From Models to Market: What's the Missing Link in Scaling Open-Source Models on Cloud?
Authors

Last Updated
Share

Note: This blog post is converted from Fog Dong’s keynote speech at KubeCon China 2023.
There's no doubt that artificial intelligence (AI) is once again catching everyone's eyes. The surge in AI startups globally over the past decade is a testament to this. This year’s KubeCon further highlighted the growing interest in AI, with more AI-related discussions than ever before.
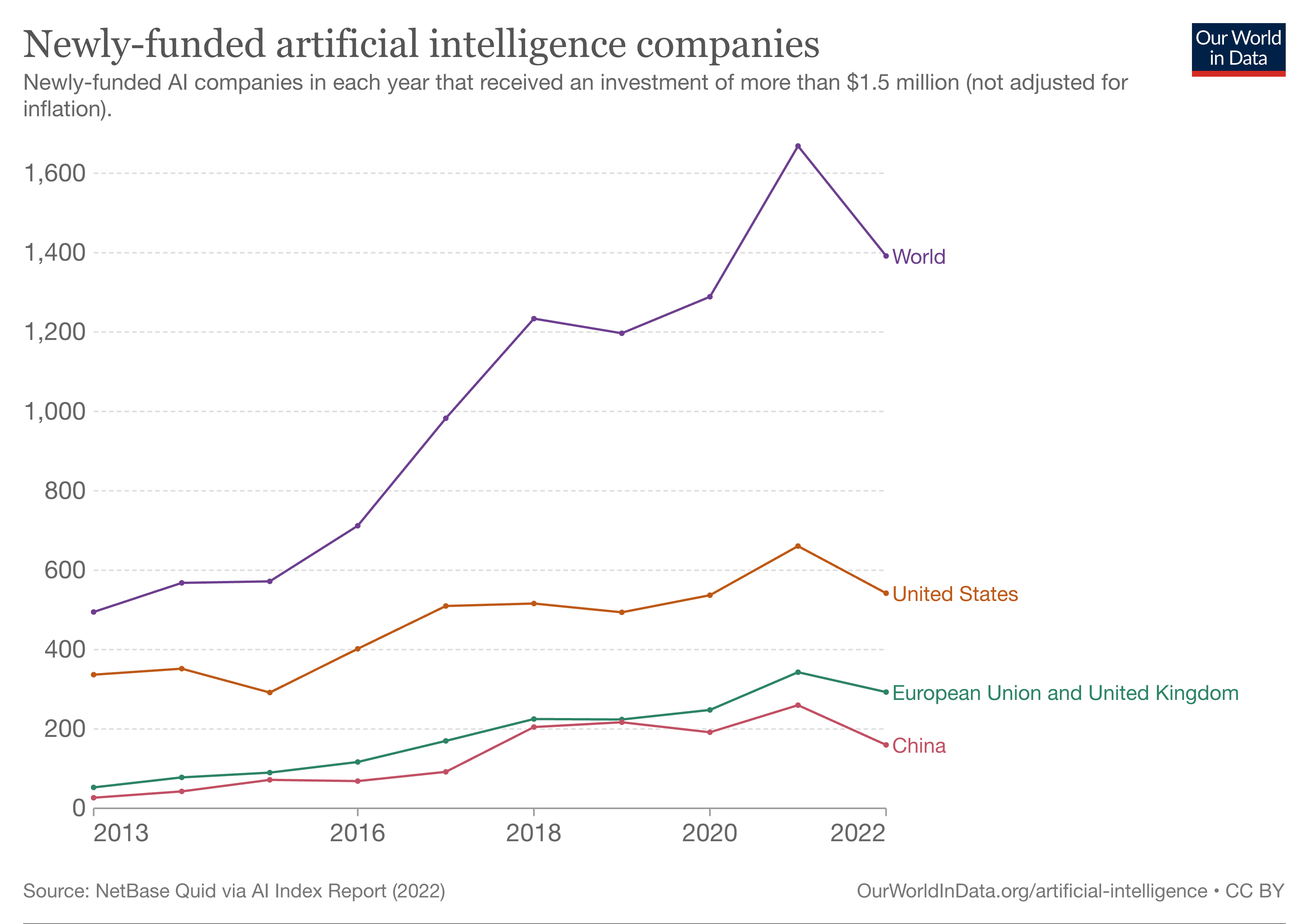
The power of open source#
While the AI landscape flourishes with exciting opportunities, not all companies can, or need to, build their own models. Fortunately, the open-source community has seen a variety of machine learning models born for the AI industry.
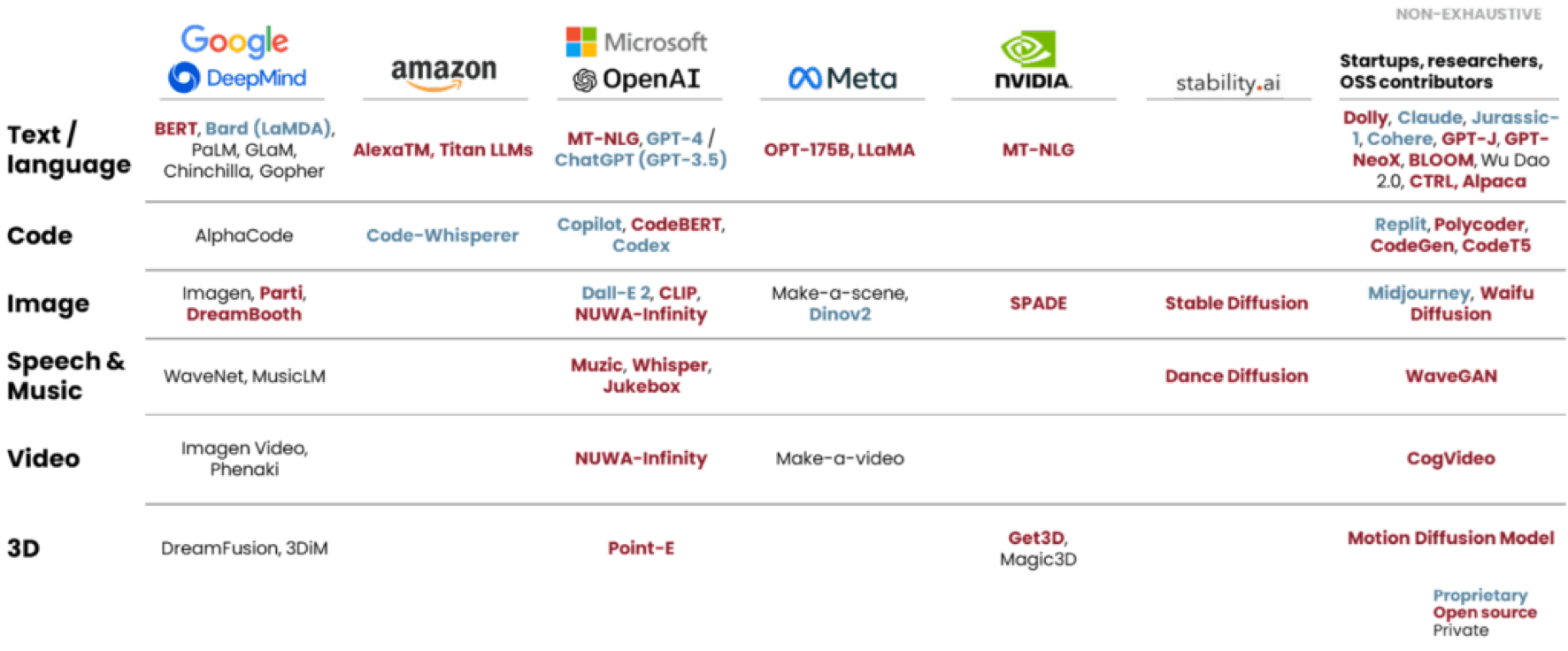
Compared to closed models, open-source models are winners in customizability, data privacy, and cost-efficiency. By fine-tuning these models with proprietary datasets and deploying them in private environments, businesses can ensure data privacy and only pay for the cost that the models need.
The journey from a model to an application#
However, converting a model into a fully-functional application isn't a straightforward task. For example, how do we take an open-source model like Llama 2 into a production-ready application running on the cloud that generates advertising proposals?
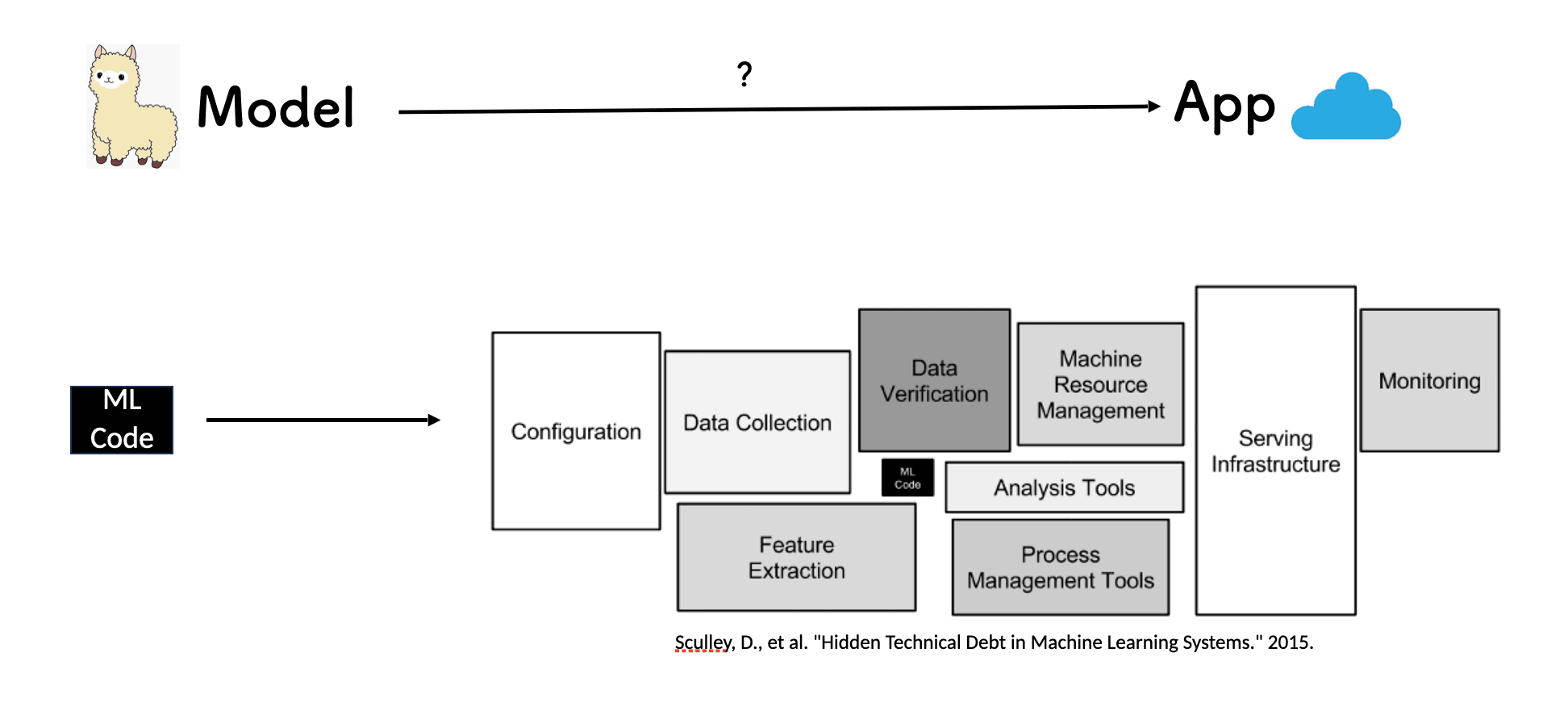
If we dive deeper into this, we can consider a model as ML code, but the journey involves more than that. Among other things, code, configuration, data collection, and serving infrastructure are all building blocks. In order to bridge the gap between the model and the application, we need to first find an intermediate station. With this in mind, we split the process into two main phases: build and deploy.
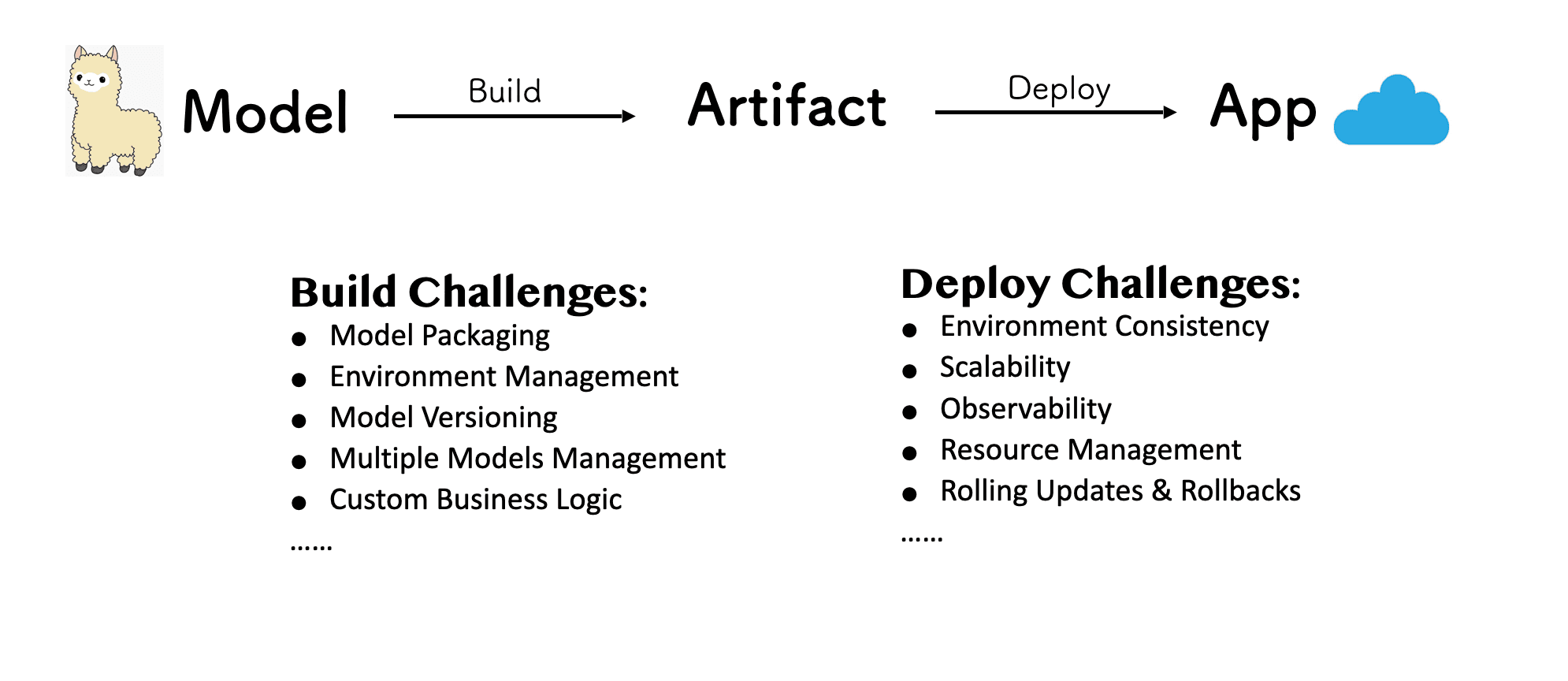
The build phase presents challenges like model packaging, environment management, and model versioning; for the deploy phase, challenges might look familiar to us, since those are the challenges that Kubernetes and the cloud-native ecosystem are trying to resolve.
Now that we know the challenges, let's try to resolve them.
Building with BentoML#
To build an intermediate artifact, you need to somehow find a way to package the model, dependencies, and everything you need into something that can be easily deployed. That's where BentoML comes into the play.
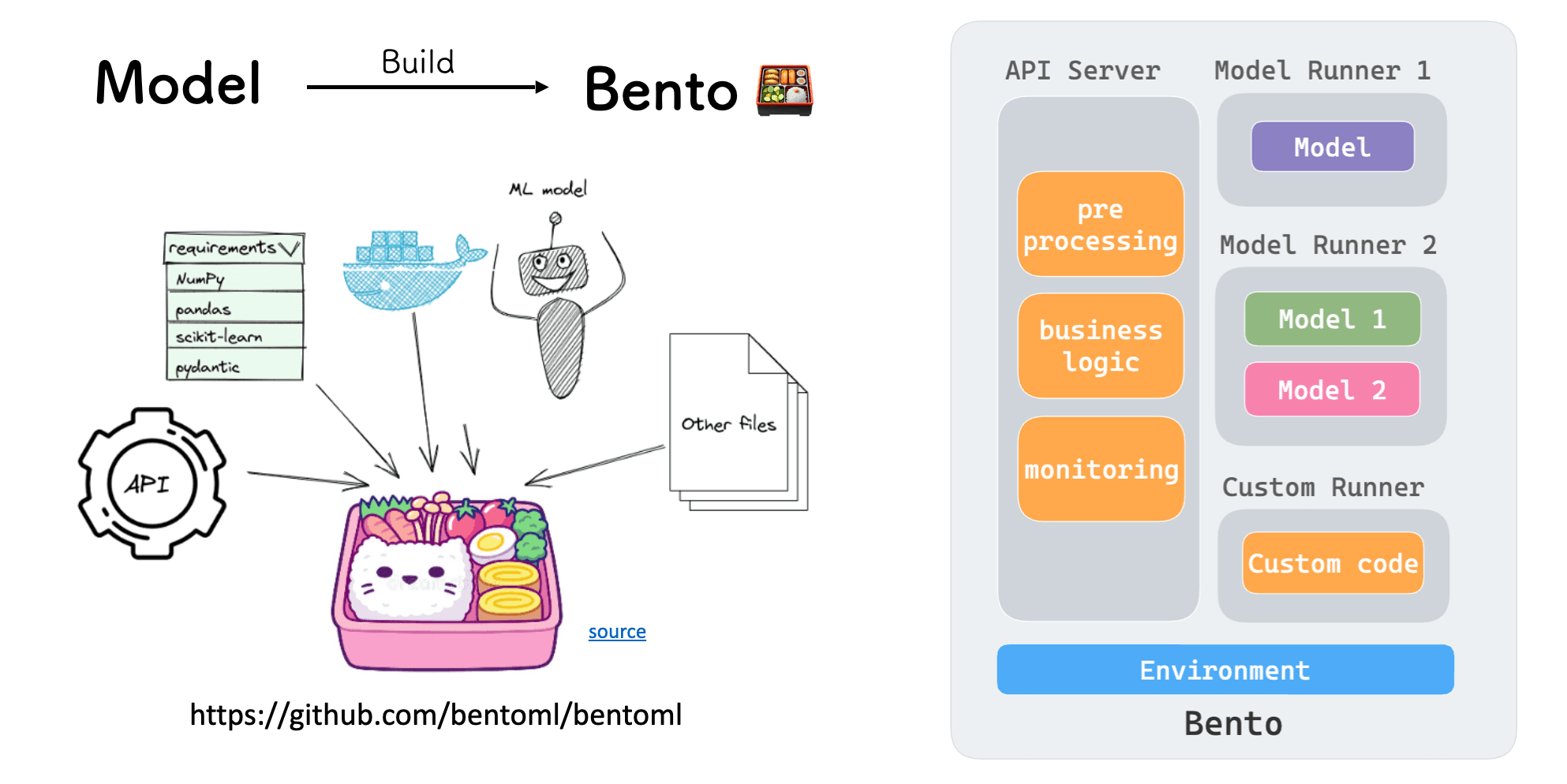
BentoML is an open-source Python framework that can help you build your application. Drawing inspiration from the Asian bento box, which offers a complete meal in one package, BentoML bundles APIs, dependencies, models, and other necessary components into a single deployable unit, also known as a Bento.
A Bento has three key components:
- API Server: Handles IO-intensive tasks like pre-processing, post-processing, business logic, metric exposure, and API definitions.
- Model Runner: Manages the loading of models, which can be built with different frameworks like PyTorch or TensorFlow, ensuring they utilize appropriate resources.
- Environment: Contains configurations and dependencies.
Note: We all know that basically all the models are more like a compute-intensive workload. When transforming a model into an application, we might need to handle things like concurrent requests. That's when it's converted into an IO-intensive workload. This is also the reason why we separate the API Server from the Runner within a Bento.
Another important thing to consider is how do we organize a Bento to make sure it is built in the way we want? When building a Bento, the first thing you need to do is to write a Bento configuration file in YAML, typically known as bentofile.yaml. In this file, you specify all the configurations you care about, such as the version of the dependencies and the entry point of your API Server and Runner.
With a single command bentoml build, a Bento is built and stored in the BentoML local Bento Store by default. You can use commands like bentoml push to push a Bento to S3 or other registries.
Deploying on Kubernetes#
Once the Bento is built, the next step is deployment. While BentoML offers commands like bentoml serve for local testing, stable production deployment requires the scalability and resilience of cloud-native solutions and Kubernetes.
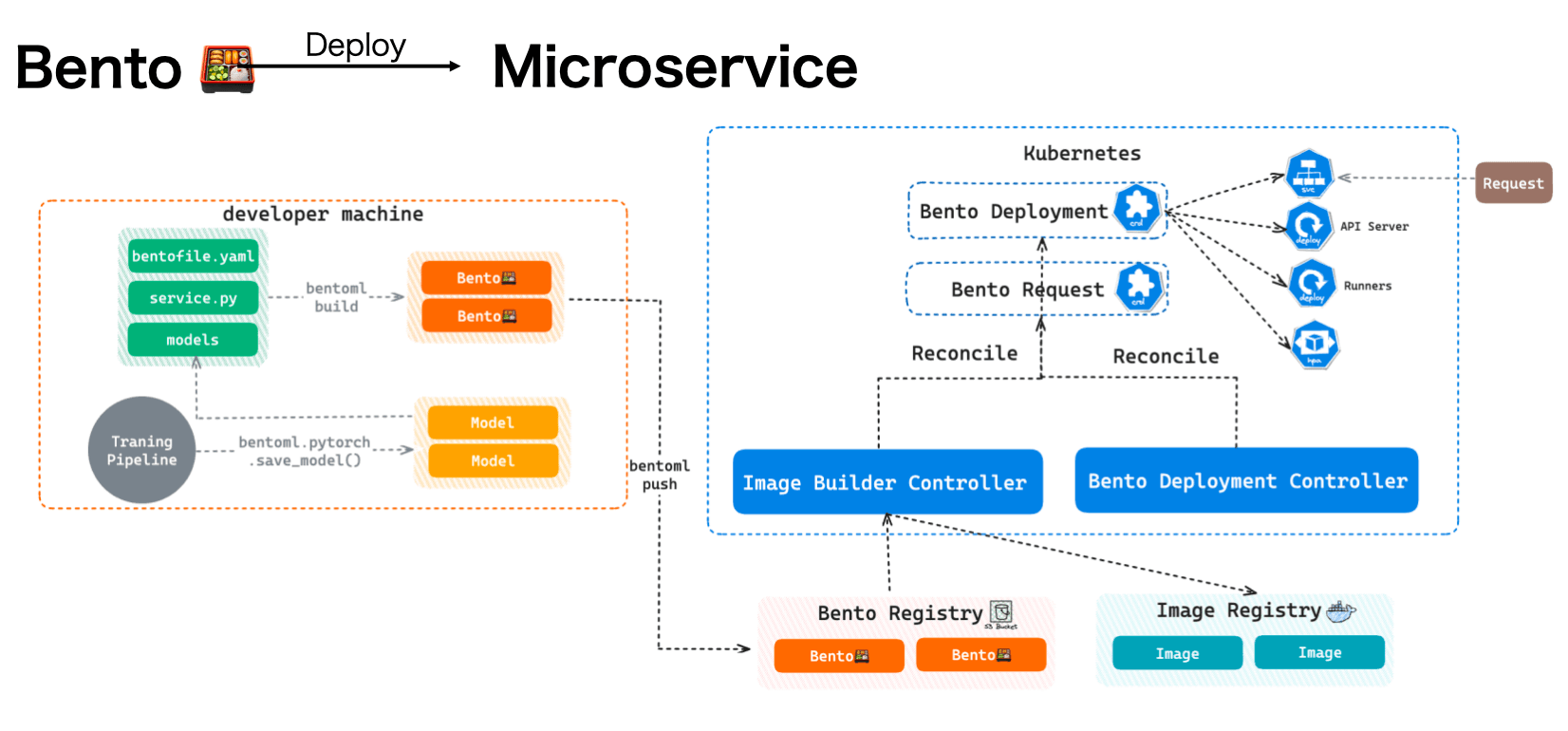
To deploy a Bento as a microservice on Kubernetes, we need two more controllers working within the cluster.
- Image Builder Controller: Watches a custom resource called "BentoRequest" and automatically builds a Bento into an image. Note that a Dockerfile is automatically generated by default, which contains all the required dependencies in a Bento. However, you can also customize it in the Bento configuration file (
bentofile.yaml). - Bento Deployment Controller: Uses the image just built and reconciles the resource called “Bento Deployment”. This controller creates all the resources for your AI application, such as the Service, the HPA, as well as the API Server and Runner Pods, which can be scaled independently.
We now know both the challenges and the solutions, but it doesn’t make the journey less daunting. Over the past year, we’ve seen the booming of open-source large language models (LLMs). A question suddenly found us: Can all the AI developers easily serve open-source language models on the cloud?
Case study: OpenLLM#
OpenLLM, an open-source project we launched several months ago, aims to make the deployment of popular LLMs on the cloud easy and efficient. The initial idea of this project is to combine the best practices in the industry, enabling AI developers to deploy LLMs with just one command.
However, productionizing LLMs like Llama 2 is much more complicated with major challenges like scalability, throughput, latency, and cost. To address these challenges, we have added more enhancements to the project.
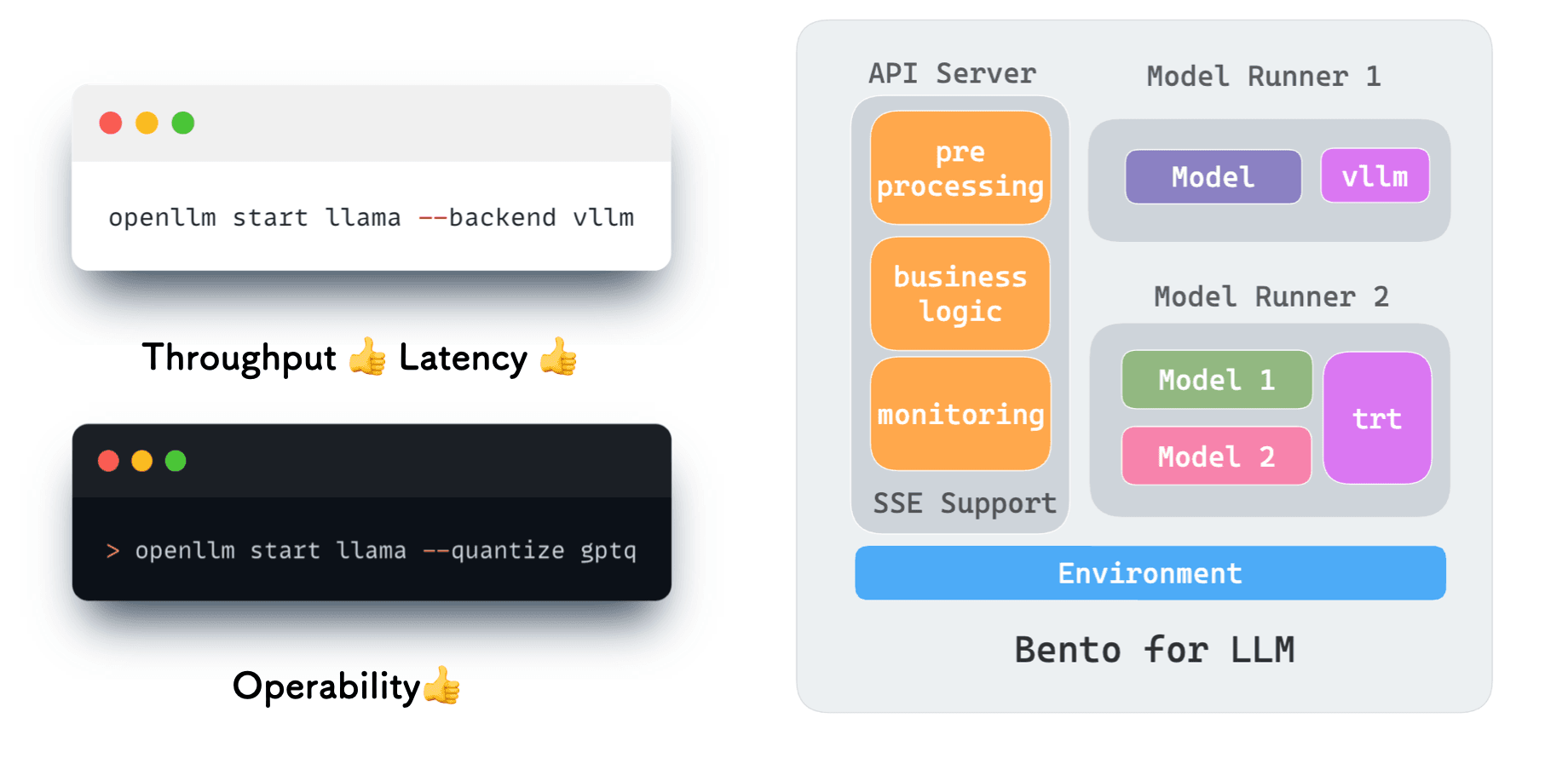
- SSE (Server-Sent Events). We incorporated SSE support in the API Server so that the language model can respond more quickly.
- Open source backend. To better leverage of the power of open source, we added support for open-source backend projects like vLLM. vLLM comes with features like PagedAttention, which greatly improves the throughput and reduces the latency of LLMs.
- Quantization. OpenLLM allows you to run inference with less computational and memory costs though techniques like bitsandbytes and GPTQ.
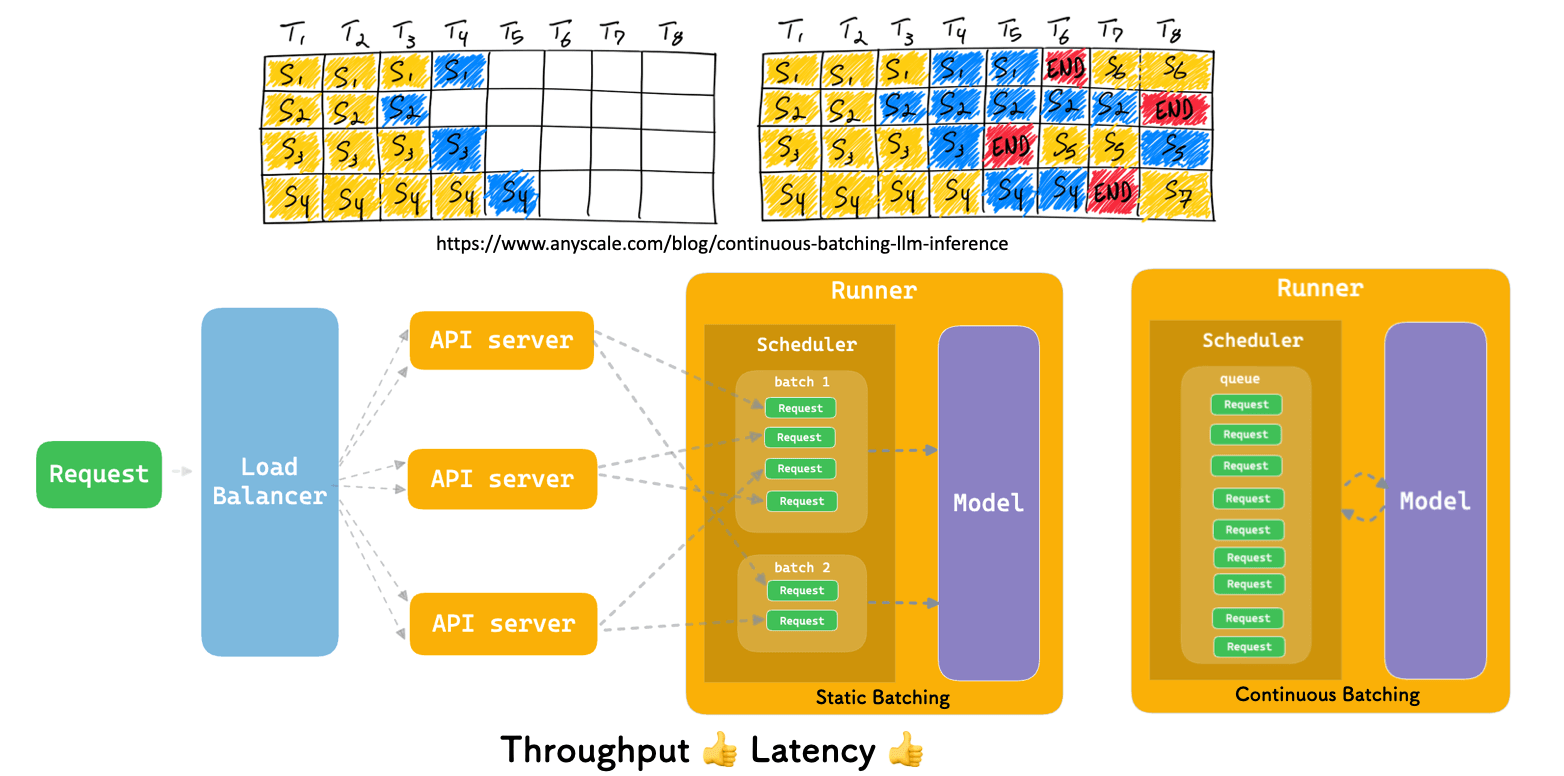
Another important improvement on OpenLLM is continuous batching via vLLM. For a typical Bento, when multiple requests arrive, the API Server scales first and then redirects the requests to the Runner, which batches all the requests to the model. However, this is not sufficient enough for language models.
That's why we need continuous batching. The essence of continuous batching is its dynamic nature. This "giant batch" cyclically processes requests, ensuring that the model remains optimally engaged without unnecessary idle time. See this blog post to learn more.
Why does this matter? For models as complex and resource-intensive as LLMs, the real-time, iteration-level batching ensures maximum resource utilization, faster processing time, and, ultimately, a more cost-effective and responsive system.
Serverless deployment#
In production deployment, it's essential to remember that about 95% of models remain idle most of the time, yet reserved instances continue to generate costs. This is why we need to leverage the power of serverless deployment. Simply put, when there is no request, we want replicas to be scaled down to zero to prevent GPU waste. This represents an important feature of BentoCloud, our serverless platform that allows developers to deploy AI applications in production with ease and speed.
To achieve this, we can use the HPA and the Kubernetes Event-Driven Autoscaler (KEDA) together with three key components - Interceptor, Scaler and Proxy container.
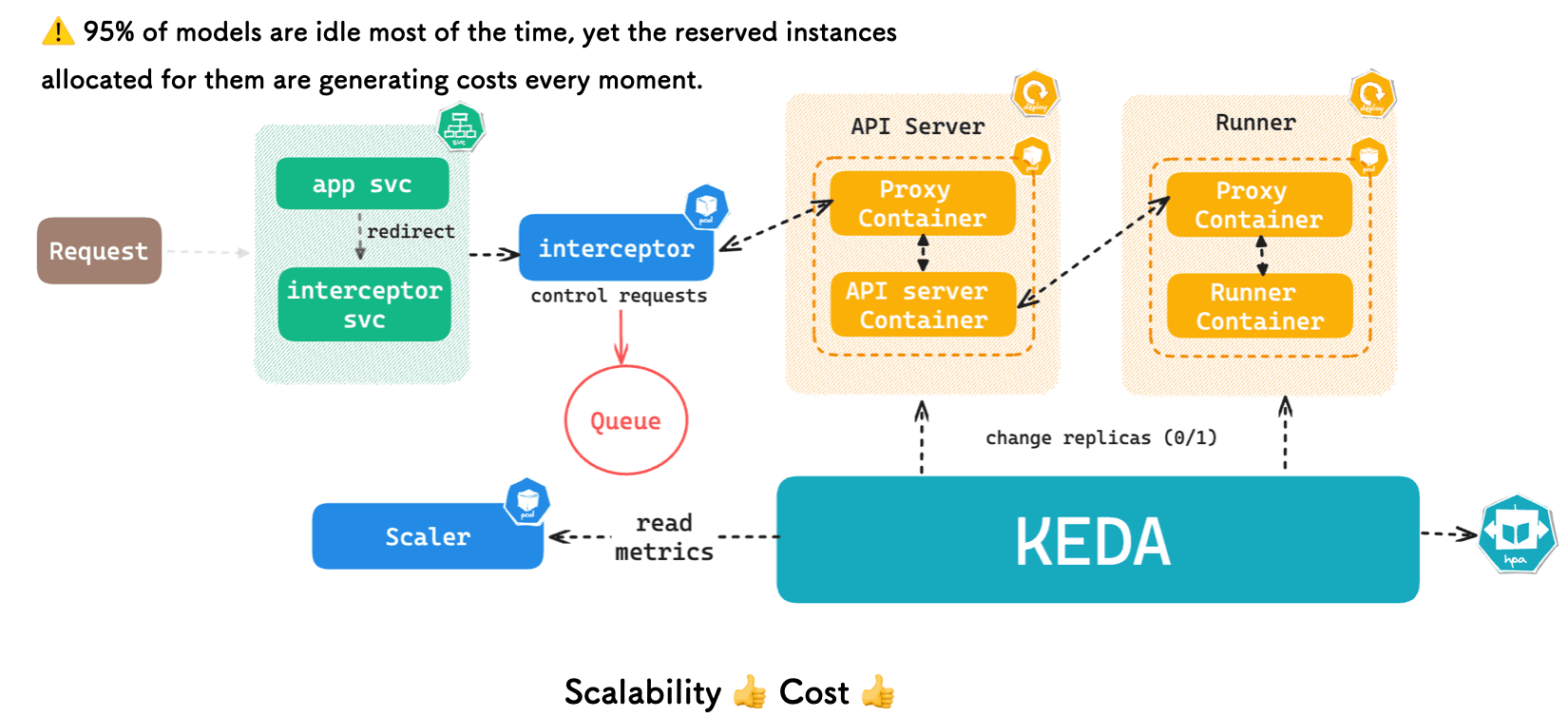
Here's a breakdown of how the process works:
- Idle: If there are no incoming requests, all replicas are scaled down to zero.
- New request arrival: When a request comes in, it's first directed to the Interceptor, which temporarily caches the request.
- Scaling: The Scaler, acting as an external component, informs the KEDA that there's a need to adjust the number of replicas.
- Request processing: Once the KEDA has done its work (scaling), a Proxy container in the API Server retrieves the cached request. This request is then directed to the main API Server for processing.
- Subsequent scaling: Post-processing, the API Server can trigger the Scaler again, optimizing the number of Runner replicas based on the current demand.
Conclusion#
The journey from model to application is undoubtedly challenging. While this article offers one approach to the problem, countless other strategies exist. If you're interested in this, feel free to join our community and we can have further discussions.
More on BentoML and OpenLLM#
To learn more about BentoML and OpenLLM, check out the following resources:
- [Colab] Tutorial: Serving Llama 2 with OpenLLM
- [Blog] Monitoring Metrics in BentoML with Prometheus and Grafana
- [Blog] OpenLLM in Action Part 1: Understanding the Basics of OpenLLM
- [Blog] Deploying An Image Segmentation Model with Detectron2 and BentoML
- [Blog] BYOC to BentoCloud: Privacy, Flexibility, and Cost Efficiency in One Package
- Don’t miss out on the chance to be an early adopter! BentoCloud is still open for early sign-ups. Experience a serverless platform tailored to simplify the building and management of your AI applications, ensuring both ease of use and scalability.