25x Faster Cold Starts for LLMs on Kubernetes
Authors


Last Updated
Share

You launched a Llama 3.1 8B container on Kubernetes, but it took 10 minutes to start. Why? Apparently, the container infrastructure was struggling under GenAI workloads.
A fast cold start is critical for ensuring your deployment can react quickly to traffic changes without large delays. By bringing up instances on-demand, you can scale dynamically and avoid over-provisioning compute capacity. This responsiveness reduces costs while maintaining a high level of service.
Recognizing this, we completely redesigned our LLM cold start strategy, from pulling images to loading model weights into GPU memory. Ultimately, we developed a solution that achieved 25x faster cold starts, with true on-demand model loading.
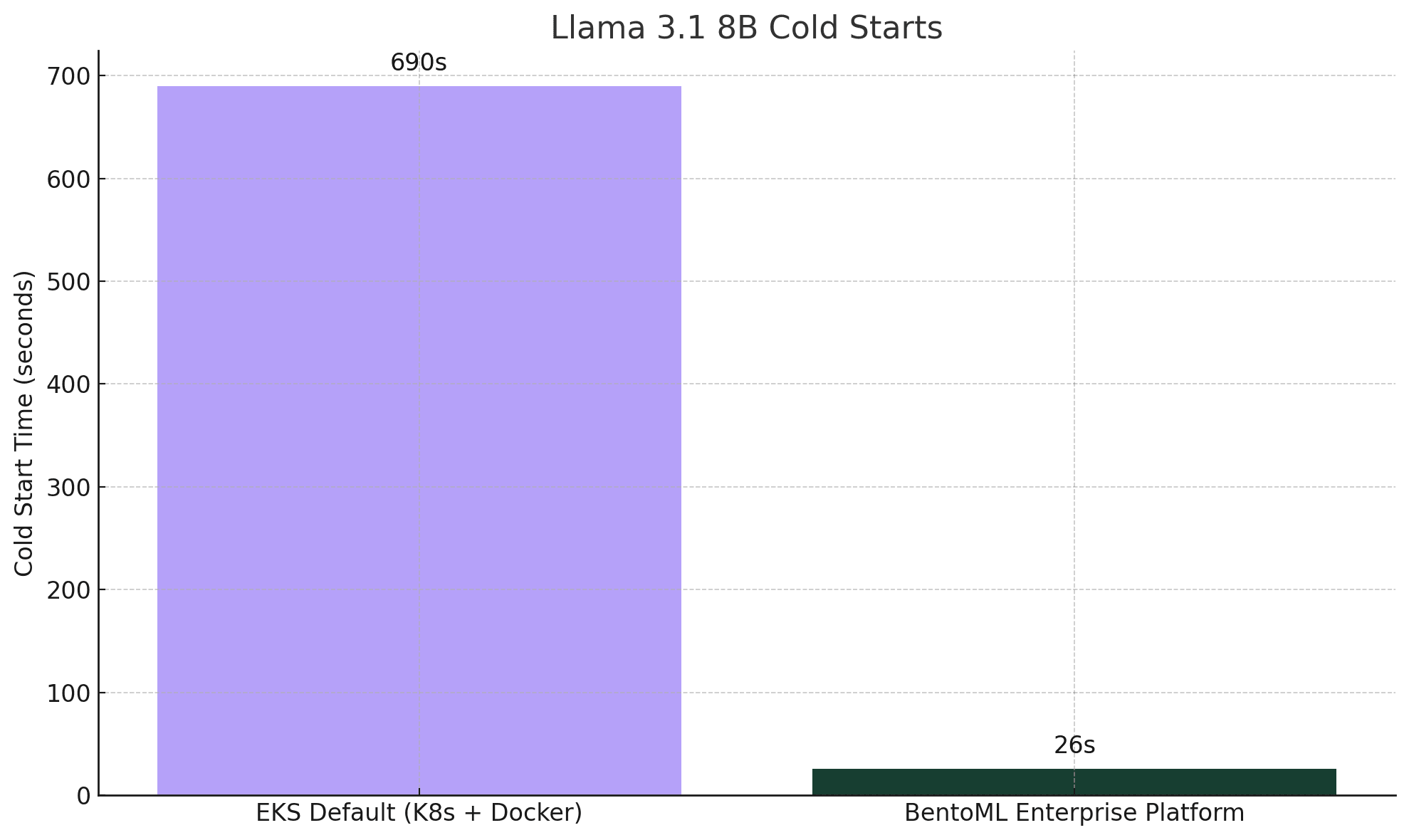
* The exact LLM cold start duration may vary depending on your network or disk bandwidth, GPU performance, and model size.
In this blog post, we will share the story of how we did it. First, let's look at some fundamental questions.
What does an LLM container include?#
Containers used for serving GenAI workloads are generally much larger than simple web app containers. For example, a Llama 3.1 8B container may include:
- CUDA: 2.8GB
- Torch: 1.4GB
- Other libs: 1GB
- Model weights: 15GB
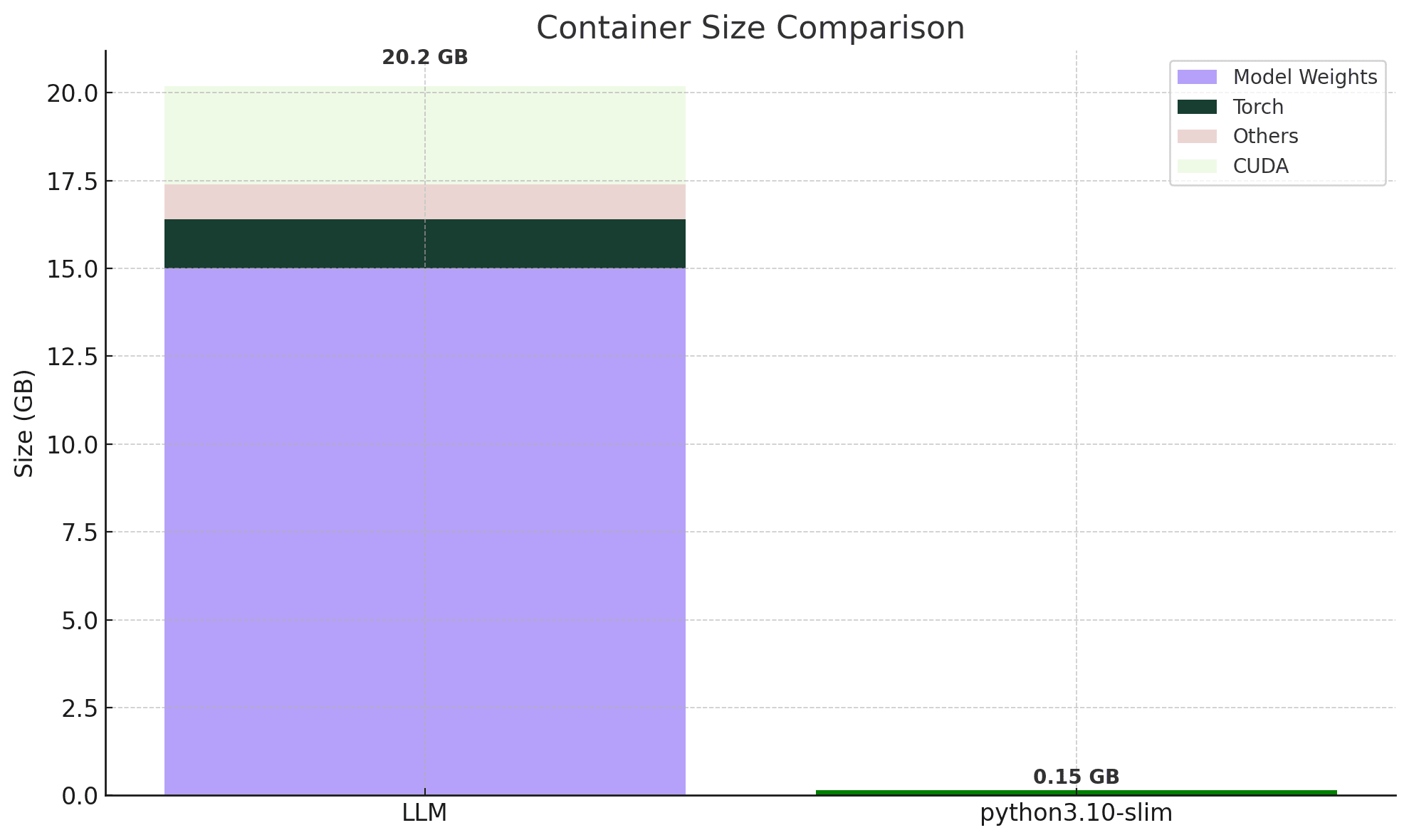
This brings the total size to 20.2 GB, and in many cases, even higher as the model grows in size. For comparison, a python3.10-slim container may be only around 154 MB.
What do cold and warm starts mean?#
In the context of LLM container deployment, a cold start means the Kubernetes node has never run this deployment before. Therefore, it doesn’t have the container image locally, and the image layers must be downloaded and initialized from scratch.
By contrast, a warm start means the node has previously loaded the model or built the container image. In this case, the container image is already cached on the node and the model files may be available in page cache.
What happens when starting an LLM container?#
A container image is made up of multiple compressed layers, and each of those layers is typically stored as a compressed tarball (e.g., gzip or zstd) in a registry (e.g., Docker Hub). Additionally, the image includes a JSON manifest listing its layers, base image, and configuration details.
This layered architecture, while efficient for version control and sharing common components, poses challenges when scaled to accommodate large AI models. Let's break down exactly what happens when an LLM container starts up on Kubernetes.
- Download: Pull all image layers from the registry.
- Extract: Decompress layers and write them to disk.
- Startup: Set up mounts, network, GPU access, and other configurations.
- Load model: Load weights into GPU memory.
For Llama 3.1 8B, the cold start timeline may look like this:
Deployment Timeline: Image Pull: 5–6 min ███████ Layer Extract: 3–4 min ████ Config & Start: ~2 min █ ───────────────────── Total: ~11 min
It's important to note that the delay is not caused by computation or inference, but simply by preparing the container to start.
What’s slowing down your LLM container?#
Now that we've covered the basics, let's dive deeper into the major bottlenecks that slow down LLM container startup.
1. Container registry and runtime#
Container registries and runtimes were originally designed for small images (e.g., web applications). They may face performance challenges with LLM inference workloads.
- Single-threaded transfers: Most registries serve image layers over a single HTTP connection. They don’t support multi-part or parallel chunked downloads, making large file downloads extremely slow.
- Sequential extraction: Once downloaded, layers are extracted one at a time, not in parallel, which limits overall throughput. The extraction step is typically CPU-bound as container layers use compression formats like
gziporzstd. A single 50GB model might require 5-8 minutes just for decompression on modern CPUs. - Copy-on-write tax: The CoW operations add overhead, particularly for large models, as the runtime needs to manage complex file mappings across multiple layers. This introduces additional disk I/O and slows down file access.
- All-or-nothing startup: A container can't start until all of its image layers have been downloaded and unpacked.
2. Storage driver limitations#
Most container storage drivers aren't suitable for handling large GenAI model files:
- Optimized for small files: Storage drivers are optimized for workloads with numerous small files such as binaries, libraries, and configuration files. They offer features like metadata caching and indexing. However, these optimizations provide minimal benefit for LLMs, which are often monolithic large files (e.g., many 5GB
.safetensorsfiles). - Double-write penalty: Layers are written twice, first in compressed form (stored in the registry cache), then again when extracted to the filesystem. This means a 15GB model temporarily requires 30GB of space, doubling disk write and increasing I/O loads.
3. Model loading inefficiencies#
LLMs introduces their unique challenges in how model files are transferred and loaded during deployment:
- Slow downloads from model hubs: Similar to container registries, model platforms like Hugging Face are not optimized for high-throughput multi-part downloads. This makes direct pulls of large model files time-consuming.
- Sequential model loading: Model data flows sequentially through multiple hops: remote storage → local disk → memory → GPU. There is minimal or no parallelization between the download, extraction, and disk-writing phases. Each step adds latency, especially when files are too large to efficiently cache or stream.
- No on-demand stream loading: Model files must be fully written to disk before inference can happen. This results in extra disk reads and writes, increasing I/O pressure and delaying startup.
These limitations combined can greatly prolong the startup process, even on high-bandwidth networks. Beyond delays, they create cascading problems: network saturation, disk I/O spikes, and increased infrastructure costs (due to over-provisioning resources to manage these inefficiencies).
Rethink image pulling and model loading#
To accelerate LLM container startup, we must fundamentally reconsider how container images are pulled and model weights are loaded.
Step 1: Ditch registries for object storage#
The first challenge was slow image download from container registries. Given their limitations mentioned above, we explored an alternative: pulling container images directly from object storage systems, such as Google Cloud Storage (GCS) and Amazon S3.
For the Llama 3.1 8B container, object storage proved dramatically faster as the image pull time dropped to around 10 seconds in our tests.
| Method | Speed (depending on machine/network) | Time |
|---|---|---|
| Cloud Registry Pull (GAR/ECR) | 60 MB/s | ~350s |
| Internal Registry Pull (Harbor) | 120 MB/s | ~170s |
| Direct GCS/S3 Download | 2 GB/s or higher | ~10s |
We attribute the speed improvements to:
- Parallel downloads: Object storage supports multi-part, parallel
Rangerequests, leveraging full network bandwidth. - No manifest processing: Object storage doesn't require parsing JSON manifests, authenticating each layer separately, or sequentially verifying layers. This means you can retrieve images directly as raw data.
Despite the faster download speeds, we noticed the extraction step significantly slowed things down, often cutting the overall effective throughput in half. Disk I/O during extraction remained a critical bottleneck.
That made the extraction step our next optimization target.
Step 2: Skip extraction with FUSE#
Our breakthrough came when we realized we could completely bypass extraction by rethinking how containers access their filesystem. This is where FUSE (Filesystem in Userspace) changes the game.
FUSE allows non-privileged users to create and mount custom filesystems without kernel-level code or root permissions. FUSE-based tools like stargz-snapshotter allow containers to access image data on-demand, without extracting all layers upfront. This avoids CPU-bound extraction and excessive disk I/O.
With FUSE, we refined our workflow featuring on-demand access of model data. Rather than extracting every layer to disk, we maintain image layers in an uncompressed, seekable-tar format in object storage. This allows containers to access them as a seekable, lazily loaded file database as if they were locally available, even though the underlying data may still reside remotely. This means containers can stream individual file chunks or data blocks from remote storage only when they actually need them.
Using the seekable-tar format as the foundation, we separated the model weights from the container image and enabled direct loading into GPU memory.
Step 3: Load models directly into GPU memory#
Without optimization, model weights are downloaded, written to disk, and then loaded into GPU memory. This is a slow process since it’s sequential and IO-intensive.
We streamlined this step by introducing zero-copy stream-based model loading. This means model files can be streamed directly from remote storage into GPU memory without intermediate disk reads and writes. With these optimizations, we achieved a 25x faster cold start time for Llama 3.1 8B. Note that the exact LLM cold start duration may vary depending on your network or disk bandwidth, GPU performance, and model size.
Conclusion#
Cutting LLM container cold starts is not only a technical optimization, but also a strategic advantage for your products. For businesses deploying LLMs, faster cold starts mean lower infrastructure costs, higher engineering flexibility, and improved user experiences.
By sharing our experience, we look to help others facing similar challenges in deploying large-scale AI workloads. We believe these techniques can benefit the broader AI engineering community, supporting more scalable and cost-effective LLM deployments on Kubernetes.
Check out the following resources to learn more:
- [Blog] Scaling AI Models Like You Mean It
- [Blog] 6 Infrastructure Pitfalls Slowing Down Your AI Progress
- Read our LLM Inference Handbook
- Join our community forum to get the latest information on building and deploying scalable AI systems
- Schedule a call with our experts to know more details about LLM cold starts
- Sign up for our inference platform to experience the fast cold starts. It allows you to deploy and scale AI models with production-grade reliability, without the infrastructure complexity.