Building and Deploying A Sentence Embedding Service with BentoML
Authors

Last Updated
Share

⚠️ Outdated content#
Note: The content in this blog post is not applicable any more. Please refer to the BentoML documentation to learn how to build a sentence embedding service.
Embeddings in the context of AI and machine learning are a way to convert words, sentences, or images into numbers that the computer can understand and work with. Embeddings are super useful because they allow computers to do things like recommending a product that is similar to what you're looking at, translating languages, or finding a photo that you're searching for, by understanding the “meaning” behind the words or images.
In this blog post, let’s see how we can use BentoML to build a sentence embedding service, deploy it on BentoCloud, and try the autoscaling feature of the serverless platform.
Before you begin#
Do the following to set up your environment and get familiar with the project.
-
Clone the project directory to your local machine.
git clone https://github.com/bentoml/sentence-embedding-bento.git cd sentence-embedding-bento -
In the
sentence-embedding-bentofolder, inspect the following key files:import_model.py: Downloads and saves both the all-MiniLM-L6-v2 model and its tokenizer to the BentoML Model Store. It is a sentence-transformers model used to generate sentence embeddings. You can change it to other models based on your needs.requirements.txt: Required dependencies for this project.service.py: Creates a BentoML Service using the custom Runner created fromSentenceEmbeddingRunnableinembedding_runnable.py. It defines the API Server, including the endpoints, the input and output formats, and how the input data is processed to produce the output.embedding_runnable.py: Creates theSentenceEmbeddingRunnableclass, which is responsible for executing the embedding process and can run either on CPU or GPU settings. In this class, theencodemethod tokenizes input sentences and computes their embeddings using the model, followed by mean pooling to generate a single embedding vector per sentence; themean_poolingmethod aggregates the token embeddings into sentence embeddings by calculating the weighted average of token embeddings, considering the attention mask.bentofile.yaml/bentofile-gpu.yaml: The configurations used to build the entire project into the standardized distribution format in the BentoML ecosystem, also known as a Bento.
-
Install the required dependencies.
pip install -U -r ./requirements.txt
Testing the BentoML Service locally#
Before you build the Bento for the project, it is always a good practice to test it locally.
-
Download both the model and the tokenizer.
python import_model.py -
Verify that the download is successful:
$ bentoml models list Tag Module Size Creation Time all-minilm-l6-v2-tokenizer:4qiuicecdoxilr2d bentoml.transformers 923.78 KiB 2023-11-13 11:58:00 all-minilm-l6-v2:4qiuibucdoxilr2d bentoml.transformers 86.66 MiB 2023-11-13 11:57:59 -
Start the BentoML Service.
$ bentoml serve 2023-11-14T09:28:56+0000 [INFO] [cli] Environ for worker 0: set CUDA_VISIBLE_DEVICES to 0 2023-11-14T09:28:56+0000 [INFO] [cli] Prometheus metrics for HTTP BentoServer from "." can be accessed at http://localhost:3000/metrics. 2023-11-14T09:28:57+0000 [INFO] [cli] Starting production HTTP BentoServer from "." listening on http://0.0.0.0:3000 (Press CTRL+C to quit)The server should be active at http://0.0.0.0:3000. Visit the Swagger Web UI or send a request using
curl:curl -X POST http://0.0.0.0:3000/encode \ -H 'Content-Type: application/json' \ -d '["The dinner was great!", "The weather is great today!"]' -
The expected output should be two arrays of numerical vectors, which represent the embeddings of the input sentences. As I mentioned at the beginning of this article, you can use these embeddings for various NLP tasks. One common use case is to measure how semantically similar two sentences are. For example, you can calculate the cosine similarity between vectors by running the following script.
from bentoml.client import Client from sklearn.metrics.pairwise import cosine_similarity # Replace SERVER_URL with the actual URL where the BentoML Service is running SERVER_URL = 'http://0.0.0.0:3000' client = Client.from_url(SERVER_URL) # Sentences you want to encode samples = [ "The dinner was great!", "The weather is great today!" ] # Get the embeddings of sentences embeddings = client.encode(samples) print(embeddings) # Calculate the cosine similarity between the two sentences similarity_score = cosine_similarity([embeddings[0]], [embeddings[1]]) print(f'Similarity between "The dinner was great!" and "The weather is great today!": {similarity_score[0][0]}')The cosine similarity computes the cosine of the angle between these two vectors, which is between -1 and 1. If it is close to 1, it means the angle between the vectors is small, and the sentences are similar to each other; if it is close to 0, the angle is 90 degrees, and the sentences are not particularly similar or dissimilar; if it is close to -1, the sentences are dissimilar. Expected output:
[[-2.07822517e-01 5.71613014e-01 -1.27916634e-01 2.08999634e-01 ... 1.83093995e-01 5.10414779e-01 -5.43786228e-01 -5.38906530e-02] [-1.11607194e-01 4.37176824e-01 8.07149529e-01 2.87656963e-01 ... -1.63743228e-01 -7.69225806e-02 -7.08881676e-01 5.30457318e-01]] Similarity between "The dinner was great!" and "The weather is great today!": 0.35989971339579474
Building and pushing the Bento#
Once you are happy with the performance of the model, package it and all the associated files and dependencies into a Bento and push it to BentoCloud.
-
Run
bentoml buildunder thesentence-embedding-bentodirectory.$ bentoml build Converting 'all-MiniLM-L6-v2' to lowercase: 'all-minilm-l6-v2'. Converting 'all-MiniLM-L6-v2-tokenizer' to lowercase: 'all-minilm-l6-v2-tokenizer'. 'labels' should be a dict[str, str] and enforced by BentoML. Converting all values to string. ██████╗ ███████╗███╗ ██╗████████╗ ██████╗ ███╗ ███╗██╗ ██╔══██╗██╔════╝████╗ ██║╚══██╔══╝██╔═══██╗████╗ ████║██║ ██████╔╝█████╗ ██╔██╗ ██║ ██║ ██║ ██║██╔████╔██║██║ ██╔══██╗██╔══╝ ██║╚██╗██║ ██║ ██║ ██║██║╚██╔╝██║██║ ██████╔╝███████╗██║ ╚████║ ██║ ╚██████╔╝██║ ╚═╝ ██║███████╗ ╚═════╝ ╚══════╝╚═╝ ╚═══╝ ╚═╝ ╚═════╝ ╚═╝ ╚═╝╚══════╝ Successfully built Bento(tag="sentence-embedding-svc:jnktnfuc2ssnng7u"). Possible next steps: * Containerize your Bento with `bentoml containerize`: $ bentoml containerize sentence-embedding-svc:jnktnfuc2ssnng7u [or bentoml build --containerize] * Push to BentoCloud with `bentoml push`: $ bentoml push sentence-embedding-svc:jnktnfuc2ssnng7u [or bentoml build --push]Note: If you are running the project on GPU devices, you can use the bentofile-gpu.yaml file to build the Bento.
-
Make sure you have already logged in to BentoCloud, then push the Bento to the serverless platform. This way, you can better deploy the sentence embedding service in production with enhanced features like automatic scaling and observability.
bentoml push sentence-embedding-svc:latestNote: If you don’t have access to BentoCloud, you can also run
bentoml containerize sentence-embedding-svc:latestto create a Bento Docker image, and then deploy it to any Docker-compatible environment. -
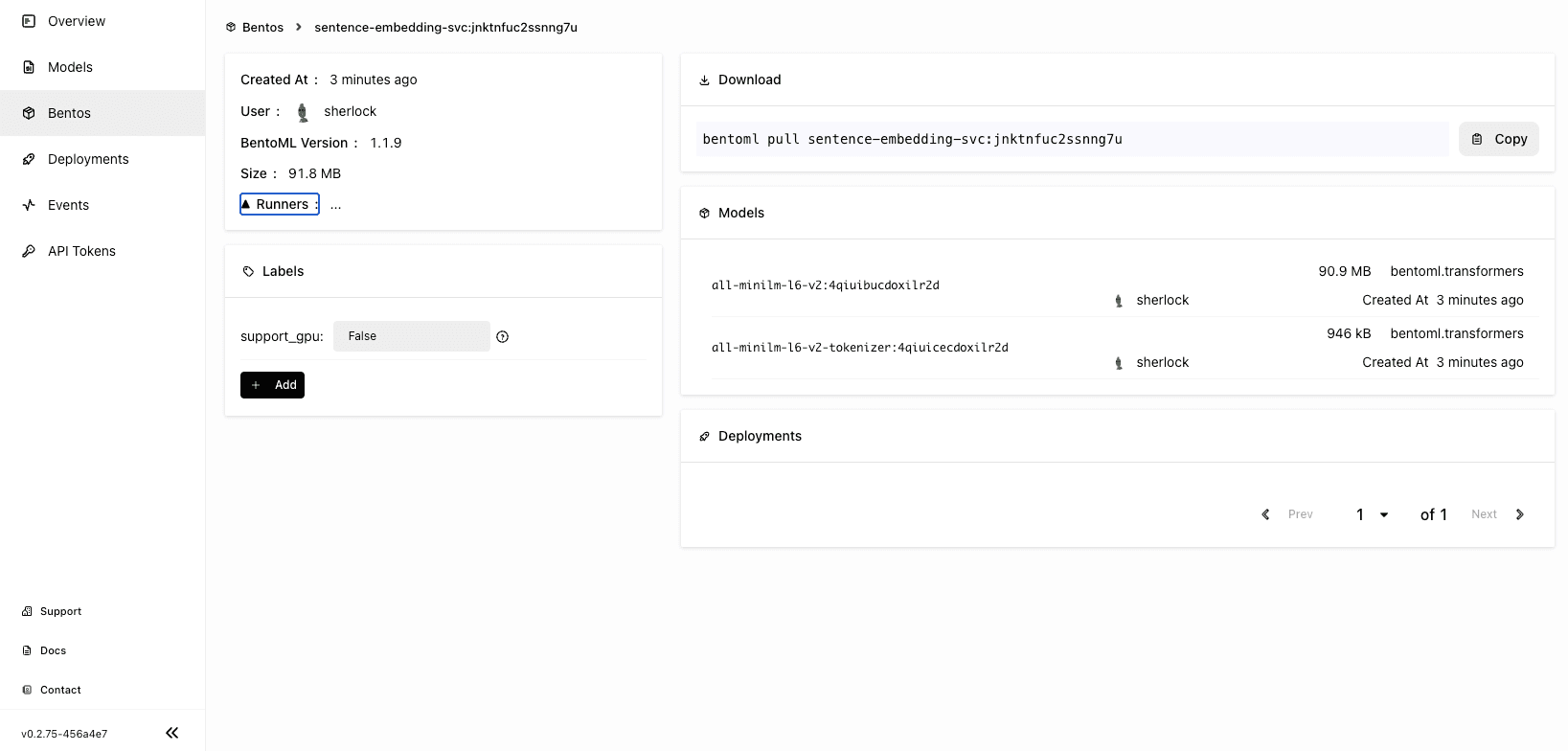
On the BentoCloud console, you can find the uploaded Bento on the Bentos page in the sentence-embedding-svc Bento repository. Each Bento repository contains a set of Bentos of different versions for the same ML service.
Deploying the Bento#
With the Bento pushed to BentoCloud, you can start to deploy it.
-
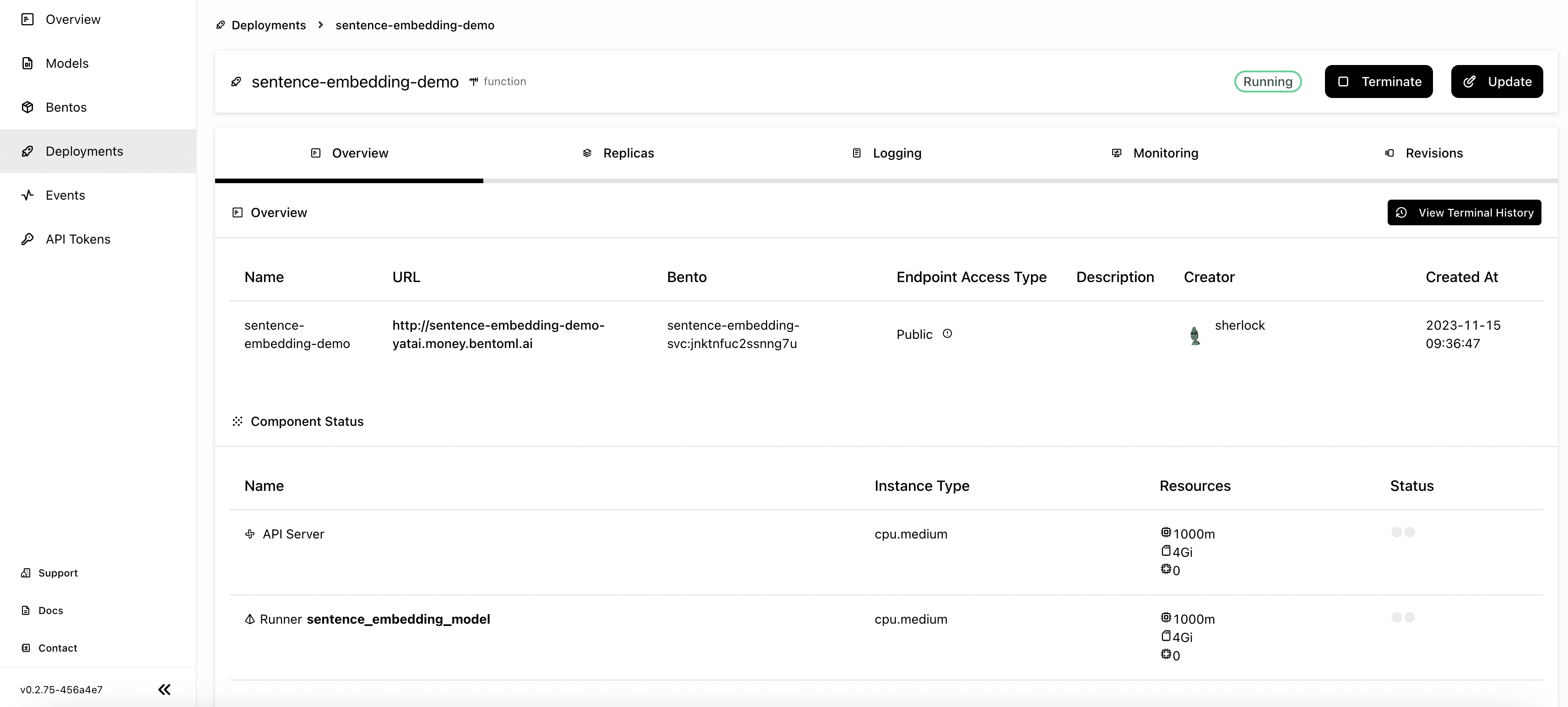
Navigate to the Deployments page and click Create.
-
Select On-Demand Function, which is useful for scenarios with loose latency requirements and sparse traffic.
-
Specify the required fields for the Deployment. This application does not require heavy resources, so I selected cpu.medium for both the API Server and Runner Pods. In addition, I set the minimum number of replicas allowed for scaling to 0, so there shouldn’t be any active Pods when there is no traffic.
-
You can directly access the exposed URL to interact with the application. Alternatively, use the same script but this time add a loop to create some traffic for monitoring. For example:
from bentoml.client import Client from sklearn.metrics.pairwise import cosine_similarity import time # Replace SERVER_URL with the actual URL where your BentoML Service is running SERVER_URL = 'http://sentence-embedding-demo-yatai.money.bentoml.ai' client = Client.from_url(SERVER_URL) # Sentences you want to encode samples = [ "The dinner was great!", "The weather is great today!" ] while True: # Get the embeddings of sentences embeddings = client.encode(samples) print(embeddings) # Calculate the cosine similarity between the two sentences similarity_score = cosine_similarity([embeddings[0]], [embeddings[1]]) print(f'Similarity between "The dinner was great!" and "The weather is great today!": {similarity_score[0][0]}') # Wait for 20 seconds before next execution time.sleep(20) -
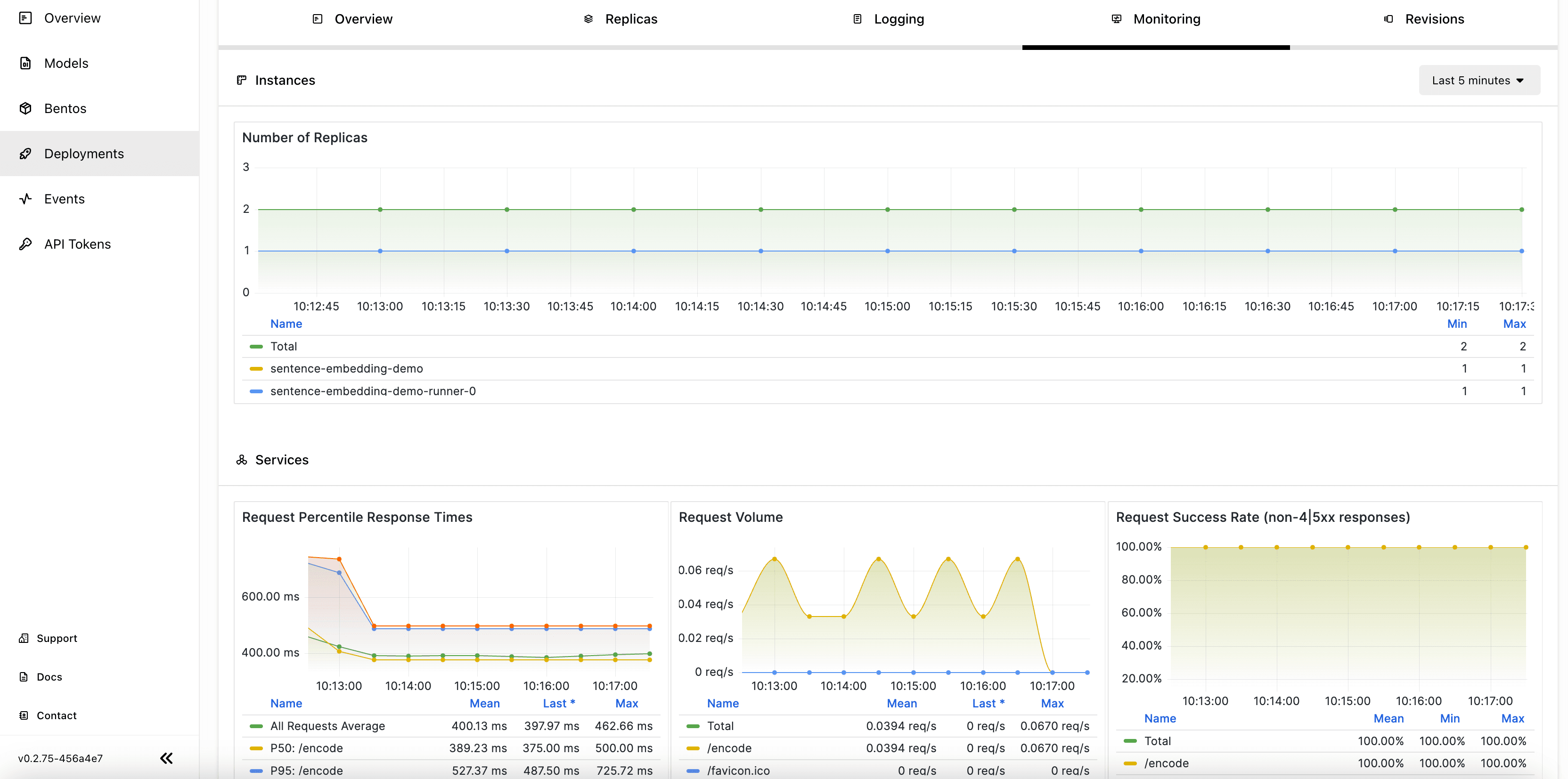
After you run the above script to send requests, you may not see the result immediately as the application needs some time to scale both the API Server and the Runner. On the Overview tab, you should be able to see at least one active replica of the API Server and the Runner when you get the response.

-
View the related metrics on the Monitoring tab.
Conclusion#
We've seen how BentoML simplifies the journey of a sentence embedding service from development to deployment. With its smooth integration with BentoCloud, you can easily scale and monitor your AI application. This empowers developers to deploy NLP models efficiently, bringing AI applications closer to their full potential. In the next blog post, I will demonstrate how to build and deploy an image embedding application with BentoML.
More on BentoML#
To learn more about BentoML and its ecosystem tools, check out the following resources:
- [Blog] Deploying Code Llama in Production with OpenLLM and BentoCloud
- [Blog] From Models to Market: What's the Missing Link in Scaling Open-Source Models on Cloud?
- [Blog] BYOC to BentoCloud: Privacy, Flexibility, and Cost Efficiency in One Package
- Don’t miss out on the chance to be an early adopter! BentoCloud is still open for early sign-ups. Experience a serverless platform tailored to simplify the building and management of your AI applications, ensuring both ease of use and scalability.