Deploying Code Llama in Production with OpenLLM and BentoCloud
Last Updated
Share

⚠️ Outdated content#
Note: The content in this blog post is not applicable any more. Please see the OpenLLM readme to learn more information about OpenLLM.
In August, Meta released a new AI tool for coding, Code Llama. Built on top of Llama 2, Code Llama is a state-of-the-art programming-centric language model, refined with intensive training on code-specific datasets. Available in three sizes (7B, 13B & 34B), it excels at code generation, completion, and debugging across several popular languages like Python and C++. It shares the same community license as Llama 2 and is available commercially, which provides a significant boon for software engineers seeking to increase productivity by automating mundane tasks such as code annotation and unit test creation. However, this innovation brings the challenge of deploying and scaling such sophisticated models in production, necessitating efficient and easy-to-use deployment tools.
OpenLLM is an open-source tool in the BentoML ecosystem specifically designed to deploy LLMs in production, supporting a wide range of models like Llama 2, Falcon, Dolly, and Flan-T5. With a single command, you can easily spin up an LLM server locally. For production deployment, you can build a Bento with OpenLLM and push it to BentoCloud, a serverless solution for AI application deployment and management. BentoCloud provides the following highlighted features.
- Scalability. AI applications can scale automatically based on incoming traffic, supporting scaling to zero during idle time.
- Serverless. Working with a serverless solution means you don’t need to worry about the underlying infrastructure and can only focus on AI application development. You only need to pay for the resources you use.
- Observability. BentoCloud provides a set of built-in graphs featuring key metrics of your Bento workloads, like request volume, success rate, GPU/CPU/memory usage, and more. You can also search for logs for debugging and troubleshooting.
- Collaboration. Bento and model repositories on BentoCloud allow different team members to easily share, download, and iterate AI assets on the cloud.
OpenLLM and BentoCloud combined can make AI application deployment easy, scalable, cost-efficient, and controllable. In this blog post, we will walk you through the steps to launch a production-ready Code Llama application using OpenLLM and BentoCloud.
Before you begin#
Make sure the following prerequisites are met.
- Install Python 3.8 (or higher versions) and
pip. We highly recommend using a virtual environment to avoid package conflicts. - Have a BentoCloud account.
- Access to the official Code Llama. You need to visit the Meta AI website to accept its licensing terms. However, if you're unable to access the official model, any Code Llama variant can be deployed using OpenLLM. Explore more compatible models on the Hugging Face Model Hub.
Installing OpenLLM#
Run the following command to install OpenLLM.
pip install openllm
To verify OpenLLM has been successfully installed, you can run the following command.
$ openllm -h Usage: openllm [OPTIONS] COMMAND [ARGS]... ██████╗ ██████╗ ███████╗███╗ ██╗██╗ ██╗ ███╗ ███╗ ██╔═══██╗██╔══██╗██╔════╝████╗ ██║██║ ██║ ████╗ ████║ ██║ ██║██████╔╝█████╗ ██╔██╗ ██║██║ ██║ ██╔████╔██║ ██║ ██║██╔═══╝ ██╔══╝ ██║╚██╗██║██║ ██║ ██║╚██╔╝██║ ╚██████╔╝██║ ███████╗██║ ╚████║███████╗███████╗██║ ╚═╝ ██║ ╚═════╝ ╚═╝ ╚══════╝╚═╝ ╚═══╝╚══════╝╚══════╝╚═╝ ╚═╝. An open platform for operating large language models in production. Fine-tune, serve, deploy, and monitor any LLMs with ease. Options: -v, --version Show the version and exit. -h, --help Show this message and exit. Commands: build Package a given models into a Bento. embed Get embeddings interactively, from a terminal. import Setup LLM interactively. instruct Instruct agents interactively for given tasks, from a... models List all supported models. prune Remove all saved models, (and optionally bentos) built with... query Ask a LLM interactively, from a terminal. start Start any LLM as a REST server. start-grpc Start any LLM as a gRPC server. Extensions: build-base-container Base image builder for BentoLLM. dive-bentos Dive into a BentoLLM. get-containerfile Return Containerfile of any given Bento. get-prompt Get the default prompt used by OpenLLM. list-bentos List available bentos built by OpenLLM. list-models This is equivalent to openllm models... playground OpenLLM Playground.
Launching a Code Llama server#
Run the following command to launch your Code Llama service locally. The server should be active at http://0.0.0.0:3000/. You can send a request to it via curl or use the swagger UI. More explanations will be provided later regarding how to interact with the server.
openllm start codellama/CodeLlama-7b-Instruct-hf
Note: OpenLLM downloads the model to the BentoML Model Store if it is not available locally. To view your local models, run bentoml models list. It may take some time to complete depending on your network conditions.
Code Llama has three available sizes with three flavors: base model, Python fined-tuned, and instruction tuned. The above command starts a server using the codellama/CodeLlama-7b-Instruct-hf model, which is capable of code completion, infilling, following instructions, and chatting. You can choose other models based on your needs.
Building a Code Llama Bento#
Run the following command to build a Bento, the standardized distribution format in the BentoML ecosystem. In this case, it contains all the components necessary to run inference on the Code Llama model, including the model, Service API, Python packages, and dependencies.
openllm build codellama/CodeLlama-7b-Instruct-hf
Expected output:
Building Bento for 'llama' BentoML will not install Python to custom base images; ensure the base image 'public.ecr.aws/y5w8i4y6/bentoml/openllm:0.3.13' has Python installed. ██████╗ ██████╗ ███████╗███╗ ██╗██╗ ██╗ ███╗ ███╗ ██╔═══██╗██╔══██╗██╔════╝████╗ ██║██║ ██║ ████╗ ████║ ██║ ██║██████╔╝█████╗ ██╔██╗ ██║██║ ██║ ██╔████╔██║ ██║ ██║██╔═══╝ ██╔══╝ ██║╚██╗██║██║ ██║ ██║╚██╔╝██║ ╚██████╔╝██║ ███████╗██║ ╚████║███████╗███████╗██║ ╚═╝ ██║ ╚═════╝ ╚═╝ ╚══════╝╚═╝ ╚═══╝╚══════╝╚══════╝╚═╝ ╚═╝ Successfully built Bento(tag="codellama--codellama-7b-instruct-hf-service:65515fcea0bf53f04b79ac582d93da752cf1e655"). 📖 Next steps: * Push to BentoCloud with 'bentoml push': $ bentoml push codellama--codellama-7b-instruct-hf-service:65515fcea0bf53f04b79ac582d93da752cf1e655 * Containerize your Bento with 'bentoml containerize': $ bentoml containerize codellama--codellama-7b-instruct-hf-service:65515fcea0bf53f04b79ac582d93da752cf1e655 --opt progress=plain Tip: To enable additional BentoML features for 'containerize', use '--enable-features=FEATURE[,FEATURE]' [see 'bentoml containerize -h' for more advanced usage]
Once a Bento is built, you can containerize it to create a Docker image or push it to BentoCloud for serverless management and scaling.
Pushing the Code Llama Bento to BentoCloud#
Obtaining an API token#
Before pushing the Code Llama Bento to BentoCloud, you need to create an API token that contains the required permissions to create resources on BentoCloud.
-
Log in to the BentoCloud Console.
-
In the left navigation, select API Tokens and then click Create.
-
Enter a new token name like Code Llama and check Developer Operations Access. This will create a Developer token that allows you to push Bentos to BentoCloud.
-
Click Submit and then copy the generated API token.
-
Log in to BentoCloud in your terminal using the following command. Replace
<your-api-token>with the generated API token.bentoml cloud login --api-token <your-api-token> --endpoint <https://cloud.bentoml.com>Expected output:
Successfully logged in to Cloud for <user-name> in <organization-name>.
Pushing a Bento to BentoCloud#
After obtaining the API token, run the following command to push the Code Llama Bento to BentoCloud.
bentoml push codellama--codellama-7b-instruct-hf-service:latest
To verify the Bento has been pushed successfully, navigate to the Bentos page and you can find that your Code Llama Bento is stored in a Bento repository.
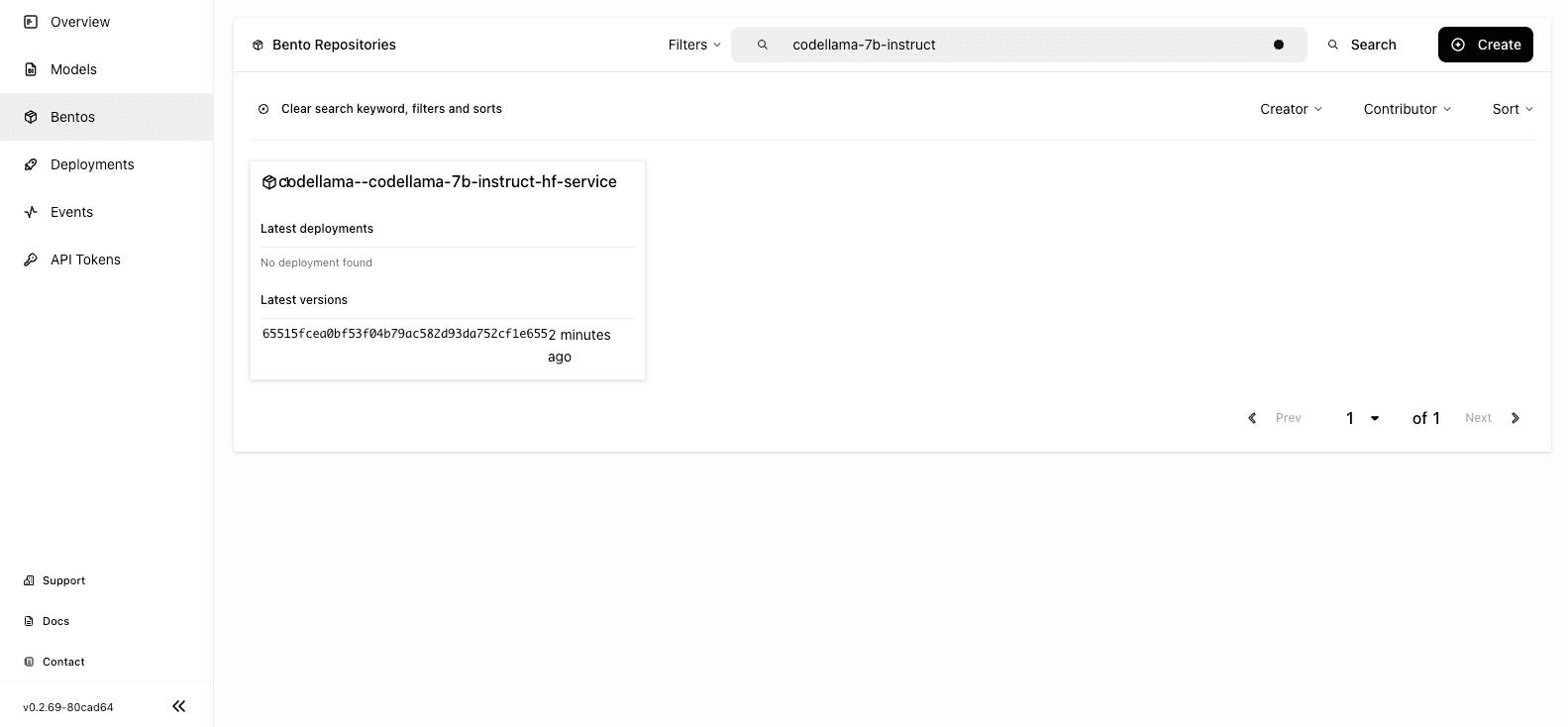
Deploying the Code Llama Bento on BentoCloud#
With the Code Llama Bento pushed to BentoCloud, you can start to deploy it.
-
In the left navigation of BentoCloud Console, select Deployments.
-
On the Deployments page, click Create > On-Demand Function. This deployment option can better serve the scenarios with loose latency requirements and large inference requests.
-
Select the Advanced tab and specify the required fields (marked with asterisks). For detailed information about properties on this page, see Deployment creation and update information. Pay attention to the following fields:
- Endpoint Access Type: Controls how you access the Code Llama application. For demonstration purposes, we chose Public to enable public access to the application. In production environments, we recommend implementing an additional layer of access control. For example, you can select Protected to make your application accessible only to those with a valid user token.
- Bento Repository: The name of the Bento repository and the Bento version that you want to deploy.
- Resources per replica: The resources allocated to run API Servers and Runners on different machines. cpu.xlarge and gpu.a10g.xlarge are selected in this demo for the API Server and Runner Pods respectively. You may select other types as long as there are enough resources.
-
Click Submit. The deployment may take some time to complete. When the status shows
Running, it means both the API Server and Runner Pods are active.
For more information about deploying a Bento on BentoCloud, see the BentoCloud documentation.
Accessing the Code Llama application#
With the Code Llama Bento deployed, you can access it using the exposed URL.
-
On the Overview tab of your Deployment, click the link in the URL column. Depending on the capabilities of the model you use, you may see different service APIs.
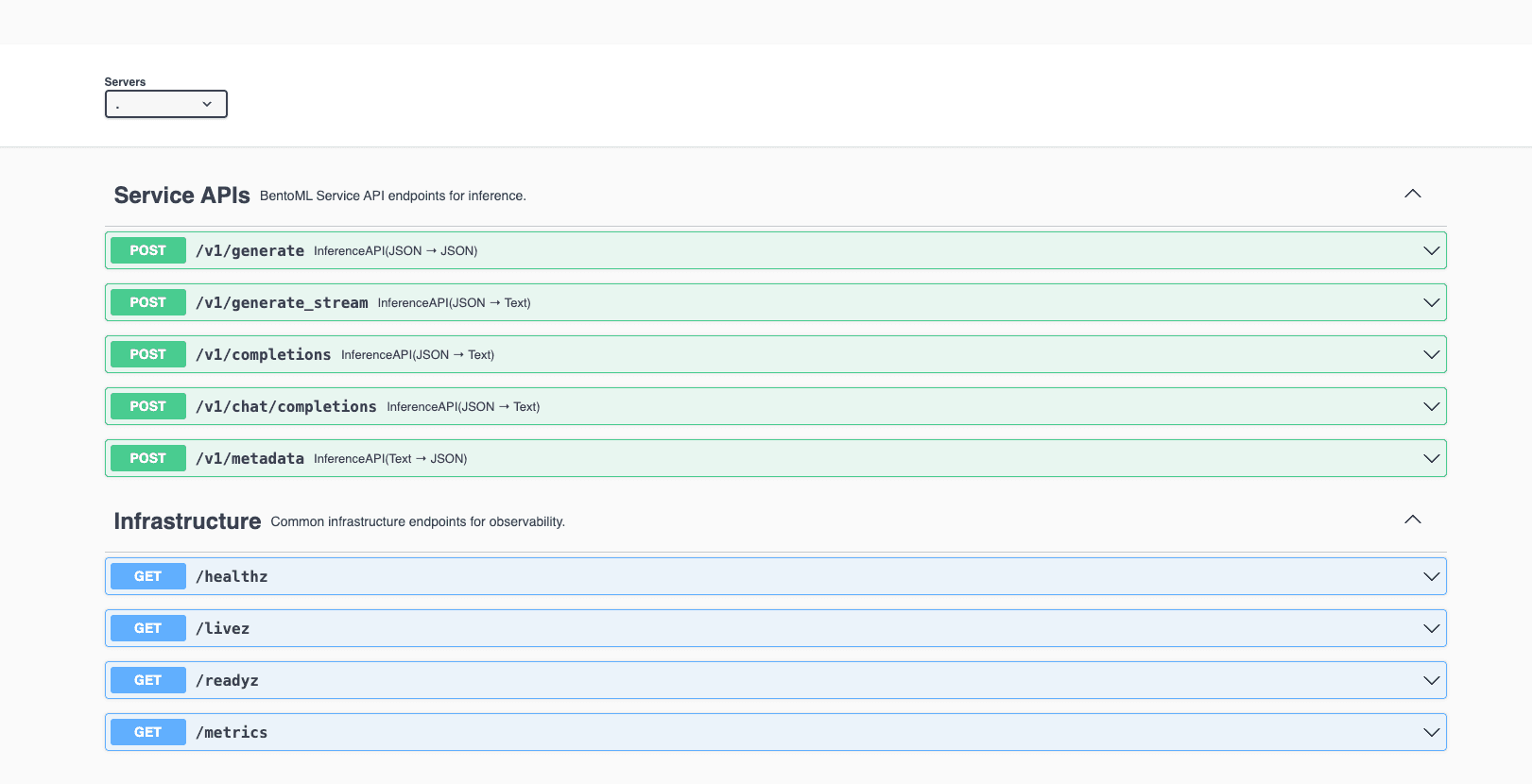
-
In the Service APIs section, select the /v1/generate_stream API and then click Try it out.
-
Enter your prompt (for example, "Write a simple code snippet in Python to calculate prime numbers"), configure other parameters as needed, and click Execute. Expected output:
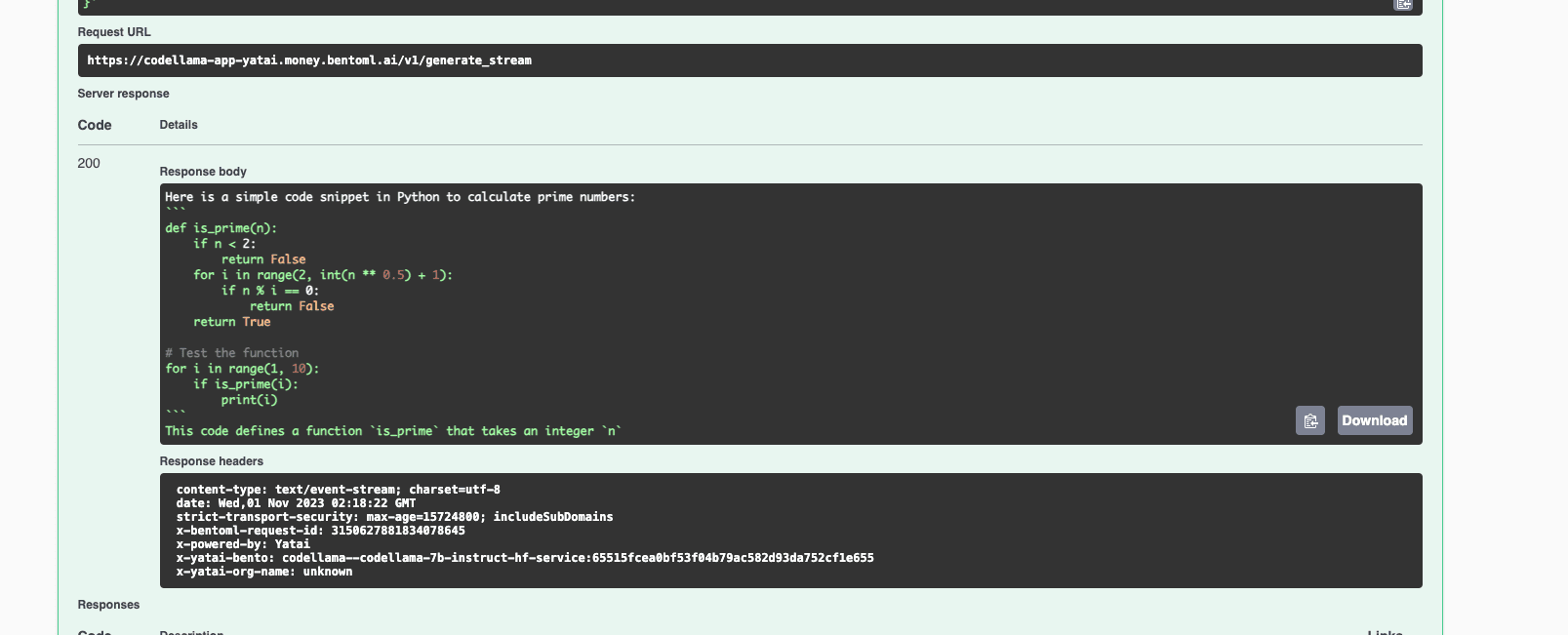
-
On the Monitoring tab, you can view different metrics to measure the performance of your application.
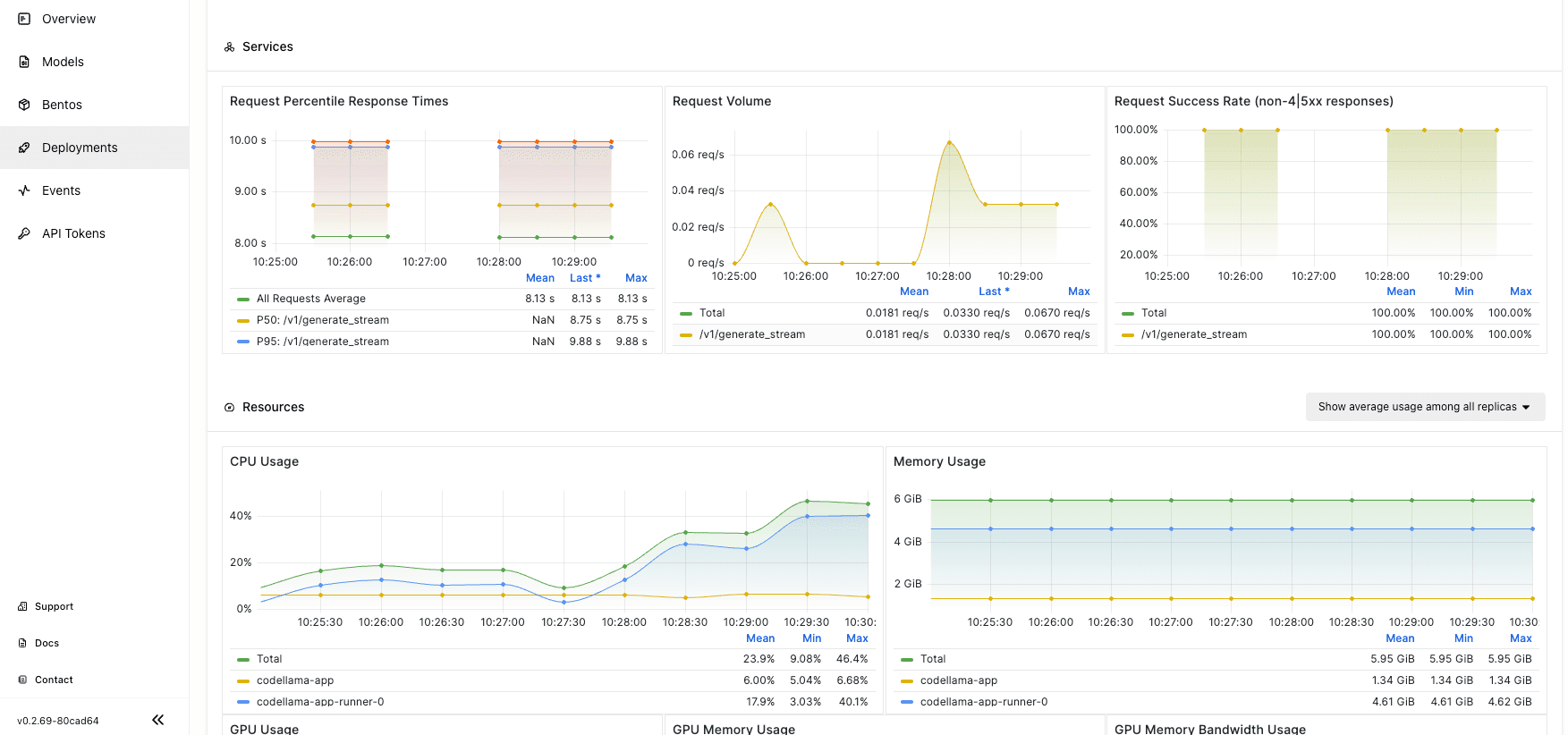
More on OpenLLM and BentoCloud#
To learn more about BentoML, OpenLLM, and BentoCloud, check out the following resources:
- [Colab] Tutorial: Serving Llama 2 with OpenLLM
- [Blog] From Models to Market: What's the Missing Link in Scaling Open-Source Models on Cloud?
- [Blog] BYOC to BentoCloud: Privacy, Flexibility, and Cost Efficiency in One Package
- [Blog] Monitoring Metrics in BentoML with Prometheus and Grafana
- Don’t miss out on the chance to be an early adopter! BentoCloud is still open for early sign-ups. Experience a serverless platform tailored to simplify the building and management of your AI applications, ensuring both ease of use and scalability.