Deploying ColPali with BentoML
Authors

Last Updated
Share

Document retrieval systems have traditionally relied on complex document ingestion pipelines, which often involve many independent steps such as OCR, layout analysis, and figure captioning. Leveraging visual elements in the retrieval process is a real challenge and requires many arbitrary choices. What if we could simplify this process while improving accuracy? Enter ColPali, a model that brings together the power of Vision Language Models (VLMs) and multi-vector embeddings.
In this blog post, we’re excited to share how you can deploy a fully functional ColPali inference API using BentoML. It empowers you to harness the power of visual document embeddings for large-scale document retrieval.
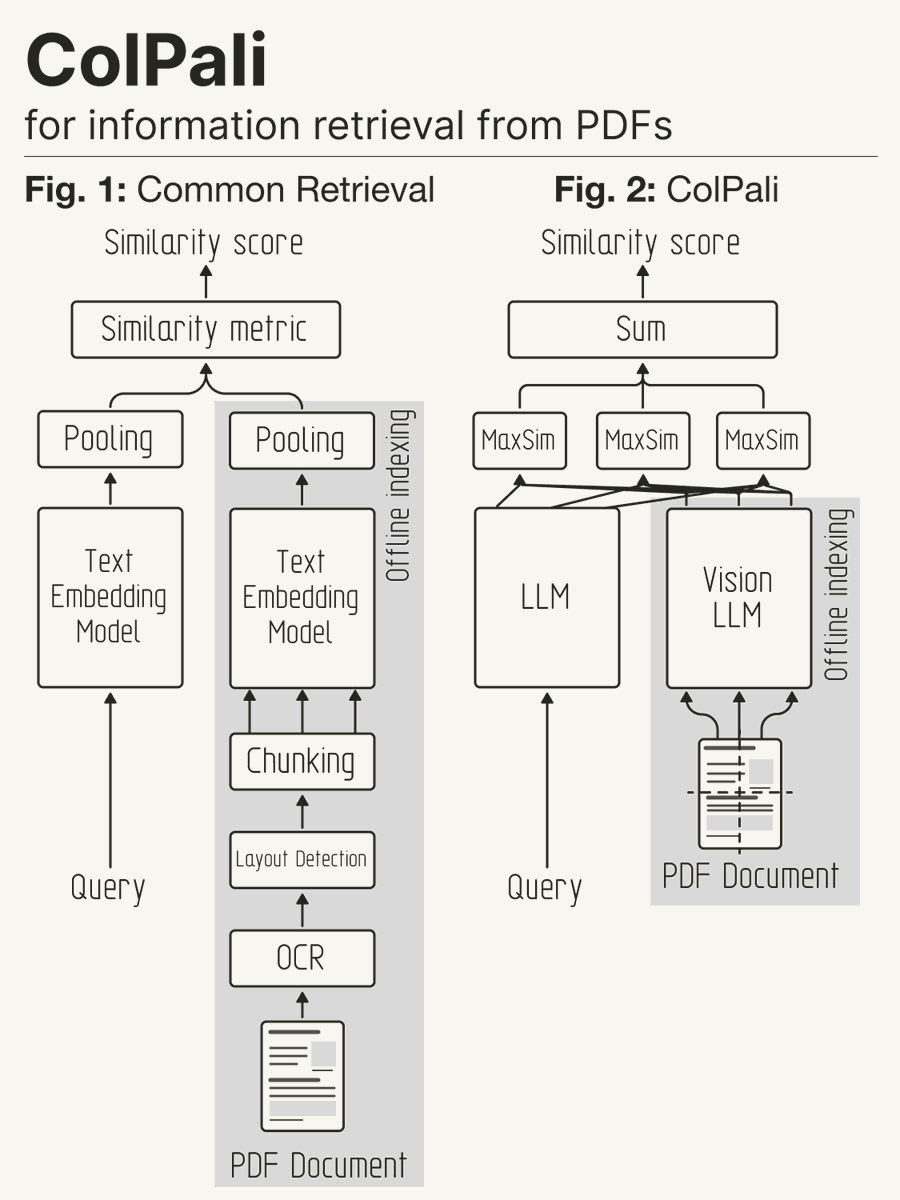
What is ColPali?#
In our proposed ColPali approach, we leverage VLMs to construct efficient multi-vector embeddings directly from document images (“screenshots”) for document retrieval. We train the model to maximize the similarity between these document embeddings and the corresponding query embeddings, using the late interaction method introduced in ColBERT.
Using ColPali removes the need for potentially complex and brittle layout recognition and OCR pipelines with a single model that can take into account both the textual and visual content (layout, charts, etc.) of a document.
What is BentoML?#
BentoML is a Unified Inference Platform for building and scaling AI systems with any model, on any cloud. It consists of:
- BentoML Open-Source Serving framework: As a Python framework, BentoML offers key primitives for inference optimization, task queues, batching, and distributed orchestration. Developers can deploy any model format or runtime, customize serving logic, and build reliable AI applications that scale.
- BentoCloud: An Inference Management Platform and Compute Orchestration Engine built on top of the BentoML open-source serving framework. BentoCloud provides a complete stack for building fast and scalable AI systems, with flexible Pythonic APIs, blazing fast cold start, and streamlined workflows across development, testing, deployment, monitoring, and CI/CD.
Challenges in deploying ColPali#
Deploying ColPali efficiently poses a unique operational challenge due to its multi-vector embedding approach. The high memory footprint of storing and retrieving multiple vectors for a single document page/image requires adaptive batching strategies to optimize memory usage. BentoML addresses all these challenges with features like adaptive batching and zero-copy I/O, minimizing overhead even for large tensor data.
For the sake of simplicity, we’ve decided to store vectors in memory in this blog post, but for a scalable production environment, a vector database is highly recommended (if not necessary). ColPali generates a multi-vector representation to embed a document page/image (similarly to ColBERT for text embedding), one vector for each image patch. On the other hand, vector databases traditionally store one vector per document/entry.
Currently, a few vector databases support multi-vector representations, such as Milvus, Qdrant, Weaviate, or Vespa. Other databases, like Elasticsearch, are working on supporting this feature. Thus, when industrializing ColPali for visual space retrieval at scale, ensure the chosen vector database can handle multi-vector representations.
Setup#
To get started, first clone the project repository and navigate to the directory. It contains everything you need for deployment.
git clone https://github.com/bentoml/BentoColPali.git cd BentoColPali
We recommend you set up a Python virtual environment to isolate dependencies:
python -m venv bento-colpali source bento-colpali/bin/activate
Install the required dependencies.
# Recommend Python 3.11 pip install -r requirements.txt
Download the model#
Before running our project, you'll need to download and build the ColPali model. Because ColPali uses PaliGemma as its VLM backbone, the Hugging Face account associated with the provided token must have accepted the terms and conditions of google/paligemma-3b-mix-448.
python bentocolpali/models.py --model-name vidore/colpali-v1.2 --hf-token <YOUR_TOKEN>
Verify the model download by listing your BentoML model:
$ bentoml models list Tag Module Size Creation Time colpali_model:mcao35vy725e6o6s 5.48 GiB 2024-12-13 03:00:15
Serve the model with BentoML#
With the model ready, you can try serving the model locally:
bentoml serve .
This command starts the BentoML server and exposes four endpoints at http://localhost:3000:
| Route | Input | Output | Description |
|---|---|---|---|
| /embed_images |
| Multi-vector embeddings | Generates image embeddings with shape (batch_size, sequence_length, embedding_dim). |
| /embed_queries |
| Multi-vector embeddings | Generates query embeddings with shape (batch_size, sequence_length, embedding_dim). |
| /score_embeddings |
| Scores | Computes late-interaction/MaxSim scores between pre-computed embeddings. Returns scores with shape (num_queries, num_images). |
| /score |
| Scores | One-shot computation of similarity scores between images and queries (i.e. run the 3 routes above in the right order). It returns scores with shape (num_queries, num_images). |
Adaptive batching#
In this project, we enable BentoML’s adaptive batching for /embed_images and /embed_queries endpoints. This feature dynamically adjusts the batch size and dispatch timing based on real-time traffic patterns, ensuring efficient resource utilization. You can use max_batch_size and max_latency_ms to define strict operational limits, guaranteeing that throughput is maximized and latency remains within acceptable bounds.
Here's an example of how it’s configured:
# Use the @bentoml.service decorator to mark a Python class as a BentoML Service @bentoml.service( name="colpali", workers=1, traffic={"concurrency": 64}, # Set concurrency to match the batch size ) class ColPaliService: ... @bentoml.api( batchable=True, # Enable adaptive batching batch_dim=(0, 0), # The batch dimension for both input and output max_batch_size=64, # The upper limit of the batch size max_latency_ms=30_000, # The maximum milliseconds a batch waits to accumulate requests ) async def embed_images( self, items: List[ImagePayload], ) -> np.ndarray: ...
For more information, see the BentoML documentation and the full source code.
Call the endpoint APIs#
To interact with the APIs, you can create a client to send requests to the server. Below is an example:
import bentoml from PIL import Image from bentocolpali.interfaces import ImagePayload from bentocolpali.utils import convert_pil_to_b64_image # Prepare image payloads image_filepaths = ["page_1.jpg", "page_2.jpg"] image_payloads = [] for filepath in image_filepaths: image = Image.open(filepath) image_payloads.append(ImagePayload(url=convert_pil_to_b64_image(image))) # Prepare queries queries = [ "How does the positional encoding work?", "How does the scaled dot attention product work?", ] # Create a BentoML client and call the endpoints with bentoml.SyncHTTPClient("http://localhost:3000") as client: image_embeddings = client.embed_images(items=image_payloads) query_embeddings = client.embed_queries(items=queries) scores = client.score_embeddings( image_embeddings=image_embeddings, query_embeddings=query_embeddings, ) print(scores)
Note that ImagePayload requires images to be base64-encoded in the format:
{ "url": "data:image/png;base64,iVBORw0KGgoAAAANSUhEU..." }
Example output:
[ [16.1253643, 6.63720989], [9.21852779, 15.88411903] ]
Deploy to BentoCloud#
Now that everything works locally, it’s time to deploy the ColPali service to BentoCloud. This gives you a secure, scalable, and reliable inference API.
Before deployment, ensure the resources required are specified in bentocolpali/service.py via the @bentoml.service decorator. For this example, a single NVIDIA T4 GPU is sufficient:
@bentoml.service( name="colpali", workers=1, resources={ "gpu": 1, # The number of GPUs "gpu_type": "nvidia-tesla-t4", # The GPU type }, traffic={"concurrency": 64}, )
Log in to BentoCloud. Sign up here for free if you don’t have a BentoCloud account:
bentoml cloud login
Navigate to the root directory of your project (where bentofile.yaml is located). Run the following command to deploy it to BentoCloud and optionally set a name with the -n flag:
bentoml deploy . -n colpali-bento
Once the deployment is complete, you can find it in the Deployments section.
To retrieve the exposed URL, run:
bentoml deployment get colpali-bento -o json | jq ."endpoint_urls"
Replace http://localhost:3000 in the previous client code with the retrieved URL, and you can make the same API calls.
By default, the Deployment has one replica, but you can scale it to meet your needs. For example, to scale between 0 and 5 replicas, use:
bentoml deployment update colpali-bento --scaling-min 0 --scaling-max 5
This minimizes resource usage during idle periods while efficiently handling high traffic with rapid cold start time.
Conclusion#
In this tutorial, we've shown how to deploy ColPali with BentoML, creating an inference API that understands both text and visual content without complex OCR pipelines. The solution is easy to serve locally or scale in production with BentoCloud. Give it a try and see how it can simplify your document processing workflows!
More resources: