs section, select the/rankendpoint, setqueriesandcandidatesvalues, and click Execute.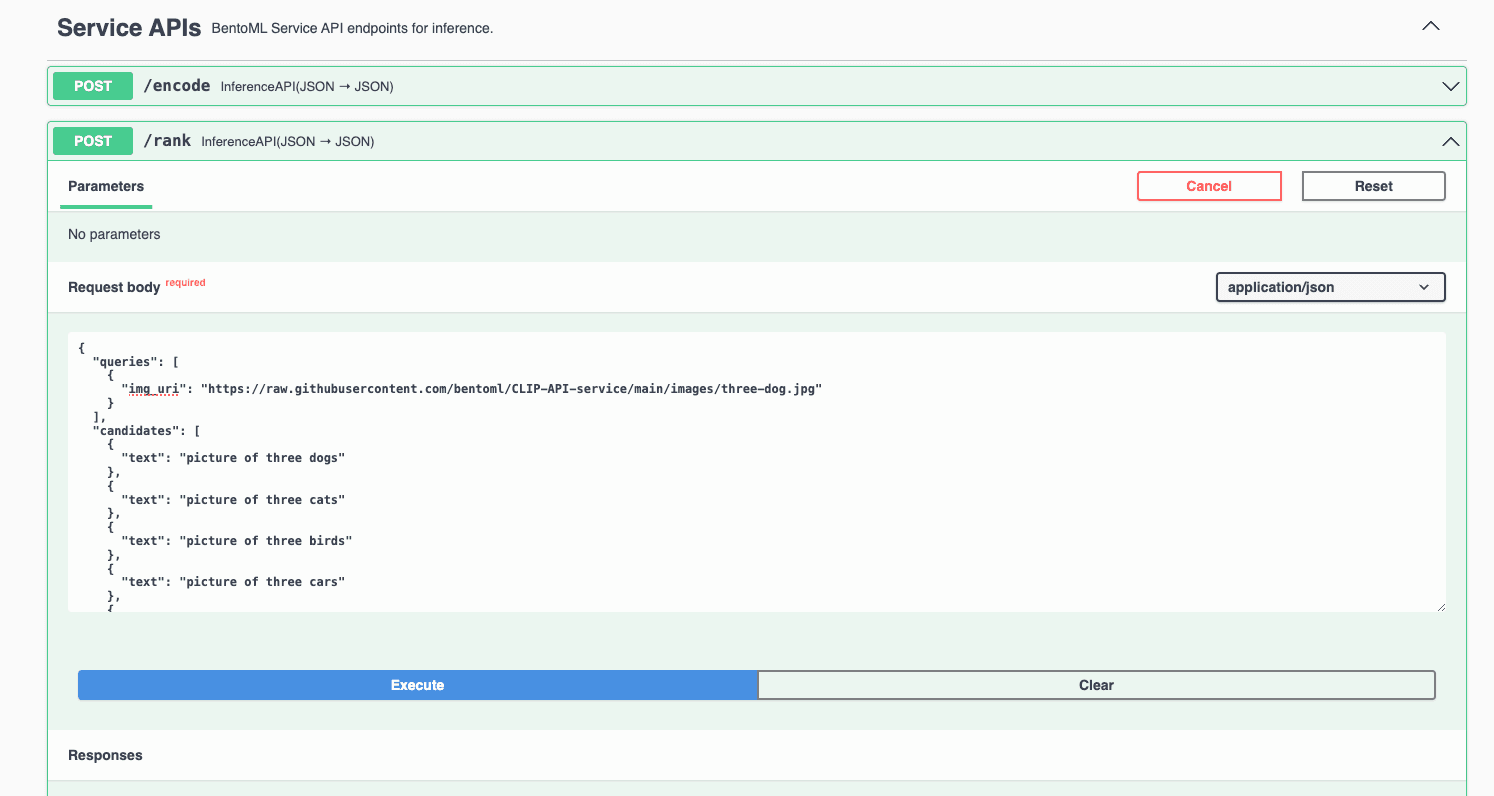
I used an image of three dogs in the request. You can find more example images in this GitHub repo. Expected output:
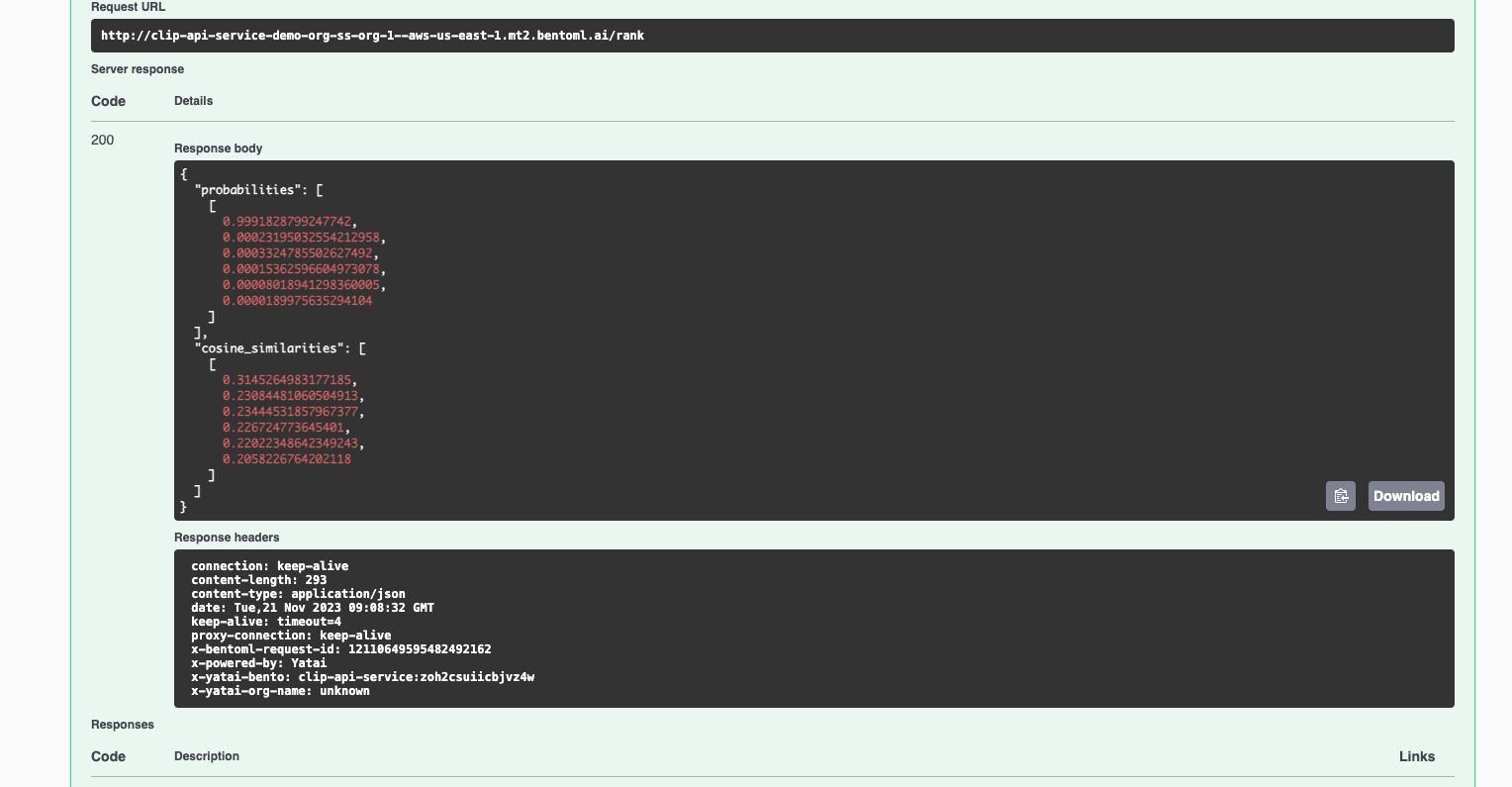
-
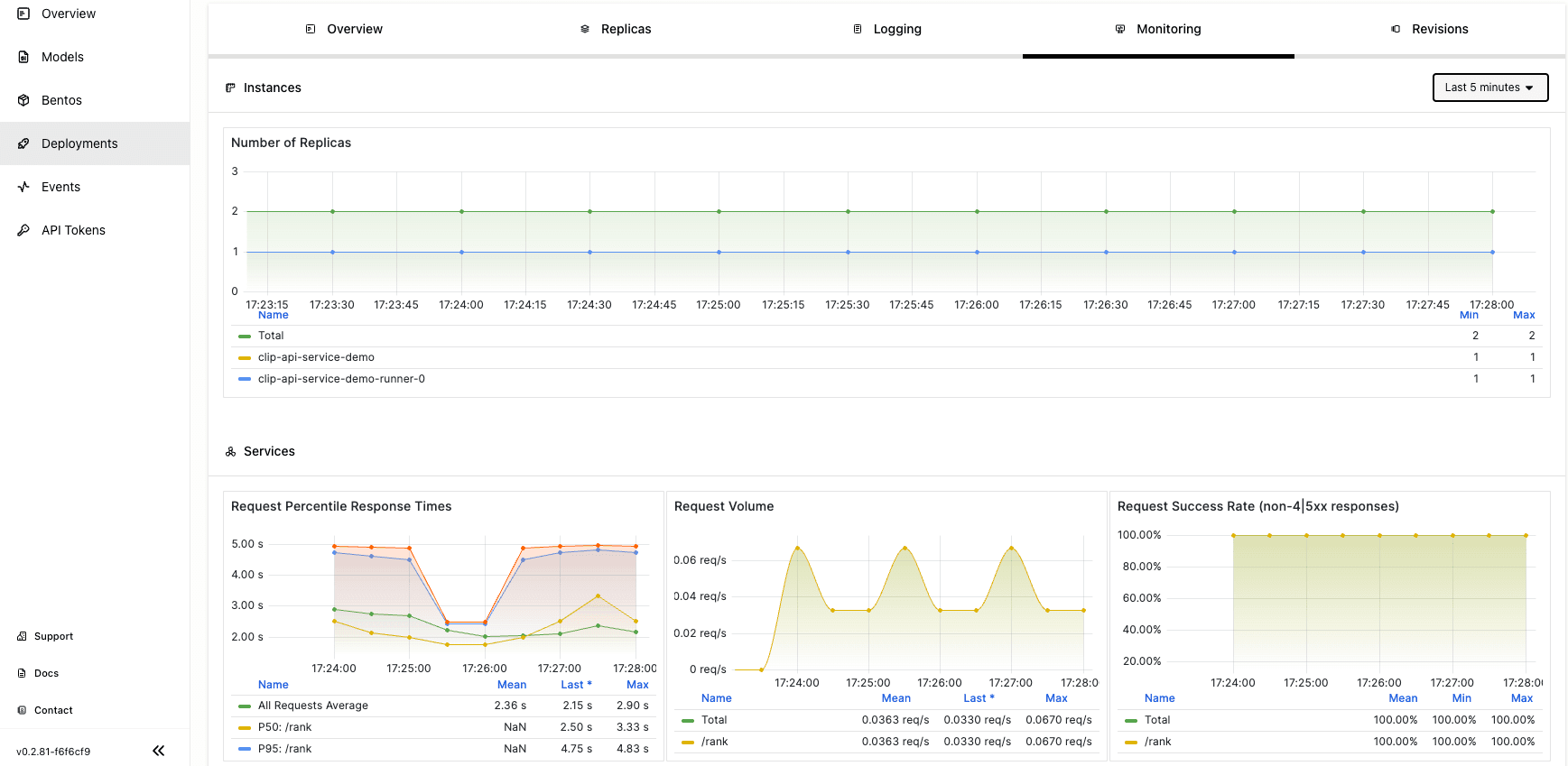
View the service’s performance metrics on the Monitoring tab.
Conclusion#
CLIP-API-Service offers a flexible solution to image recognition tasks that require nuanced understanding. Its integration with the BentoML ecosystem paves the way for developers to deploy powerful, multi-modal AI models with minimal effort. With BentoCloud, you are freed from the intricacies of infrastructure management and can focus on developing and refining your application.
More on BentoML#
To learn more about BentoML and its ecosystem tools, check out the following resources:
- [Blog] Deploying Code Llama in Production with OpenLLM and BentoCloud
- [Blog] Building and Deploying A Sentence Embedding Service with BentoML
- [Blog] From Models to Market: What's the Missing Link in Scaling Open-Source Models on Cloud?
- [Blog] BYOC to BentoCloud: Privacy, Flexibility, and Cost Efficiency in One Package
- Don’t miss out on the chance to be an early adopter! BentoCloud is still open for early sign-ups. Experience a serverless platform tailored to simplify the building and management of your AI applications, ensuring both ease of use and scalability.