Creating Stable Diffusion 2.0 Services With BentoML And Diffusers
Authors

Last Updated
Share

⚠️ Outdated content#
Note: The content in this blog post may not be applicable any more. To deploy diffusion models, see the BentoML documentation.
In this post, we will guide you through the integration process between the BentoML and Diffusers libraries. By using Stable Diffusion 2.0 as a case study, you can learn how to build and deploy a production-ready Stable Diffusion service. Stable Diffusion 2.0 includes several new features, such as higher resolution (e.g., 768x768 output), a depth-guided stable diffusion model called depth2img, a built-in 4x upscaler model, and much more. More importantly, you will gain a hands-on understanding of how to harness the power of these two libraries to build and deploy robust, scalable, and efficient diffusion models in a production environment.

A generated image from Stable Diffusion 2.0 served with Diffusers and BentoML with the following prompts.
Prompt: Kawaii low poly grey American shorthair cat character, 3D isometric render, ambient occlusion, unity engine, lively color
Negative prompt: low-res, blurry, mutation, deformed
Why Diffusers#
The Diffusers library by HuggingFace is a powerful tool for accessing and utilizing pertained diffusion models in Python. Focused on ease of use, the library comes equipped with multiple diffusion pipelines that can be executed with just a few lines of code, allowing users to get started quickly and efficiently. Different implementations and versions of models can be easily swapped because the Diffusers library tries to unify the interface of common diffusion models. We can even use audio generation model with similar workflows using Diffusers. Lastly, Diffusers community provides ready-to-use custom pipelines which will extend the functionality of standard Stable Diffusion pipelines.
Why BentoML#
Integrating Diffusers with BentoML makes it an even more valuable tool for real-world deployments. With BentoML, users can easily package and serve diffusion models for production use, ensuring reliable and efficient deployments. BentoML comes equipped with out-of-the-box operation management tools like monitoring and tracing, and offers the freedom to deploy to any cloud platform with ease.
Tutorial#
Detailed code and instructions of following tutorial can be found under BentoML’s Diffusers Example project.
Preparing Dependencies#
We recommend running Stable Diffusion services on a machine equipped with a Nvidia GPU with CUDA Toolkit installed. Let's first make a virtual environment and install the necessary dependencies.
python3 -m venv venv source venv/bin/activate pip install bentoml diffusers transformers accelerate
To access some models, you may need to log in with a Hugging Face account. You can sign in to your account and get your User Access Token. Then install huggingface-hub and run the login command.
pip install -U huggingface_hub huggingface-cli login
Importing A Diffusion Model#
It's super easy to import a diffusion model to the BentoML model store using the model's identifier.
import bentoml bentoml.diffusers.import_model( "sd2", "stabilityai/stable-diffusion-2", )
This code snippet will download the Stable Diffusion 2 model from the HuggingFace Hub (or use the cached download files if the model is already downloaded before) and import it into the BentoML model store with the name sd2.
If you have an already fine-tuned model on disk, you can also provide the path instead of model identifier.
import bentoml bentoml.diffusers.import_model( "sd2", "./local_stable_diffusion_2/", )
Any diffusion models supported by diffusers can be imported. For example, the following code will import Linaqruf/anything-v3.0 instead of stabilityai/stable-diffusion-2.
import bentoml bentoml.diffusers.import_model( "anything-v3", "Linaqruf/anything-v3.0", )
Turning A Diffusion Model To A RESTful Service Using BentoML#
A text2img service using Stable Diffusion 2.0 can be implemented like the following assuming sd2 is the model name of imported Stable Diffusion 2.0 model.
import torch from diffusers import StableDiffusionPipeline import bentoml from bentoml.io import Image, JSON, Multipart bento_model = bentoml.diffusers.get("sd2:latest") stable_diffusion_runner = bento_model.to_runner() svc = bentoml.Service("stable_diffusion_v2", runners=[stable_diffusion_runner]) @svc.api(input=JSON(), output=Image()) def txt2img(input_data): res = stable_diffusion_runner.text2img.run(**input_data) images = res[0] return images[0]
Save the codes as service.py, then we can spin up a BentoML service endpoint.
bentoml serve service:svc --production
An HTTP server with /txt2img endpoint that accept a JSON dictionary should be up at port 3000. Go to http://127.0.0.1:3000 in your web browser to access the Swagger UI.
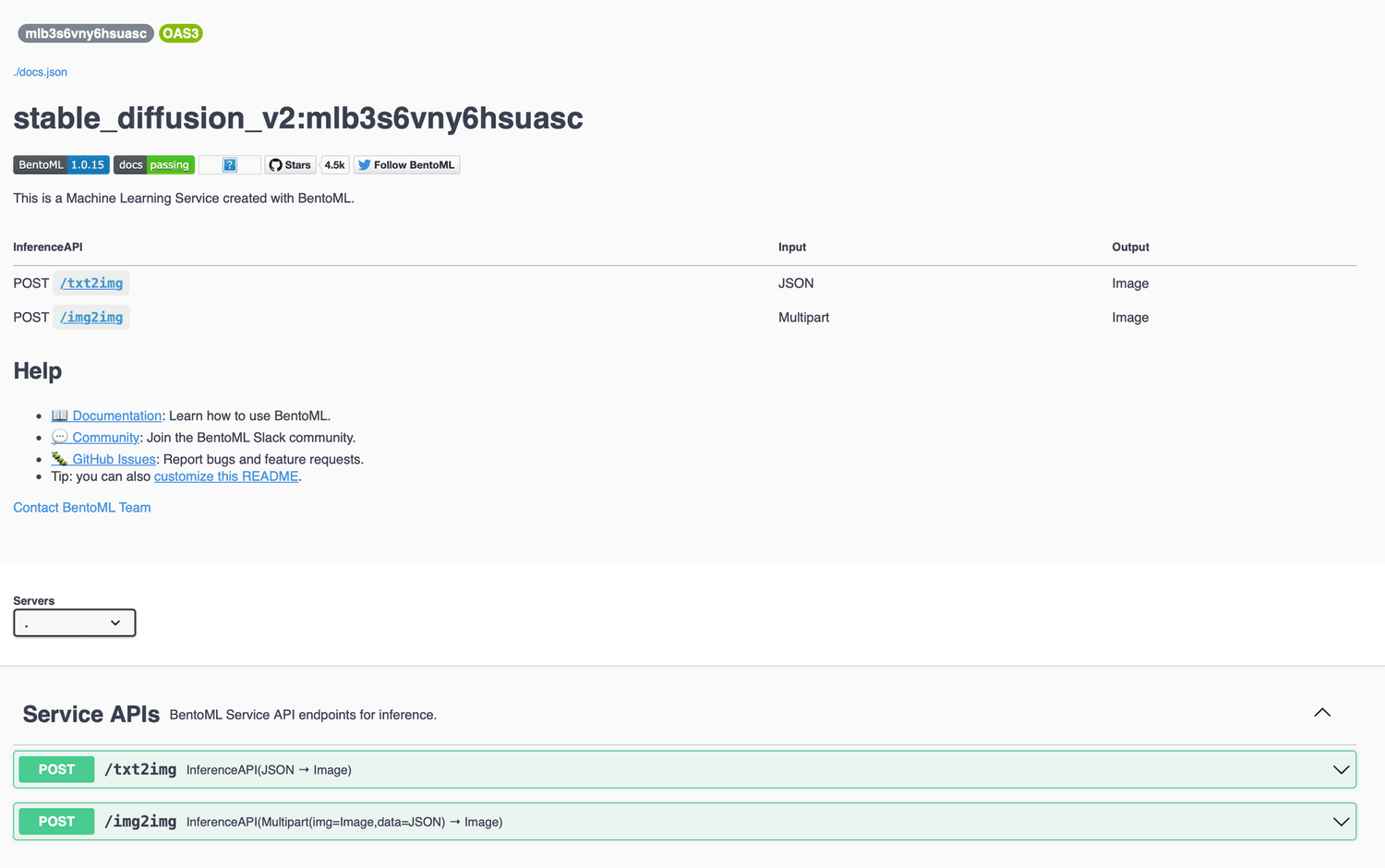
Or you can test the text-to-image generation using curl and write the returned image to output.jpg.
curl -X POST http://127.0.0.1:3000/txt2img -H 'Content-Type: application/json' -d "{\"prompt\":\"a black cat\"}" --output output.jpg
You can add more parameters of text to image generation inside the JSON dictionary. The following input will generate a 768x768 image.
curl -X POST http://127.0.0.1:3000/txt2img \ -H 'Content-Type: application/json' \ -d "{\"prompt\":\"a black cat\", \"height\":768, \"width\":768}" \ --output output.jpg
Using another diffusion model is simple by just changing the model name if the model has been previously imported. For example, instead of sd2, an anything v3.0 service can be created by changing the model name to anything-v3.
bento_model = bentoml.diffusers.get("anything-v3:latest") anything_v3_runner = bento_model.to_runner() svc = bentoml.Service("anything_v3", runners=[anything_v3_runner]) @svc.api(input=JSON(), output=Image()) def txt2img(input_data): images, _ = anything_v3_runner.run(**input_data) return images[0]
You can try the same curl command we used for Stable Diffusion 2.0 service and the generated result will have a very different style.
bentoml.diffusers also support diffusers' Custom Pipelines. This is especially handy if you want a service that can handle both txt2img and img2img using one pipeline which may save VRAM of your GPU. The official Diffusers pipeline does not support this feature, but the community offers a ready-to-use pipeline called “Stable Diffusion Mega” that does include it. To use this pipeline, we need to import diffusion model a little bit differently.
import bentoml bentoml.diffusers.import_model( "sd2", "stabilityai/stable-diffusion-2", signatures={ "__call__": { "batchable": False }, "text2img": { "batchable": False }, "img2img": { "batchable": False }, "inpaint": { "batchable": False }, } )
This code will tell BentoML that the diffusion model has other methods (e.g. text2img) besides __call__. After re-importing the model, we can have a service that can run both text-to-image generation and image-to-image generation.
import torch from diffusers import DiffusionPipeline import bentoml from bentoml.io import Image, JSON, Multipart bento_model = bentoml.diffusers.get("sd2:latest") stable_diffusion_runner = bento_model.with_options( pipeline_class=DiffusionPipeline, custom_pipeline="stable_diffusion_mega", ).to_runner() svc = bentoml.Service("stable_diffusion_v2", runners=[stable_diffusion_runner]) @svc.api(input=JSON(), output=Image()) def txt2img(input_data): images, _ = stable_diffusion_runner.text2img.run(**input_data) return images[0] img2img_input_spec = Multipart(img=Image(), data=JSON()) @svc.api(input=img2img_input_spec, output=Image()) def img2img(img, data): data["image"] = img images, _ = stable_diffusion_runner.img2img.run(**data)
Accelerating Generation With Xformers#
xformers is a PyTorch based library which hosts flexible and well optimized Transformers building blocks. Via Diffusers, bentoml.diffusers has integration with xformers to speed up diffusion models when possible. A bentoml.diffusers service will detect if xformers is installed at start up and use it to accelerate the generation process automatically.
pip install xformers triton
Rerun bentoml serve service:svc --production in an earlier step, the generation time for a single image should be faster compared to before. In our test, simply installing xformers will speed up the generation efficiency from 7.6 it/s to 9.0 it/s running on a single RTX 3060. The optimization will work even better on a more powerful GPU like A100.
Conclusion#
The combination of the Diffusers library and its integration with BentoML provides a powerful and practical solution for deploying diffusion models in production, whether you are a seasoned data scientist or just starting out.
Are you passionate about solving challenging problems like this? BentoML is seeking talented engineers to join our global team. If you have a strong background in engineering and a desire to make an impact in the AI industry, we would love to hear from you.