Building RAG Systems with Open-Source and Custom AI Models
Authors

Last Updated
Share

Retrieval-Augmented Generation (RAG) is a widely used application pattern for Large Language Models (LLMs). It uses information retrieval systems to give LLMs extra context, which aids in answering user queries not covered in the LLM's training data and helps to prevent hallucinations. In this blog post, we draw from our experience working with BentoML customers to discuss:
- Common challenges in making a RAG system ready for production
- How to use open-source or custom fine-tuned models to enhance RAG performance
- How to build scalable AI systems comprising multiple models and components
By the end of this post, you'll learn the basics of how open-source and custom AI/ML models can be applied in building and improving RAG applications.
Note: This blog post is based on the video below, with additional details.
Simple RAG system#
A simple RAG system consists of 5 stages:
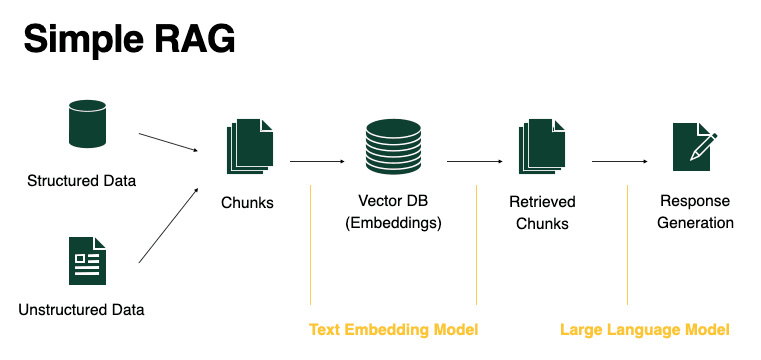
- Chunking: RAG begins with turning your structured or unstructured dataset into text documents, and breaking down text into small pieces (chunks).
- Embed documents: A text embedding model steps in, turning each chunk into vectors representing their semantic meaning.
- VectorDB: These embeddings are then stored in a vector database, serving as the foundation for data retrieval.
- Retrieval: Upon receiving a user query, the vector database helps retrieve chunks relevant to the user's request.
- Response Generation: With context, an LLM synthesizes these pieces to generate a coherent and informative response.
Implementing a simple RAG system with a text embedding model and an LLM might initially only need a few lines of Python code. However, dealing with real-world datasets and improving performance for the system require more than that.
Challenges in production RAG#
Building a RAG for production is no easy feat. Here are some of the common challenges:
Retrieval performance#
- Recall: Not all chunks that are relevant to the user query are retrieved.
- Precision: Not all chunks retrieved are relevant to the user query.
- Data ingestion: Complex documents, semi-structured and unstructured data.
Response synthesis#
- Safeguarding: Is the user query toxic or offensive and how to handle it.
- Tool use: Use tools such as browsers or search engines to assist the response generation.
- Context accuracy: Retrieved chunks lacking necessary context or containing misaligned context.
Response evaluation#
- Synthetic dataset for evaluation: LLMs can be used to create evaluation datasets for measuring the RAG system’s responses.
- LLMs as evaluators: LLMs also serve as evaluators themselves.
Improving RAG pipeline with custom AI models#
To build a robust RAG system, you need to take into account a set of building blocks or baseline components. These elements or decisions form the foundation upon which your RAG system's performance is built.
Text embedding model#
Common models like text-embedding-ada-002, while popular, may not be the best performers across all languages and domains. Their one-size-fits-all approach often falls short when you have nuanced requirements for specialized fields.
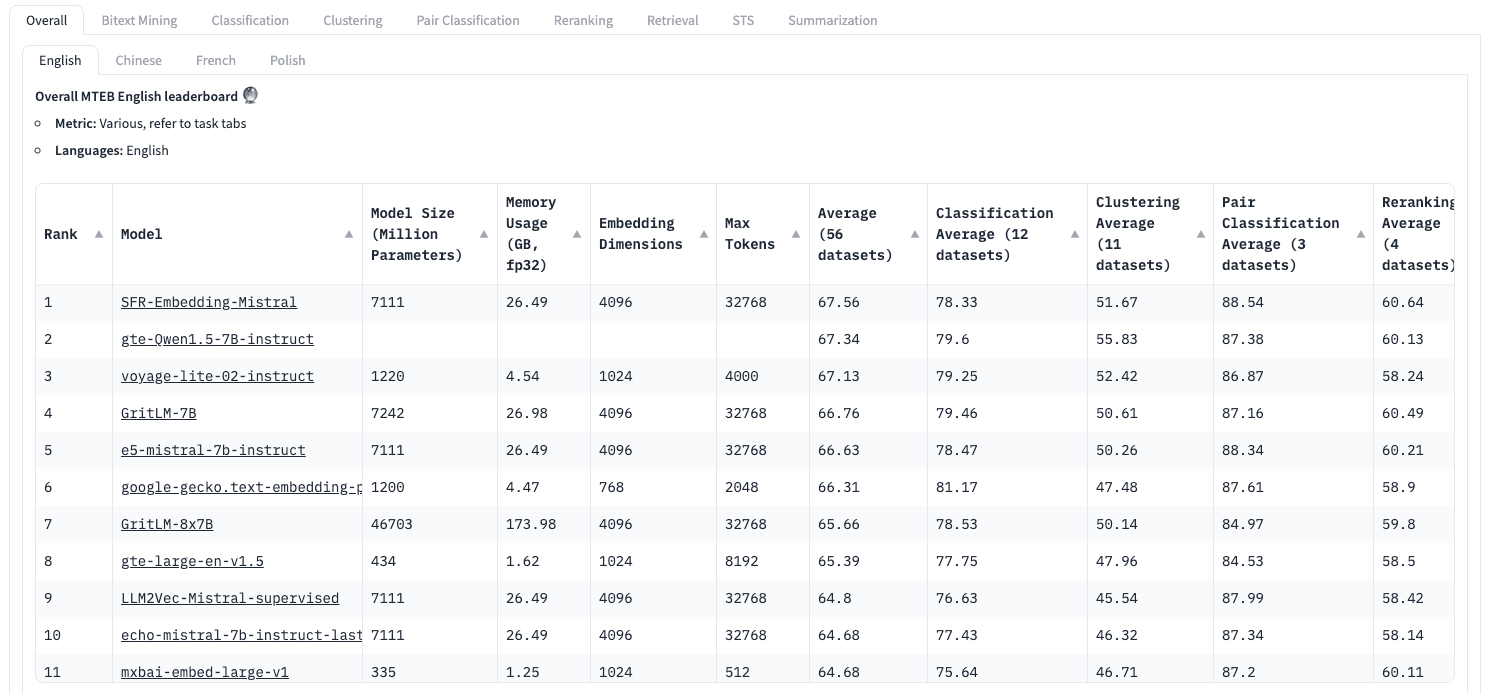
Source: Hugging Face Massive Text Embedding Benchmark (MTEB) Leaderboard
On this note, fine-tuning an embedding model on a domain-specific dataset often enhances the retrieval accuracy. This is due to the improvement of embedding representations for the specific context during the fine-tuning process. For instance, while a general embedding model might associate the word "Bento" closely with "Food" or "Japan", a model fine-tuned for AI inference would more likely connect it with terms like "Model Serving", "Open Source Framework", and "AI Inference Platform".
Large language model#
While GPT-4 leads the pack in performance, not all applications require such firepower. Sometimes, a more modest and well-optimized model can deliver the speed and cost-effectiveness needed, especially when provided with the right context. In particular, consider the following questions when choosing the LLM for your RAG:
- Security and privacy: What level of control do you need over your data?
- Latency requirement: What is your TTFT (Time to first token) and TPOT (Time per output token) requirement? Is it serving real-time chat applications or offline data processing jobs?
- Reliability: For mission-critical applications, dedicated deployment that you control, often provides more reliable response time and generation quality.
- Capabilities: What tasks do you need your LLM to perform? For simple tasks, can it be replaced by a smaller specialized models?
- Domain knowledge: Does an LLM trained on general web content understand your specific domain knowledge?
These questions are important no matter you are self-hosting open-source models or using commercial model endpoints. The right model should align with your data policies, budget plan, and the specific demands of your RAG application.
Context-aware chunking#
Most simple RAG systems rely on fixed-size chunking, dividing documents into equal segments with some overlap to ensure continuity. This method, while straightforward, can sometimes strip away the rich context embedded in the data.
By contrast, context-aware chunking breaks down text data into more meaningful pieces, considering the actual content and its structure. Instead of splitting text at fixed intervals (like word count), it identifies logical breaks in the text using NLP techniques. These breaks can occur at the end of sentences, paragraphs, or when topics shift. This ensures each chunk captures a complete thought or idea, and makes it possible to add additional metadata to each chunk, for implementing metadata filtering or Small-to-Big retrieval.
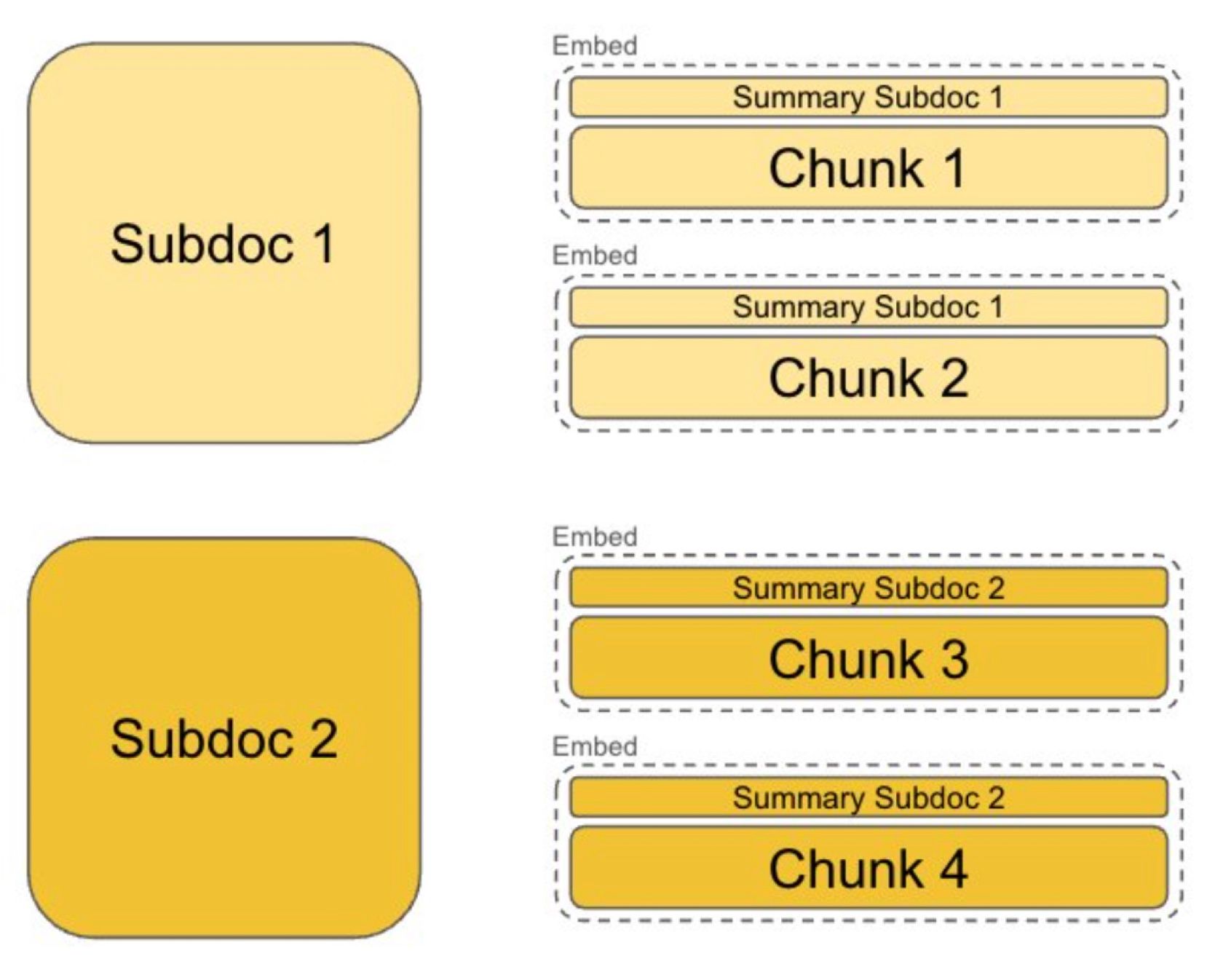
As your RAG system can understand the overall flow and ideas within a document with context-aware chunking, it is capable of creating chunks that capture not just isolated sentences but also the broader context they belong to.
Parsing complex documents#
The real world throws complex documents at us - product reviews, emails, recipes, and websites that not only contain textual content but are also enriched with structure, images, charts, and tables.
Traditional Optical Character Recognition (OCR) tools such as EasyOCR and Tesseract are proficient in transcribing text but often fall short when it comes to understanding the layout and contextual significance of the elements within a document.
For those grappling with the complexities of modern documents, consider integrating the following models and tools into your RAG systems:
- Layout analysis: LayoutLM (and v2, v3) have been pivotal in advancing document layout analysis. LayoutLMv3, in particular, integrates text and layout with image processing without relying on conventional CNNs, streamlining the architecture and leveraging masked language and image modeling, making it highly effective in understanding both text-centric and image-centric tasks.
- Table detection and extraction: Table Transformer (TATR) is specifically designed for detecting, extracting, and recognizing the structure of tables within documents. It operates similarly to object detection models, using a DETR-like architecture to achieve high precision in both table detection and functional analysis of table contents.
- Document question-answering systems: Building a Document Visual Question Answering (DocVQA) system often requires multiple models, such as models for layout analysis, OCR, entity extraction, and finally, models trained to answer queries based on the document's content and structure. Tools like Donut and the latest versions of LayoutLMv3 can be helpful in developing robust DocVQA systems.
- Fine-tuning: Existing open-source models are great places to start but with additional fine-tuning on your specific documents, handling its unique content or structure, can often lead to greater performance.
Metadata filtering#
Incorporating these models into your RAG systems, especially when combined with NLP techniques, allows for the extraction of rich metadata from documents. This includes elements like the sentiment expressed in text, the structure or summarization of a document, or the data encapsulated in a table. Most modern vector databases supports storing metadata alongside text embeddings, as well as using metadata filtering during retrieval, which can significantly enhance the retrieval accuracy.

Reranking models#
While embedding models are a powerful tool for initial retrieval in RAG systems, they can sometimes return a large number of documents that might be generally relevant, but not necessarily the most precise answers to a user's query. This is where reranking models come into play.
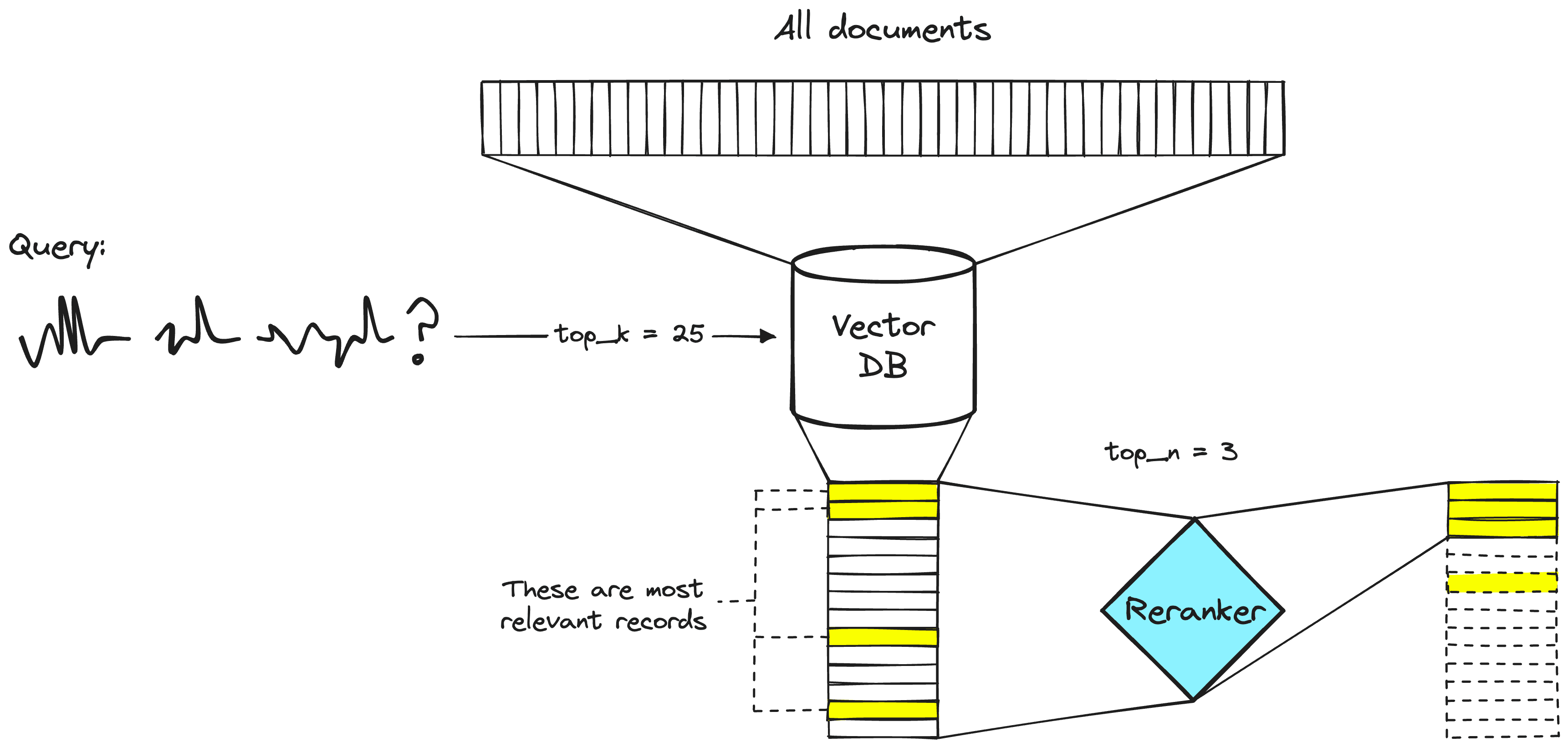
Image source: Rerankers and Two-Stage Retrieval
Reranking models introduce a two-step retrieval process that significantly improves precision:
- Initial retrieval: An embedding model acts as a first filter, scanning the entire database and identifying a pool of potentially relevant documents. This initial retrieval is fast and efficient.
- Reranking: The reranking model then takes over, examining the shortlisted documents from the first stage. It analyzes each document's content in more detail, considering its specific relevance to the user's query. Based on this analysis, the reranking model reorders the documents, placing the most relevant ones at the top (sometimes at both ends of the context window for maximum relevance).
While reranking provides superior precision, it adds an extra step to the retrieval process. Many may think this can increase latency. However, reranking also means you don’t need to send all retrieved chunks to the LLM, leading to faster generation time.
For more information, see this article Rerankers and Two-Stage Retrieval.
Cross-modal retrieval#
While traditional RAG systems primarily focus on text data, research like ImageBind: One Embedding Space To Bind Them All is opening doors to a more versatile approach: Cross-modal retrieval.

Image source: ImageBind: One Embedding Space To Bind Them All
Cross-modal retrieval transcends traditional text-based limitations, supporting interplay between different types of data, such as audio and visual content. For example, when a RAG system incorporates models like BLIP for visual reasoning, it’s able to understand the context within images, improving the textual data pipeline with visual insights.
While still in its early stages, multi-modal retrieval holds great potential what RAG systems can achieve.
Recap: AI models in RAG systems#
As we improve our RAG system for production, the complexity increases accordingly. Ultimately, we may find ourselves orchestrating a group of AI models, each playing its part in the workflow of data processing and response generation.
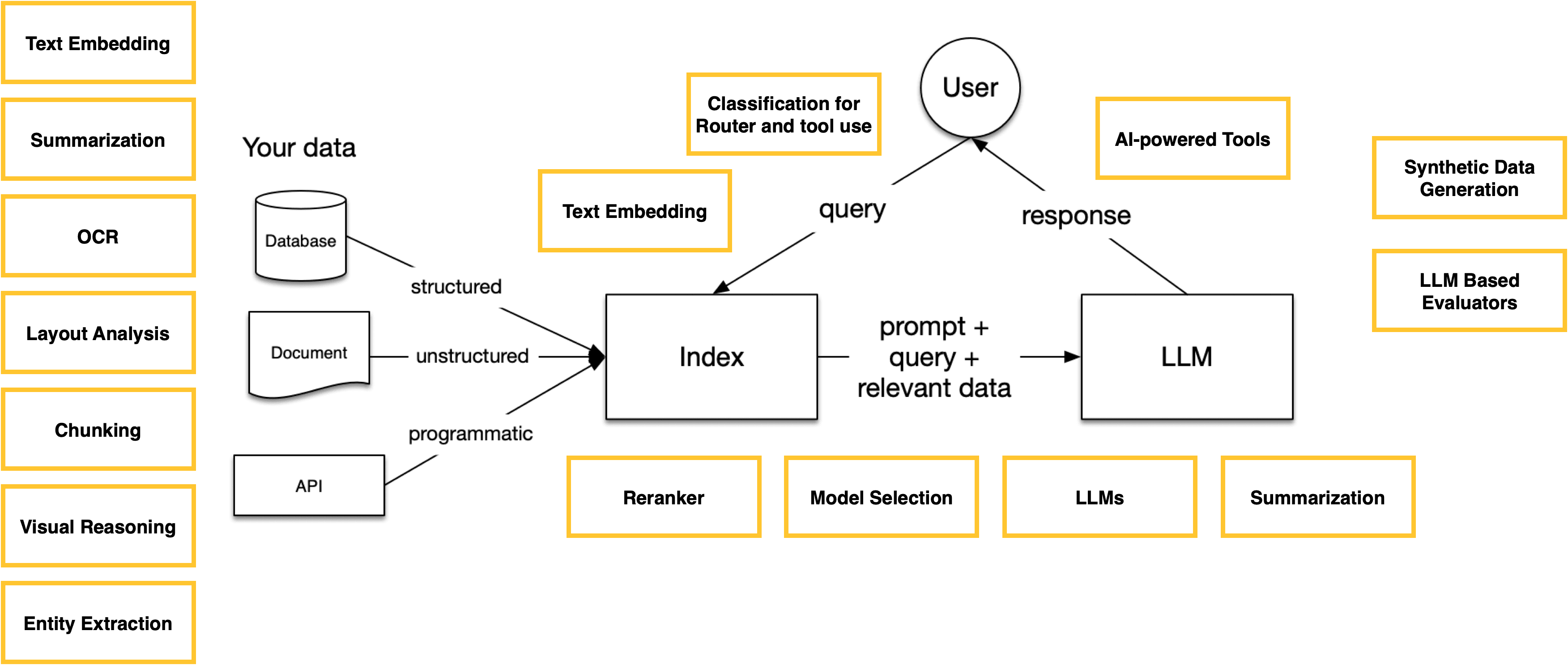
As we address these complexities, we also need to pay attention to the infrastructure for deploying AI models. In the next part of this blog post, we’ll explore these infrastructure challenges and introduce how BentoML is contributing to this space.
Scaling RAG services with multiple custom AI models#
Serving embedding models#
One of the most frequent challenges is efficiently serving the embedding model. BentoML can help improve its performance in the following ways:
- Asynchronous non-blocking invocation: BentoML allows you to convert synchronous inference methods of a model to asynchronous calls, providing non-blocking implementation and improving performance in IO-bound operations.
- Shared model replica across multiple API workers: BentoML supports running shared model replicas across multiple API workers, each assigned with a specific GPU. This can maximize parallel processing, increase throughput, and reduce overall inference time.
- Adaptive batching: Within a BentoML Service, there is a dispatcher that manages how batches should be optimized by dynamically adjusting batch sizes and wait time to suit the current load. This mechanism is called adaptive batching in BentoML. In the context of text embedding models, we often see performance improvements up to 3x in latency and 2x in throughput comparing to non-batching implementations.
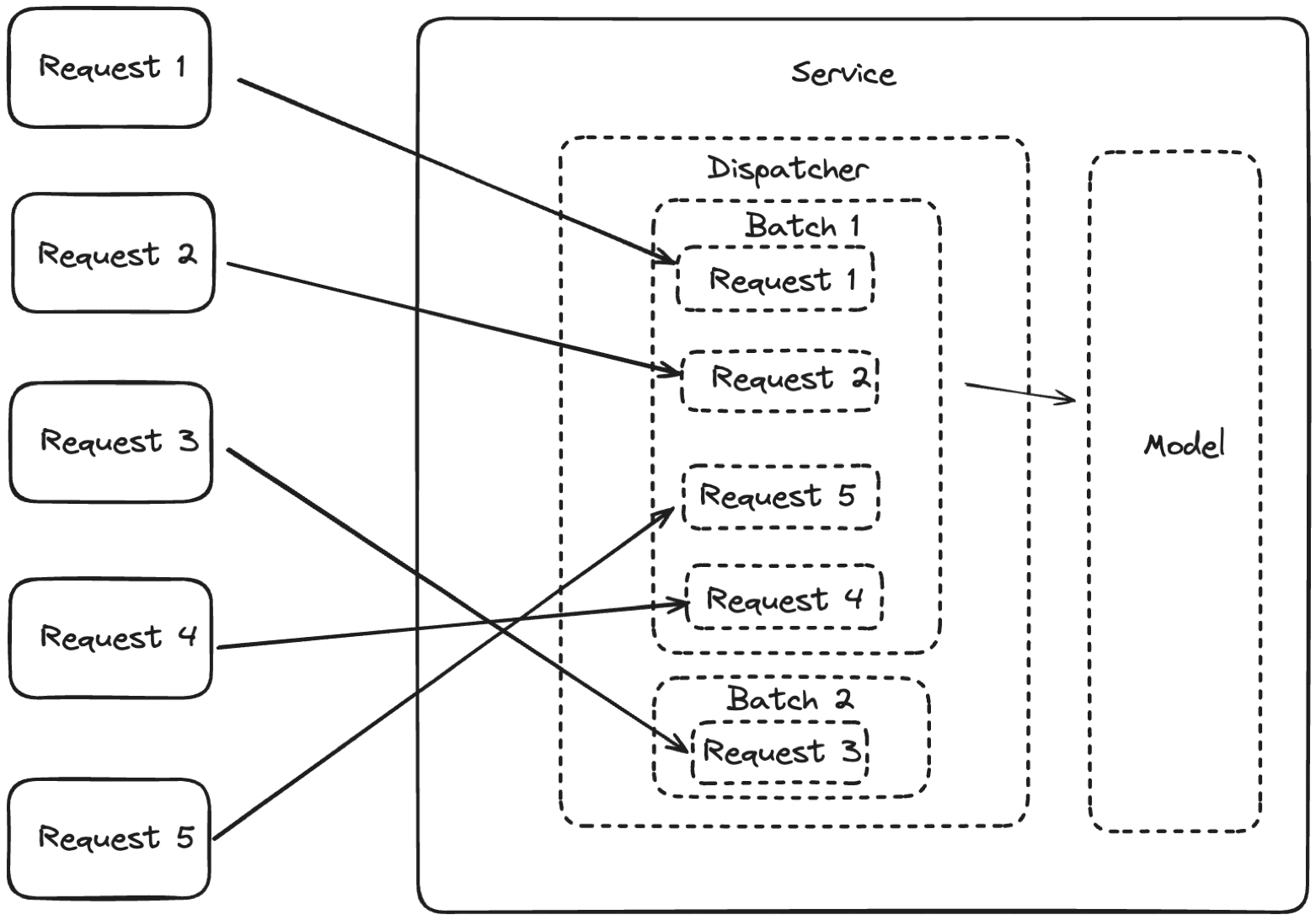
For more information, see this BentoML example project to deploy an embedding model.

Self-hosting LLMs#
Many developers may start with pulling a model from Hugging Face and run it with frameworks like PyTorch or Transformers. This is fine for development and exploration, but performs poorly when serving high throughput workloads in production.
There are a variety of open-source tools like vLLM, OpenLLM, mlc-llm, and TensorRT-LLM available for self-hosting LLMs. Consider the following when choosing such tools:
- Inference best practices: Does the tool support optimized LLM inference? Techniques like continuous batching, Paged Attention, Flash Attention, and automatic prefix caching need to be implemented for efficient performance.
- Customizations: LLM behavior needs customized control like advanced stop conditioning (when a model should cease generating further content), specific output formats (ensuring the results adhere to a specific structure or standard), or input validation (using a classification model to detect). If you need such customization, consider using BentoML + vLLM.
In addition to the LLM inference server, the infrastructure required for scaling LLM workloads also comes with unique challenges. For example:
-
GPU Scaling: Unlike traditional workloads, GPU utilization metrics can be deceptive for LLMs. Even if the metrics suggest full capacity, there might still be room for more requests and more throughput. This is why solutions like BentoCloud offers concurrency-based autoscaling. Such an approach learns the semantic meanings of different requests, using dynamic batching and wise resource management strategies to scale effectively.
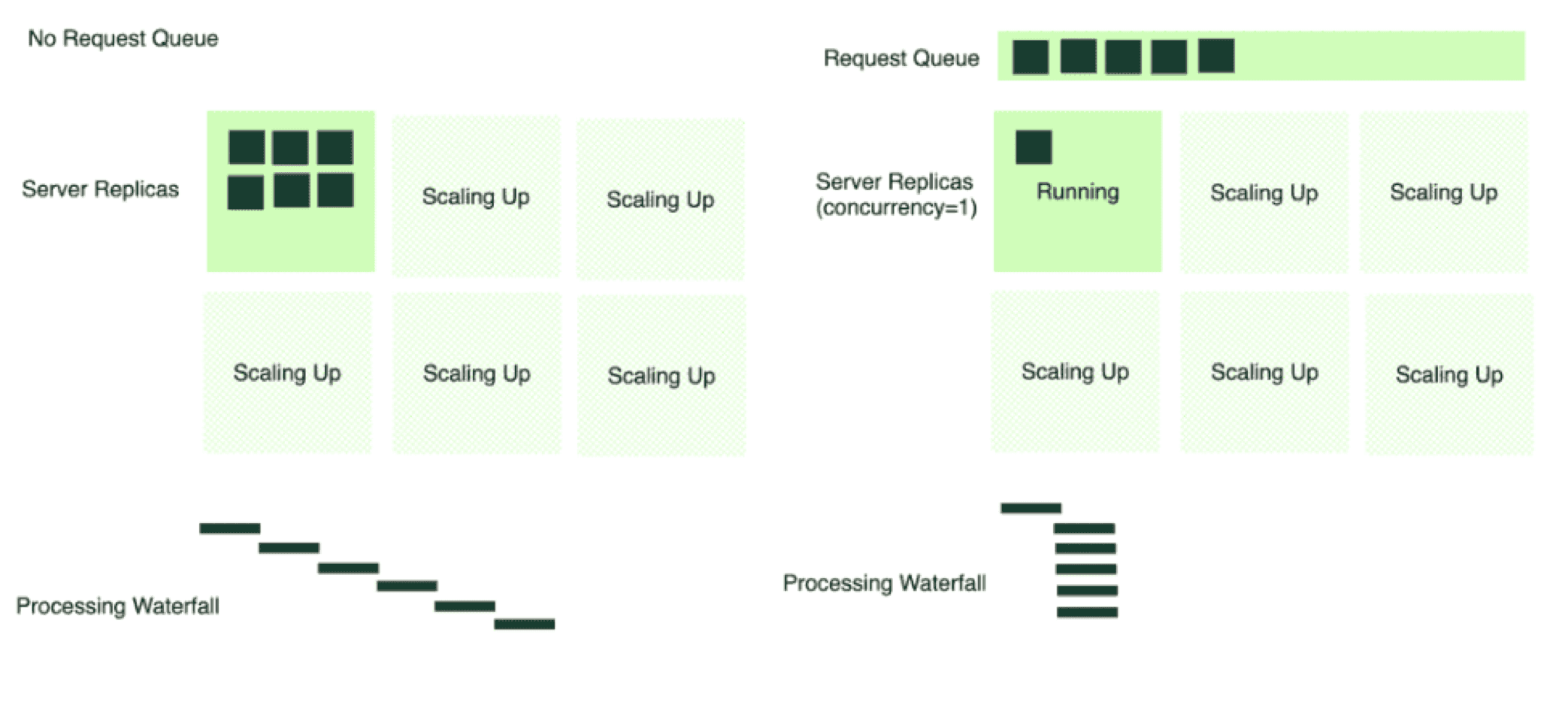
-
Cold start and fast scaling with large container image and model files: Downloading large images and models from remote storage and loading models into GPU memory is a time-consuming process, breaking most existing cloud infrastructure’s assumptions about the workload. Specialized infrastructure, like BentoCloud, helps accelerate this process via lazy image pulling, streaming model loading and in-cluster caching.
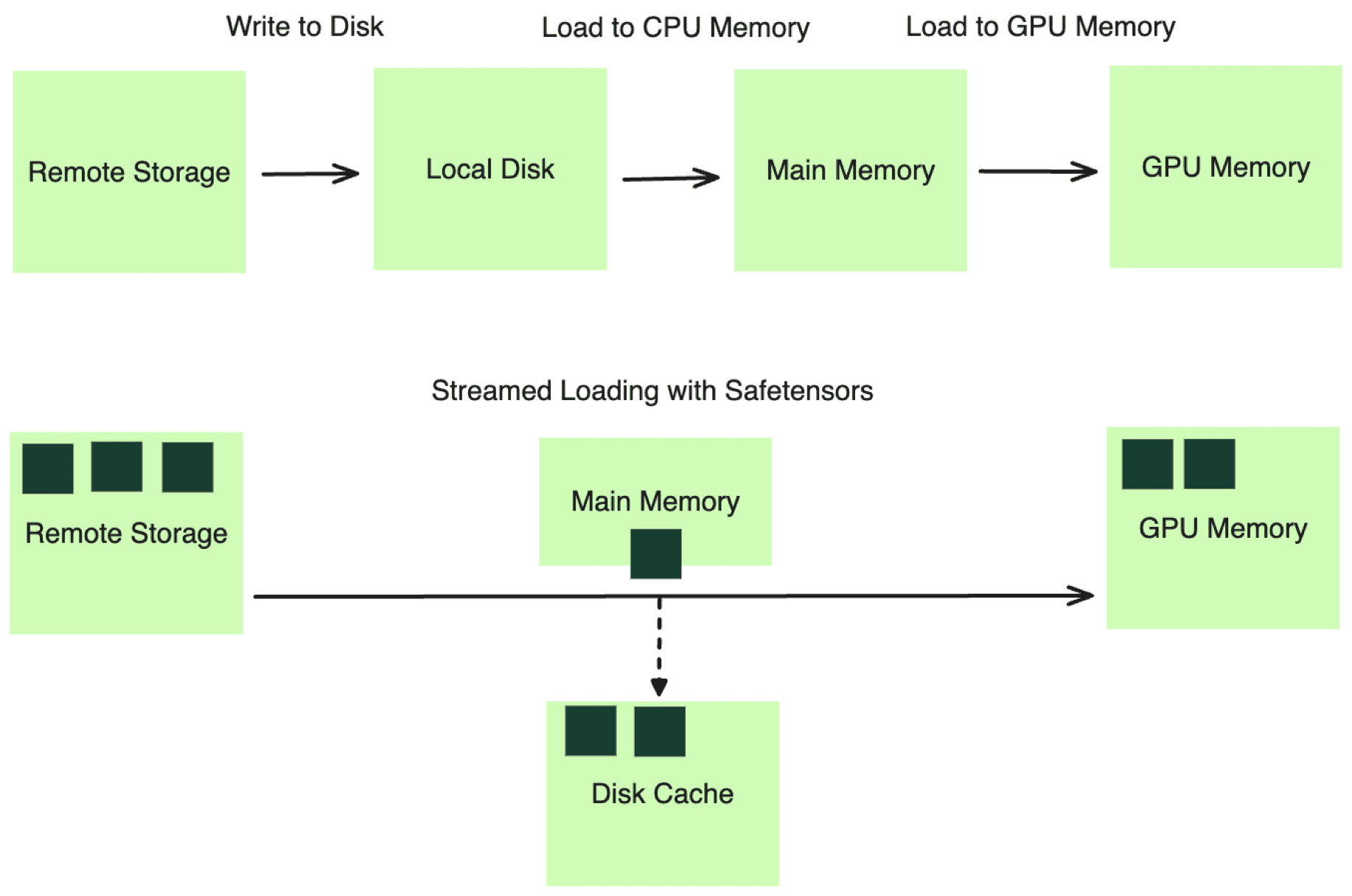
For details, refer to Scaling AI Model Deployment.
Model composition#
Model composition is a strategy that combines multiple models to solve a complex problem that cannot be easily addressed by a single model. Before we talk about how BentoML can help you compose multiple models for RAG, let’s take a look at other two typical scenarios used in RAG systems.
Document processing pipeline#
A document processing pipeline consists of multiple AI/ML models, each specializing in a stage of the data conversion process. In addition to OCR that extract text from images, it can extend to layout analysis, table extraction and image understanding.
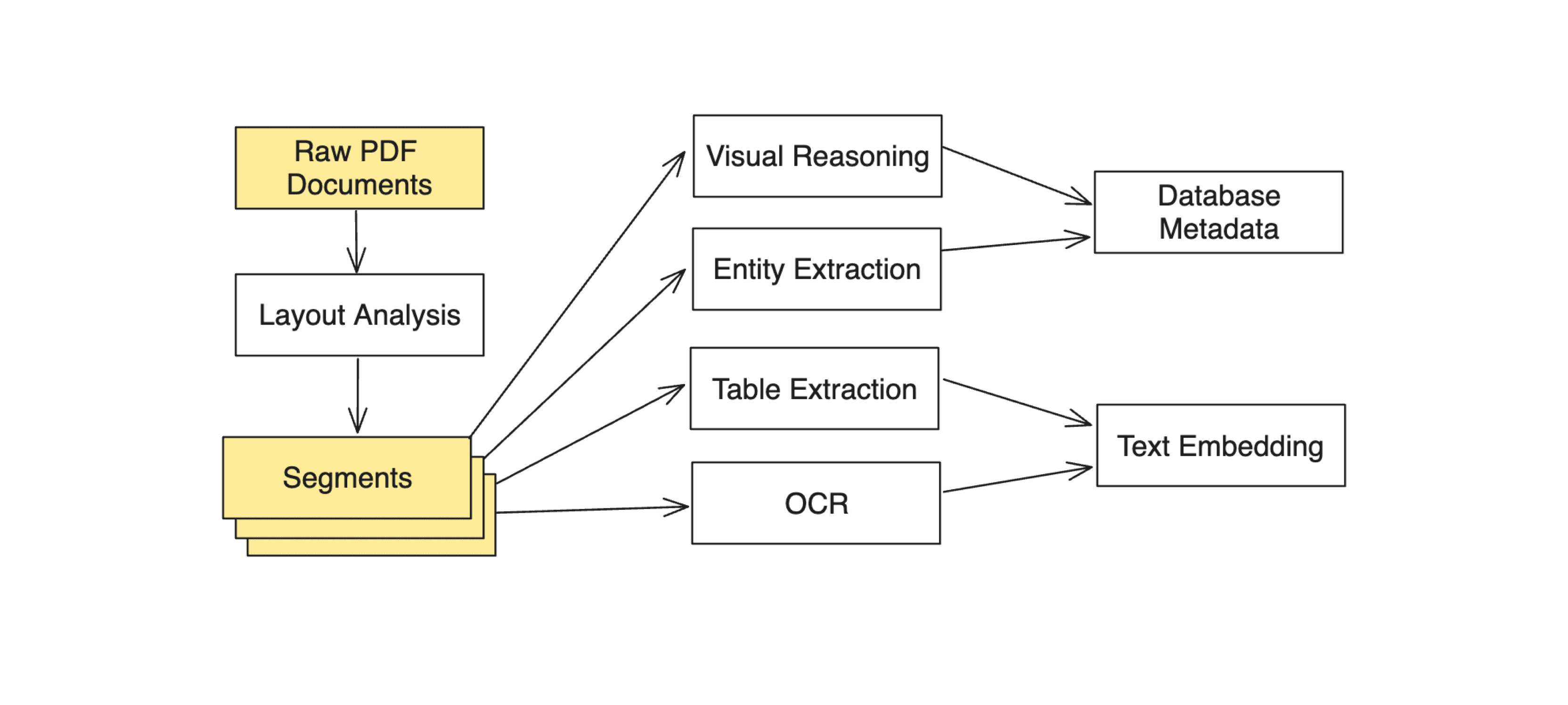
The models used in this process might have different resource requirements, some requiring GPUs for model inference and others, more lightweight, running efficiently on CPUs. Such a setup naturally fits into a distributed system of micro-services, each service serving a different AI model or function. This architectural choice can drastically improve resource utilization and reduce cost.
BentoML facilitates this process by allowing users to easily implement a distributed inference graph, where each stage can be a separate BentoML Service wrapping the capability of the corresponding model. In production, they can be deployed and scaled separately (more details can be found below).
Using small language models#
In some cases, "small" models can be an ideal choice for their efficiency, particularly for simpler, more direct tasks like summarization, classification, and translation. Here's how and why they fit into a multi-model system:
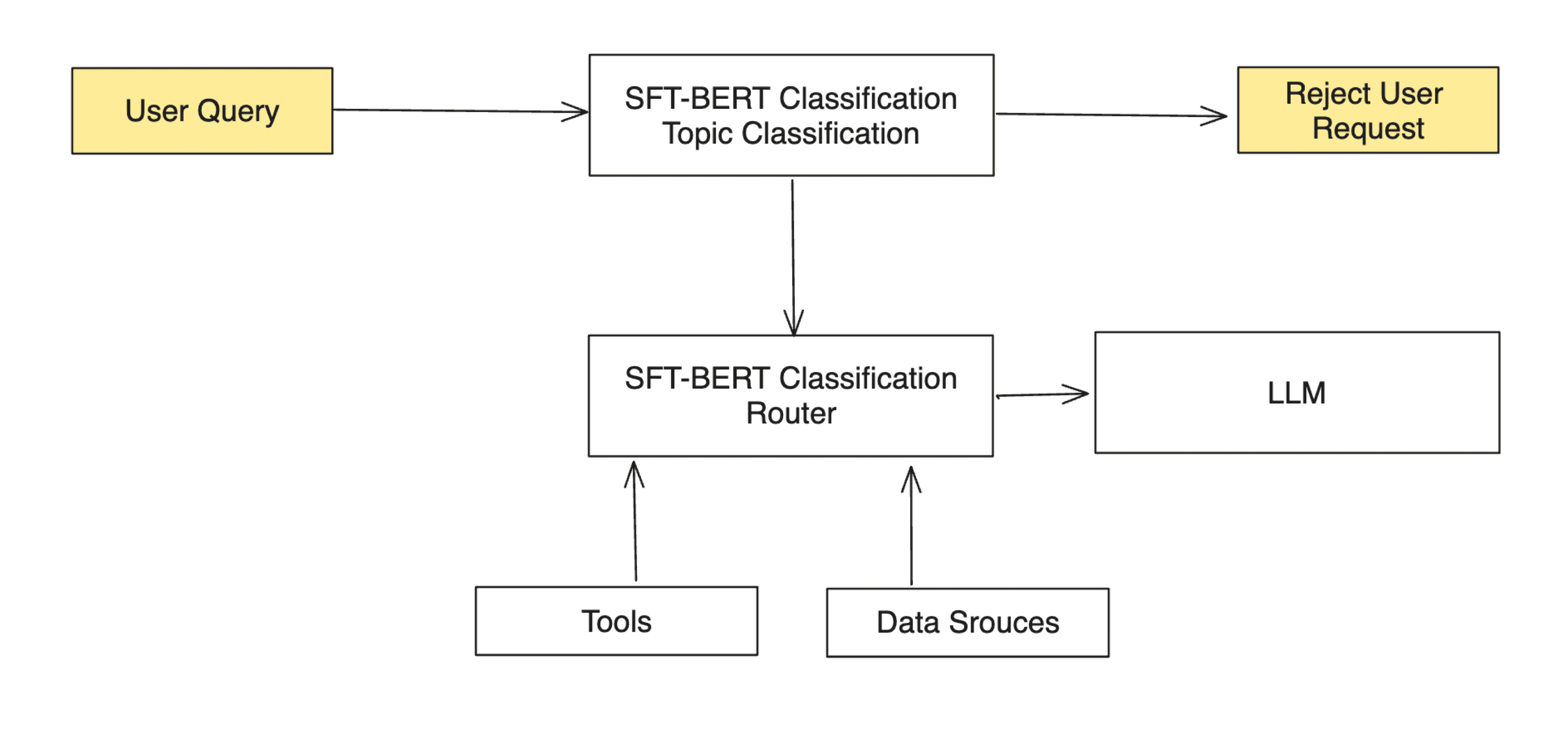
- Rapid response: For example, when a user query is submitted, a small model like BERT can swiftly determine if the request is inappropriate or toxic. If so, it can reject the query directly, conserving resources by avoiding the follow-up steps.
- Routing: These nimble models can act as request routers. Fine-tuned BERT-like model needs no more than 10 milliseconds to identify which tools or data sources are needed for a given request. By contrast, an LLM may need a few seconds or more to complete.
Uniting separate RAG components#
Running a RAG system with a large number of custom AI models on a single GPU is highly inefficient, if not impossible. Although each model could be deployed and hosted separately, this approach makes it challenging to iterate and enhance the system as a whole.
BentoML is optimized for building such serving systems, streamlining both the workflow from development to deployment and the serving architecture itself. Developers can encapsulate the entire RAG logic within a single Python application, referencing each component (like OCR, reranker, text embedding, and large language models) as a straightforward Python function call. The framework eliminates the need to build and manage distributed services, optimizing resource efficiency and scalability for each component. BentoML also manages the entire pipeline, packaging the necessary code and models into a single versioned unit (a "Bento"). This consistency across different application lifecycle stages drastically simplifies the deployment and evaluation process.

Note: In the next series of blog posts, we will dive into more details on how developers can leverage BentoML for model composition and serving RAG systems at scale. Stay tuned!
To summarize, here is how BentoML can help you build RAG systems:
- Define the entire RAG components within one Python file
- Compile them to one versioned unit for evaluation and deployment
- Adopt baked-in model serving and inference best practices like adaptive batching
- Assign each model inference components to different GPU shapes and scale them independently for maximum resource efficiency
- Monitor production performance in BentoCloud, which provides comprehensive observability like tracing and logging
For more information, refer to our RAG tutorials.
Conclusion#
Modern RAG systems often requires a large number of open-source and custom fine-tuned AI models for achieving the optimal performance. As we improve RAG systems with all these additional AI models, the complexity grows quickly, which not only slows down your development iterations, but also comes with a high cost in deploying and maintaining such a system in production.
At Bento, we help our customers build and serve compound AI systems like RAG with multiple models and components easily. Check out the following resources to learn more:
- Scaling AI Models Like You Mean It
- Choose the right deployment patterns for RAG: BYOC, multi-cloud and cross-region, on-prem and hybrid
- Sign up for our unified inference platform and deploy your first RAG system
- Join our community forum and schedule a call with our experts to get help