Deploying Llama 2 7B on BentoCloud
Authors

Last Updated
Share

Llama 2, developed by Meta, is a series of pretrained and fine-tuned generative text models, spanning from 7 billion to a staggering 70 billion parameters. These models have outperformed many of their open-source counterparts on different external benchmarks, showcasing superiority in areas like reasoning, coding, proficiency, and knowledge. Since its launch, many model variants of customized Llama 2 have also emerged, providing support for task specific use cases.
For those looking to deploy Llama 2 and its customized variants, OpenLLM can be a helpful open-source platform, since it supports running inference with any open-source large language models (LLMs). With adequate resources, such as memory and GPUs, launching a Llama 2 model locally via OpenLLM is easy and straightforward. Moreover, as OpenLLM provides first-class support for BentoML, you can easily use the unified AI application framework to package the model, create a Docker image, and set it into motion for production.
However, the real challenge surfaces when attempting to scale AI applications embedded with LLMs like Llama 2. You may need to plan your resources on cloud platforms wisely and even delve into Kubernetes intricacies.
In this connection, you can choose BentoCloud as an end-to-end solution for deploying and scaling production-ready AI applications. BentoCloud is designed to streamline AI application development and expedite the delivery lifecycle. Its seamless integration with both OpenLLM and BentoML ensures that deploying Llama 2 models on the cloud is reduced to a simple command and a handful of clicks. In addition, it allows for flexible autoscaling (with scale-to-zero support) based on the workload traffic so you only pay for what you use. The best part? You’re liberated from the complexities of managing the underlying infrastructure, while retaining comprehensive insights into your application’s observability metrics.
In this blog post, I will guide you step-by-step on deploying the Llama 2 7B model using BentoCloud.
Before you begin#
Make sure you meet the following prerequisites.
- You have installed OpenLLM.
- You have a BentoCloud account. BentoCloud is still available for early sign-up and we’ve recently begun granting access to early adopters.
- The official Llama 2 7B model is used in this blog post, which requires you to gain access by visiting the Meta AI website and accepting its license terms and acceptable use policy. You also need to obtain access to Llama 2 models on Hugging Face. Note that any Llama 2 variant can be deployed with OpenLLM if you don’t have access to the official Llama 2 model. Visit the Hugging Face Model Hub to see more Llama 2 compatible models.
Building a Llama 2 Bento#
-
First, log in to BentoCloud. This requires you to have a Developer API token, which allows you to access BentoCloud and manage different cloud resources. See the BentoCloud documentation to learn more.
bentoml cloud login --api-token <your-api-token> --endpoint <your-bentocloud-endpoint> -
After you log in, run the following command to build a Bento with any of the Llama 2 variants and push it to BentoCloud. This example uses
meta-llama/Llama-2-7b-chat-hffor demonstration (runopenllm modelsto see all the supported models). The--backend=vllmoption activates vLLM optimizations, ensuring maximum throughput and minimal latency for the model's performance. The--pushoption allows you to push the resulting Bento to BentoCloud directly. Pushing the Bento to BentoCloud may take some time, depending on your network conditions.openllm build meta-llama/Llama-2-7b-chat-hf --backend=vllm --pushNote: When running the above command, make sure you use the same context as the one for BentoCloud login. The context can be specified via
--context. -
The
openllm buildcommand builds a Bento with the model specified. If the model has not been registered to the BentoML local Model Store before, OpenLLM first downloads the model automatically and then builds the Bento. Runbentoml listto view the Bento.$ bentoml list Tag Size Creation Time meta-llama-llama-2-7b-chat-hf-service:g5a12d8b95f647c2a81b30e4c5f9bd2e01ab678f 35.24 KiB 2023-08-23 11:16:46 -
After the Bento has been uploaded to BentoCloud, you can find it on the Bento Repositories page. Following is the details page of the Bento.
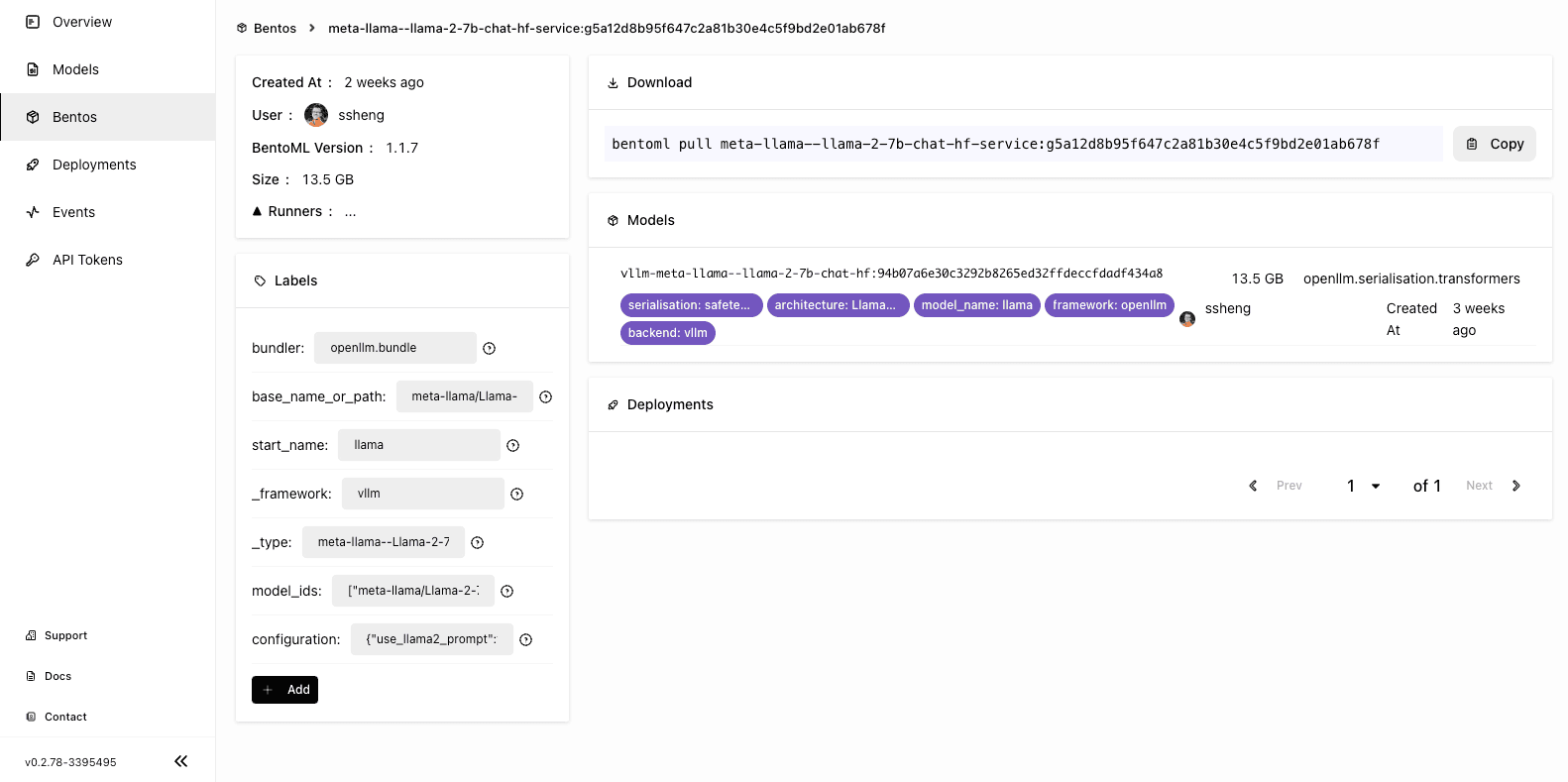
Deploying the Llama 2 model on BentoCloud#
With the Bento pushed to BentoCloud, you can start to deploy it.
-
Go to the Deployments page and click Create. On BentoCloud, there are two Deployment options - Online Service and On-Demand Function. For this example, you can select the latter, which is useful for scenarios with loose latency requirements and large inference requests.
-
You can then set up the Bento Deployment in one of the following three ways.
- Basic: Quickly spin up a Deployment with basic settings.
- Advanced: Configure additional configurations of the Deployment, such as autoscaling behaviors, environment variables, and update strategies.
- JSON: Define a JSON file to configure the Deployment directly.
-
Select the Advanced tab and specify the required fields (marked with asterisks). Pay attention to the following fields:
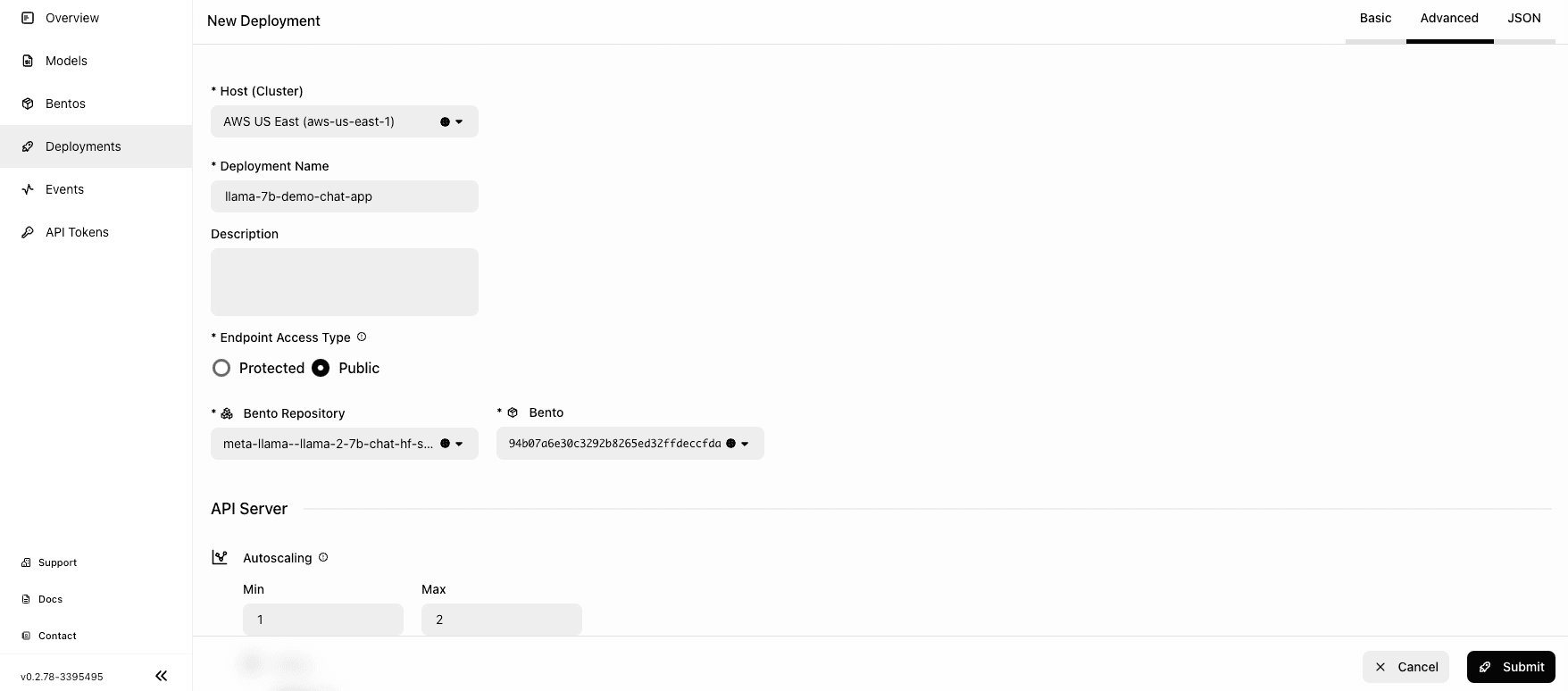
- Endpoint Access Type: This property controls how you access the Llama 2 application. For demonstration purposes, I chose Public to enable public access to the application. In production, I recommend you implement an additional layer of access control. For example, you can select Protected to make your application accessible only to those with a valid User token.
- Bento Repository: After you choose a Bento Repository, you need to select a Bento version. You can retrieve the information by running
bentoml listlocally. - Resources per replica: You have the flexibility to operate API Servers and Runners on separate machines. A practical default configuration involves employing
cpu.mediumfor API Servers andgpu.a10g.xlargefor Runners. The Llama 7B model weights approximately occupy 14GB of GPU memory. Given that thegpu.a10g.xlargeis equipped with 24GB of GPU memory, this allocation not only accommodates the model weights comfortably but also provides ample memory headroom for efficient inference processing. - Environment variables: Because the
meta-llama/Llama-2-7b-chat-hfmodel is gated, it necessitates obtaining approval and providing the HuggingFace token via an environment variable. For both the API Server and Runner, you should setHUGGING_FACE_HUB_TOKENas the key, with your Hugging Face token (beginning withhf_) as its value. If you are using an open Llama 2 compatible model, setting environment variable is not needed.
For other fields, you can use the default values or customize them as needed. For more information about properties on this page, see Deployment creation and update information.
-
When you are done, click Submit. The deployment may take some time. When it is ready, both the API Server and Runner Pods should be active.
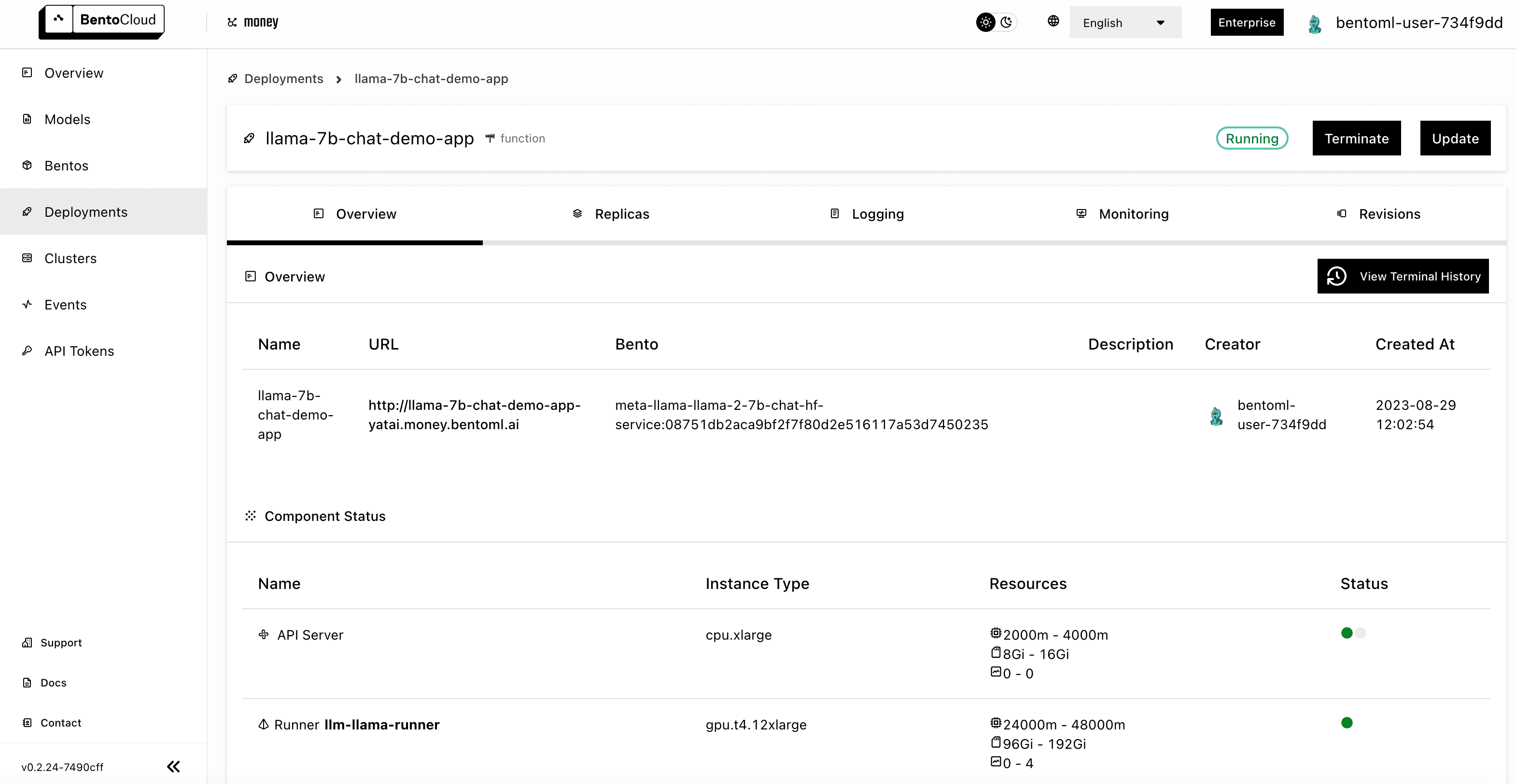
Accessing the Llama 2 application#
With the Llama 2 application ready, you can access it with the URL exposed by BentoML.
-
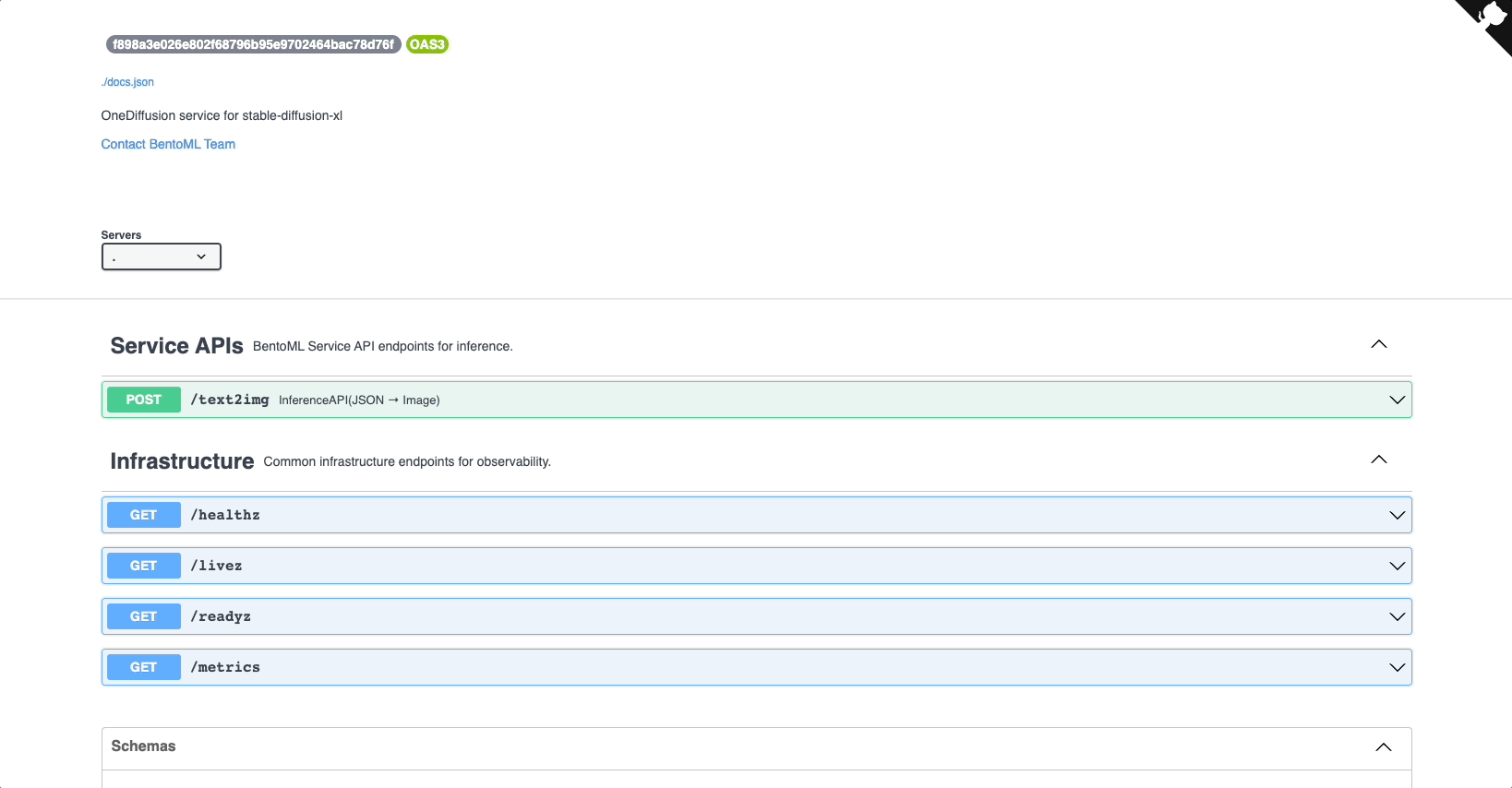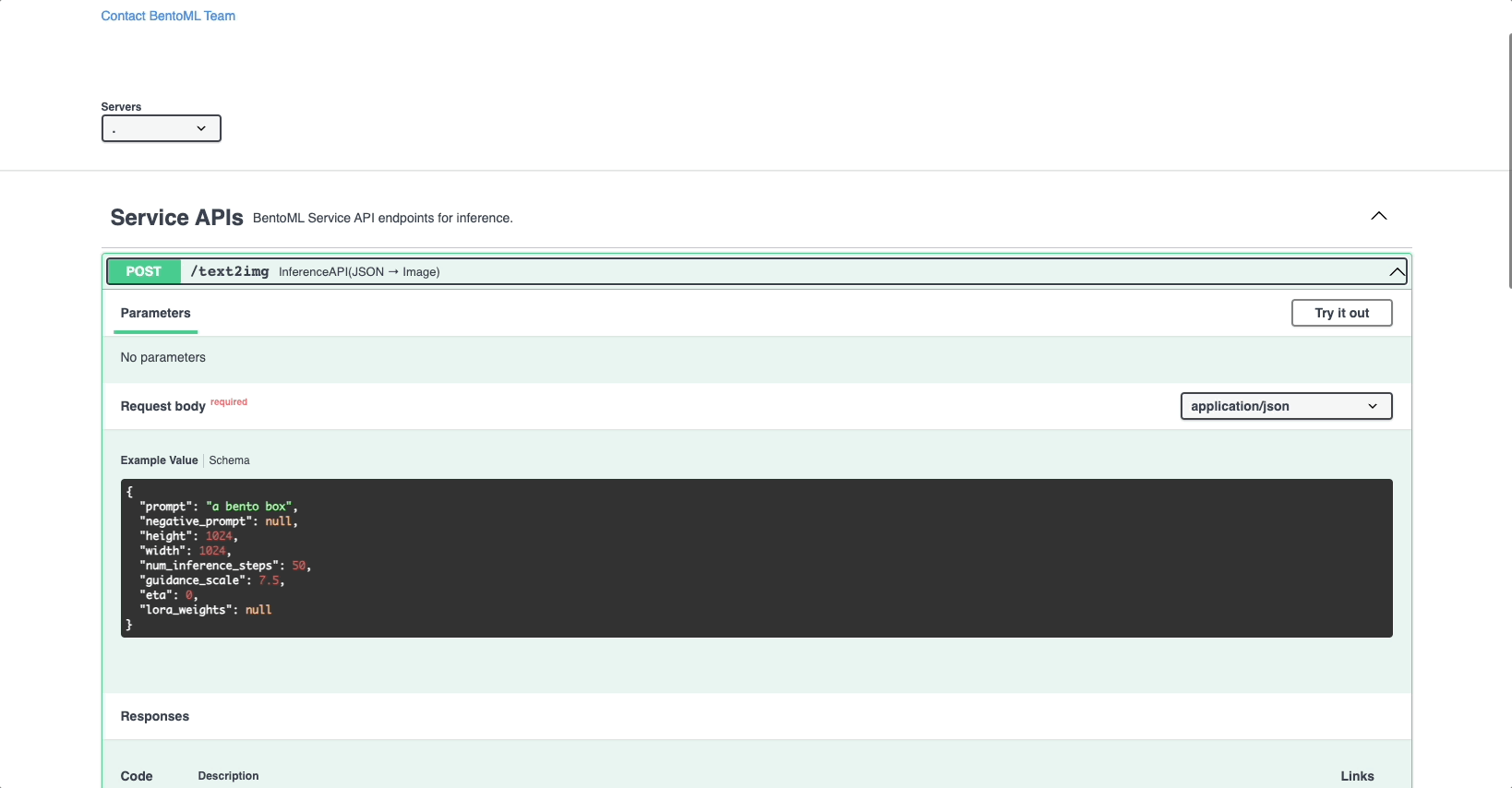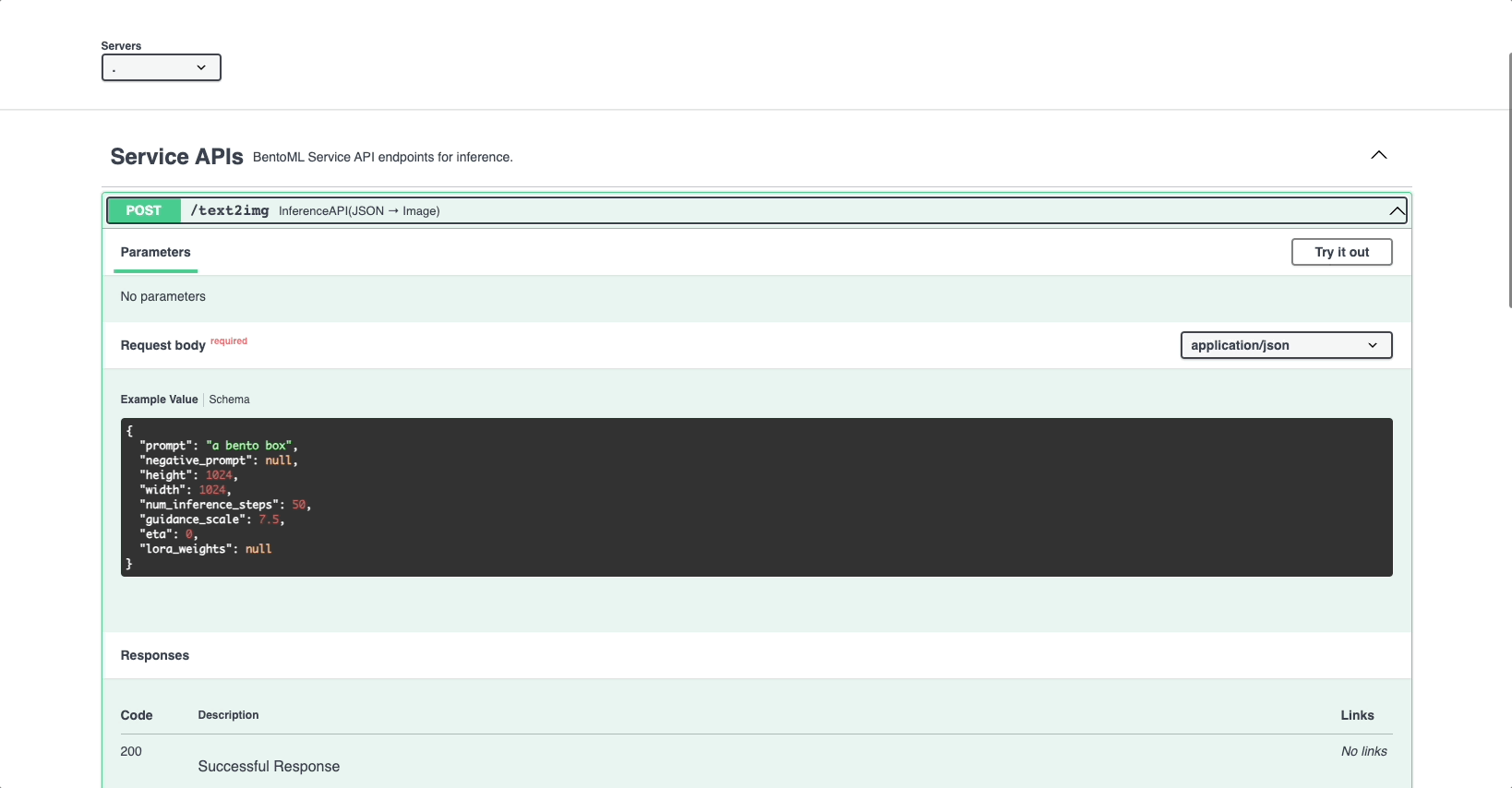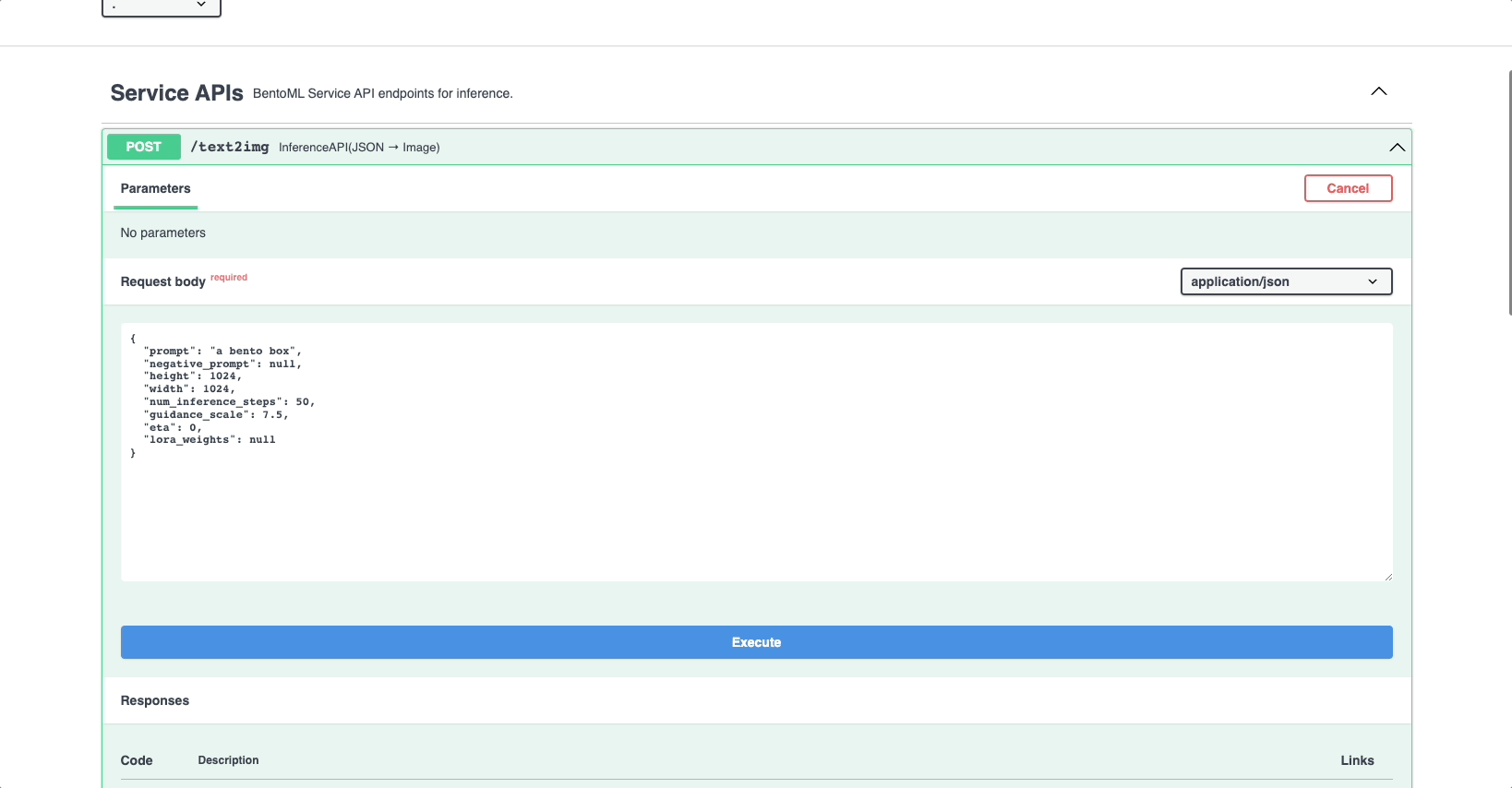
On the Overview tab of its details page, click the link under URL. If you do not set any access control policy (i.e. select Public for Endpoint Access Type), you should be able to access the link directly. The Swagger UI looks like the following:
-
In the Service APIs section, select the
generateAPI and click Try it out. Enter your prompt, configure other parameters as needed, and click Execute. You can find the answer in the Responses section. Instead of using the Swagger UI, you can also usecurlto send requests, the command of which is also displayed in the Responses section. -
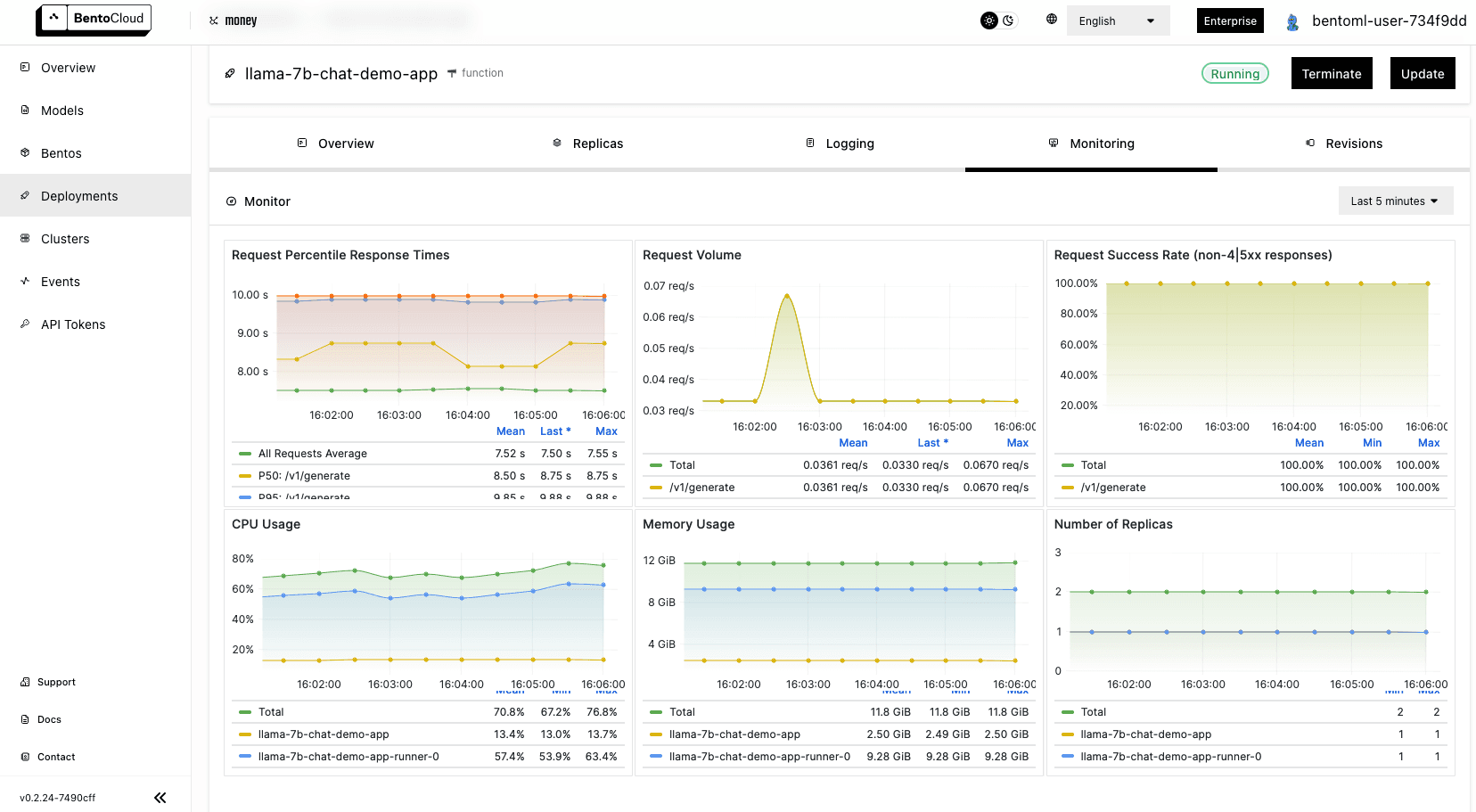
On the Monitoring tab, you can view different metrics of the workloads:
Conclusion#
Deploying sophisticated models like Llama 2 can often seem like a daunting task. However, as I’ve explained in this article, BentoCloud can significantly simplify this process. Whether you’re a seasoned developer or just starting out in the AI landscape, using BentoCloud allows you to focus on what truly matters: building and refining your AI applications. As the AI realm continues to evolve, tools that enhance efficiency and reduce complexities will be paramount. I hope this guide has provided you with a clear way to harness the power of Llama 2 using BentoCloud, and I encourage you to explore further and experiment with your own AI projects.
Happy coding ⌨️, and until next time!
More on BentoML and OpenLLM#
To learn more about BentoML, OpenLLM, and other ecosystem tools, check out the following resources:
- [Doc] Deploy a large language model with OpenLLM and BentoML
- [Blog] Deploying Stable Diffusion XL on BentoCloud and Dynamically Loading LoRA Adapters
- [Blog] Deploying an OCR Model with EasyOCR and BentoML
- Don’t miss out on the chance to be an early adopter! BentoCloud is still open for early sign-ups. Experience a serverless platform tailored to simplify the building and management of your AI applications, ensuring both ease of use and scalability.