Comparing BentoML and Vertex AI: Making Informed Decisions for AI Model Deployment
Authors


Last Updated
Share

As the demand for AI applications grows, deploying AI models into production requires careful consideration. In this blog post, we compare two platforms in this aspect: Vertex AI and BentoML. Vertex AI, as part of Google Cloud's ecosystem, offers a comprehensive suite of tools for the entire ML lifecycle, from training to deployment. BentoML, on the other hand, is a Unified Inference Platform for building and scaling AI systems with any model, on any cloud.
However, the definitions alone don’t give us the full picture. To help AI teams make informed decisions, we’ve put both platforms through some research and testing. Our analysis covers three keys areas of model deployment:
- Cloud infrastructure
- Scaling and performance
- Developer experience
Now let’s take a deep dive into them.
Cloud infrastructure#
When deploying AI models in production, several critical infrastructure considerations come into play.
Multi-cloud support#
The ability to deploy models across multiple cloud service providers (CSPs) ensures flexibility and prevents cloud vendor lock-in. It allows AI teams to choose the best provider based on their specific needs for cost, performance, or geographic location.
While BentoML supports deployment across various cloud providers, Vertex AI is naturally limited to the Google Cloud ecosystem.
GPUs#
AI workloads, especially LLMs, rely heavily on GPUs (or even TPUs) for high-performance inference. A flexible infrastructure should allow AI teams to choose the best GPUs based on availability, pricing, and performance requirements.
-
GPU availability and pricing:
- BentoML supports any GPU type from any cloud provider. It enables users to select different GPUs for various inference workloads and achieve the best cost-to-performance ratio.
- Vertex AI is limited to GPUs available on GCP, and GPU pricing is subject to GCP’s pricing structure.
-
GPU cloud support:
- BentoML allows GPUs from specialized GPU cloud providers like Lambda Labs and CoreWeave to join and serve models.
- Vertex AI only supports GPUs available within Google Cloud.
Security and compliance#
For enterprises, especially those in regulated industries, security compliance is non-negotiable. You must ensure your platform follows strict standards for data privacy and security to mitigate risks and meet regulatory requirements.
Both BentoML and Vertex AI are SOC2 compliant and support private VPC AI deployments.
Here is a high-level cloud infrastructure comparison:
| Item | BentoML | Vertex AI |
|---|---|---|
| Multi-cloud support | AWS, Azure, GCP, etc. | GCP only |
| GPU availability | Any GPU types from any CSP or GPU cloud | Only GPUs available on GCP |
| GPU pricing | Use GPUs with the most competitive pricing anywhere | Subject to GCP pricing |
| GPU cloud support | Lambda Labs, CoreWeave, etc. | No support |
| TPU support | Yes | Yes |
| SOC2 compliance | Yes | Yes |
| Model deployment in private VPC | Yes | Yes |
Scaling and performance#
Slow scaling can lead to increased latency and reduced throughput. This not only affects user experience but also significantly increases costs. This is because AI teams often need to over-provision resources to maintain acceptable performance during scaling events.
Scaling metrics#
Vertex AI implements resource utilization-based autoscaling, adjusting the number of replicas based on metrics like CPU and GPU utilization. However, for LLM workloads, GPUs can show high utilization even when they are not fully saturated. This inefficiency may result in inaccurate scaling, causing latency spikes and degraded throughput under peak loads.
BentoML adopts concurrency-based autoscaling, which scales replicas based on active requests (whether queued or being processed). This metric:
-
Precisely reflects the load on the system
-
Accurately calculates the desired replicas using the scaling formula
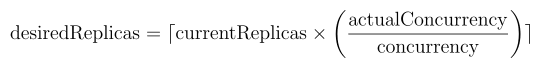
-
Is easy to configure based on simple load tests
Advanced scaling features#
Compared with Vertex AI, BentoML provides several advanced scaling capabilities:
-
Scale-to-zero: BentoML allows instances to shut down when idle, achieving cost efficiency by only using resources when needed.
-
Request queue: BentoML supports queuing incoming requests before dispatching them to serving instances. This prevents servers from being overwhelmed during traffic spikes, maximizes request success rates, and optimizes autoscaling effectiveness.
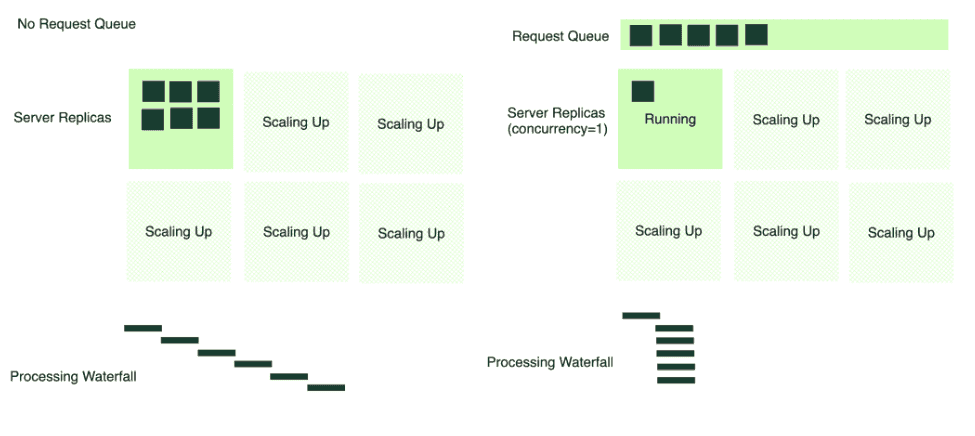
-
Standby instances:
- Vertex AI allows users to pre-provision resource pools to handle peak traffic loads and reduce cold start time.
- BentoML allows users to pre-provision cloud machines, keeping instances warm and ready to handle sudden demand surges. Stand-by instances are sharable by all deployed models during scale-up.
-
Custom stabilization windows: Users can precisely control how aggressively the system scales up or down for optimal effectiveness.
-
Async tasks: For AI models that require long-running computations, async tasks allow workloads to be processed in the background and results to be retrieved later. This is useful for handling use cases such as document processing or batch inference.
For more information, see Scaling AI Models Like You Mean It.
Cold start performance#
In our load tests with Llama 3.1 8B on an A100 GPU, we observed notable differences between the two platforms:
- Vertex AI took 148 seconds to start a replica.
- BentoML started a replica in 71 seconds, nearly twice as fast due to optimizations on BentoCloud.
Here is a high-level scaling and performance comparison:
| Item | BentoML | Vertex AI |
|---|---|---|
| Autoscaling | Request concurrency-based | Resource utilization-based |
| Scale-to-zero | Yes | No |
| Scaling behaviors | Custom stabilization window | No |
| Request queue | Yes | No |
| Cold start time | 71s | 148s |
| Stand-by instances | Yes | Yes |
| Async tasks | Yes | No |
Developer experience#
The developer experience directly impacts how quickly AI teams can move models from development to production. A smoother workflow reduces complexity, accelerates iteration, and makes it easier to optimize inference performance.
Pre-packaged models#
Both BentoML and Vertex AI provide a wide selection of pre-packaged models for easy deployment, like DeepSeek, Llama and Stable Diffusion model series.
Custom model inference#
How a platform handles model inference and deployment is a key factor in developer productivity:
-
BentoML lets developers focus entirely on defining model serving logic in Python without worrying about Docker images. It automatically does the following:
- Package the source code and environment specifications
- Build an OCI-compliant image
- Deploy the image on BentoCloud
-
Vertex AI also supports Python inference code, but it requires developers to manually handle containerization, including
- Packaging code and environment using Docker (or other similar tools)
- Uploading container images to Google Artifact Registry (GAR)
- Configuring deployment specifications according to Vertex AI requirements
This manual process requires deeper Docker knowledge and increases the time of moving models to production. BentoML simplifies this process, enabling a dev-to-prod transition in just minutes, while Vertex AI can take hours.
LLM inference#
Large language model (LLM) inference requires fine-tuned optimizations to balance latency, throughput, and cost efficiency.
-
Custom inference backends. Choosing the right inference backend for serving LLMs is crucial. It allows developers to make the right trade-offs to maximize performance based on their use case. For example:
- For online applications, you may prioritize lower latency by trading off throughput.
- For batch applications, the focus often shifts to higher throughput at the cost of latency.
Both platforms support popular inference backends like vLLM, TRT-LLM, and SGLang. The BentoML community provides ready-to-use examples that you can deploy directly or customize as needed. Vertex AI also supports these backends but requires developers to configure custom Docker images based on its specifications.
-
OpenAI-compatible. BentoML supports OpenAI-compatible endpoints. This is crucial for teams looking to integrate with applications that rely on OpenAI’s API schema. Vertex AI, however, has strict constraints on the input format of requests and exposes services through a unified service URL. This makes it difficult to provide OpenAI API compatibility.
Development sandbox#
BentoML provides Codespaces, a cloud development environment that lets developers to:
- Connect with their favorite IDE for seamless development
- Access powerful cloud GPUs like A100 to run inference
- Debug with immediate updates reflected on BentoCloud and view real-time logs
- Achieve consistent behaviors between development and production environments
For more information, see Accelerate AI Application Development with BentoML Codespaces.
Multi-model pipelining#
Modern AI applications, such as RAG and AI agents, often require multi-model workflows where multiple models work together to process and generate results.
BentoML simplifies multi-model orchestration with Service APIs, allowing developers to:
- Run models in sequence: One model’s output is directly passed as input to another.
- Run models in parallel: Multiple models process data simultaneously.
For more information, see multi-model composition and distributed Services.
Observability#
Effective observability helps monitor and optimize model performance and infrastructure usage.
Compared to Vertex AI, BentoML offers additional observability features, including LLM-specific performance metrics like time-to-first-token and prefix cache hit rate.
Here is a high-level developer experience comparison:
| Item | BentoML | Vertex AI |
|---|---|---|
| Pre-packaged models | Yes (Pre-built Bentos) | Yes (Model Garden) |
| Custom model inference | Python inference code |
|
| Dev-to-prod | Minutes | Hours |
| LLM inference |
| Hard to customize |
| Development sandbox | Codespaces | No support |
| Multi-model pipelining | Yes | No |
| Observability | Metrics:
Logs:
| Metrics:
Logs:
|
Choosing the right platform for your needs#
The right choice between Vertex AI and BentoML depends on your specific requirements and use cases.
When to choose Vertex AI#
Vertex AI is particularly useful for organizations that:
- Need an end-to-end ML platform for training, fine-tuning, and deployment
- Are heavily invested in the GCP ecosystem and require seamless integration with other GCP services
- Have established DevOps teams comfortable with container management
When to choose BentoML#
BentoML is the better choice if you:
- Focus primarily on model serving and deployment efficiency
- Need multi-cloud flexibility
- Want to minimize time from development to production
- Want a Docker-free workflow for faster iterations
- Need better cold start performance and scale-to-zero capability
- Need multi-model orchestration and complex pipeline implementation for applications like RAG, AI agents, or custom workflows
Final thoughts#
Consider your team's expertise, existing infrastructure, and specific use cases when making your decision. Both platforms continue to evolve, adding new features and capabilities to meet the growing demands of AI deployment in production.
Check out the following resources to learn more: