From Ollama to OpenLLM: Running LLMs in the Cloud
Authors

Last Updated
Share

Deploying large language models (LLMs) locally has become increasingly popular due to enhanced data privacy, cost-effectiveness, and zero network dependence. Ollama, a popular local LLM deployment tool, supports a broad range of open-source LLMs and offers an intuitive experience, making it ideal for single-user, local environments. However, challenges arise when expanding beyond single-user applications, such as a chatbot web application that serves thousands of users. Can Ollama meet these expanded requirements in the cloud?
In this blog post, we will explore the following topics:
- Understand what it means to deploy LLMs in the cloud
- Evaluate the performance of Ollama for cloud-based LLM deployment
- Introduce our recommendation for deploying LLMs in the cloud
Cloud LLM deployment#
Before we evaluate how Ollama performs in a cloud environment, it's important to understand what cloud deployment of LLMs means and the key requirements involved. Cloud deployment is not only about hosting and running these models on cloud infrastructure; it involves a set of fundamentally different requirements than local deployments.
Key requirements for running an LLM in the cloud may include:
- High throughput and low latency: In a cloud environment, LLMs must process a large number of requests efficiently and return responses quickly. High throughput ensures the model can handle multiple requests simultaneously without bottlenecks, while low latency is critical for maintaining a seamless user experience, especially in real-time applications such as conversational AI agents.
- Scalability: The cloud's dynamic nature allows you to scale resources up or down based on the demands, thus ensuring cost-efficiency. This is particularly important for LLM applications expected to grow over time or those experiencing different usage patterns.
- Multi-user support: Unlike local deployments that might serve a single user or a limited group, cloud-deployed LLMs must be able to support multiple users concurrently.
Understanding these requirements is the first step in evaluating whether a technology can meet the demands of cloud deployments. In the next section, we will see how Ollama performs in a cloud environment.
Running Ollama in the cloud#
Transitioning from local to cloud deployments, we tested Ollama using the Llama 3 8B model on a single A100-80G GPU instance. We focused on various performance metrics crucial for cloud deployments. Here's a detailed look at our findings.
Throughput#
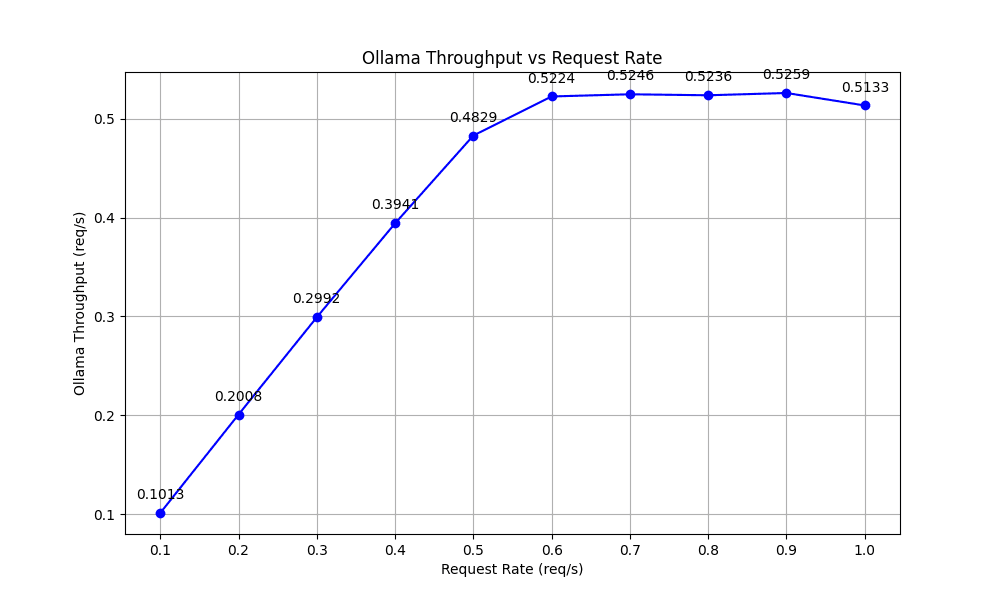
Throughput is a key performance indicator showing how effectively a system handles incoming requests. Our evaluations revealed that Ollama's throughput did not scale with increases in traffic load and remained flat after the request rate topped 0.5 requests per second. This was because Ollama reached its peak decoding capability, queuing excess requests up instead of processing them immediately.
Time to First Token (TTFT)#
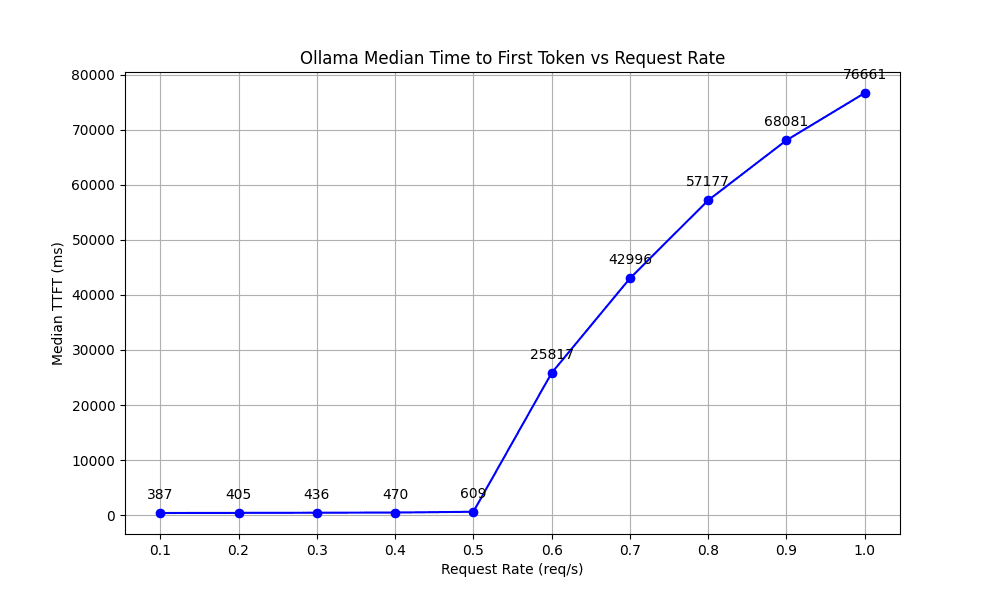
TTFT measures the responsiveness of the system, marking the duration from when a request is sent to when the first token is generated. This metric is important for applications requiring immediate feedback, such as interactive chatbots.
Our tests showed that the TTFT remained steady before 0.5 req/s but increased significantly and unboundedly after due to request queuing delays.
Time per Output Token (TPOT)#
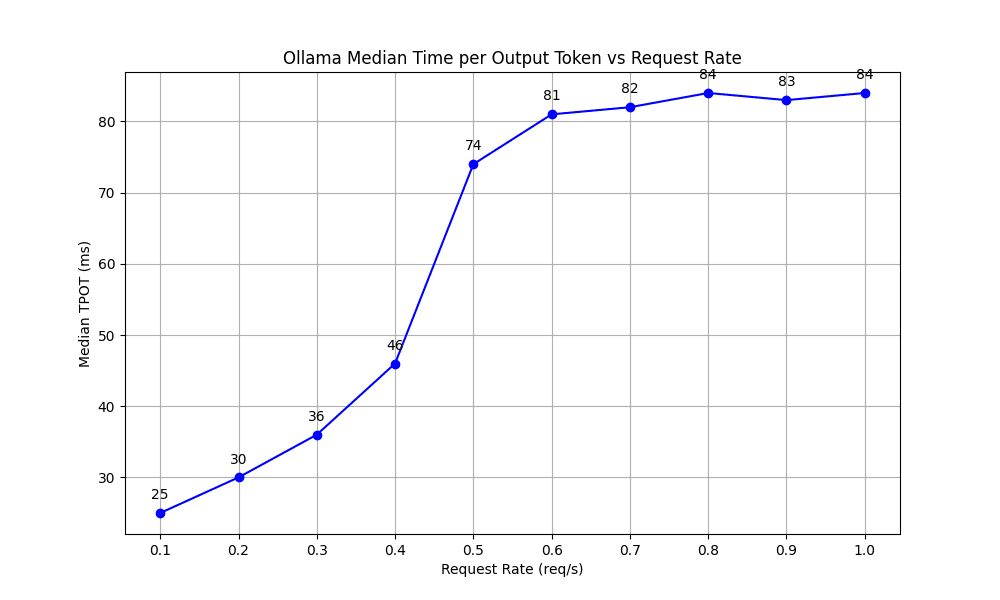
TPOT reflects the processing speed per token, critical for maintaining swift interactions in real-time applications. We observed a stable increase in TPOT as the request rate rose up to 0.5 req/s, after which it leveled off, maintaining a consistent time between 81 and 84 ms.
Token Generation Rate (TGR)#
TGR assesses how many tokens the model generates per second during decoding. The results showed that the TGR increased steadily as the request rate rose, stabilizing around 182 to 186 tokens per second for rates above 0.5 requests per second.
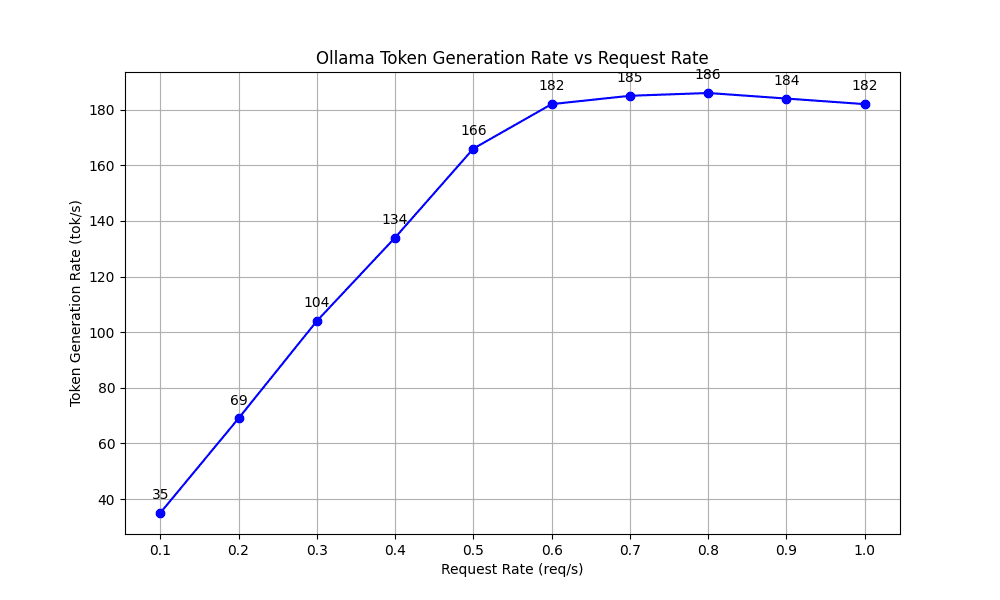
These metrics lead to our initial conclusion: While Ollama performs well at lower request rates (up to 0.6 req/s), its performance in high-load scenarios, which are typical in effective cloud deployments, may be inadequate. As we mentioned in the previous section, cloud LLM deployments require consistent high throughput, low latency and scalability to handle requests from multiple users.
The potential limitation also means the need for a solution that not only matches Ollama's user-friendly experience, but also meets the high demands for throughput and responsiveness in cloud-based LLM applications.
OpenLLM: Run any LLM in the cloud#
With the evaluation results of Ollama in mind, we've significantly revamped our open-source project OpenLLM as a tool that simplifies running LLMs as OpenAI-compatible API endpoints, prioritizing ease of use and performance. By leveraging the inference and serving optimizations from vLLM and BentoML, it is now optimized for high throughput scenarios. This new release also marks a significant shift in our project's philosophy, reflecting our renewed focus on streamlining cloud deployment for LLMs.
Here are the key features of OpenLLM:
State-of-the-art performance#
OpenLLM has been optimized for scenarios demanding high throughput and low latency, making it an excellent tool for running real-time AI agents in the cloud. Here's how OpenLLM performs against Ollama in running Llama 3 8B to handle concurrent requests on a single A100-80G GPU instance:
Throughput#
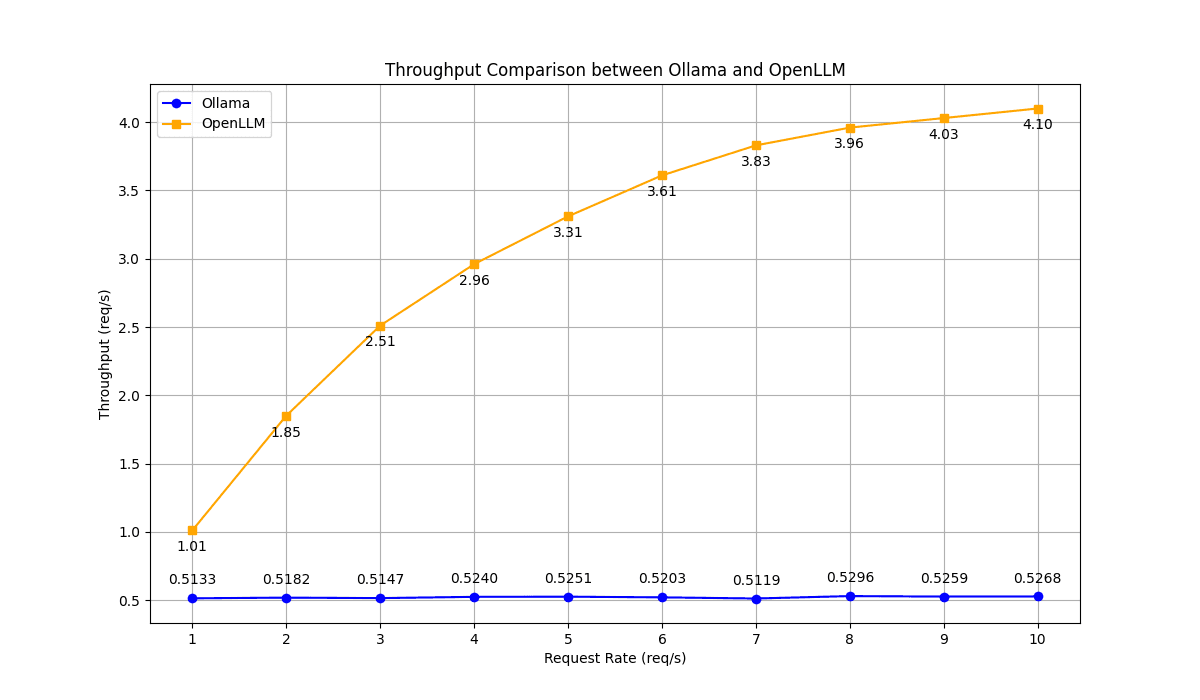
Ollama's throughput remained flat at around 0.5 requests per second throughout the test. In contrast, OpenLLM showcased a stable increase in throughput with growth up to 4.1 requests per second at a load of 10 requests per second, nearly 8x higher than Ollama.
Time to First Token (TTFT)#
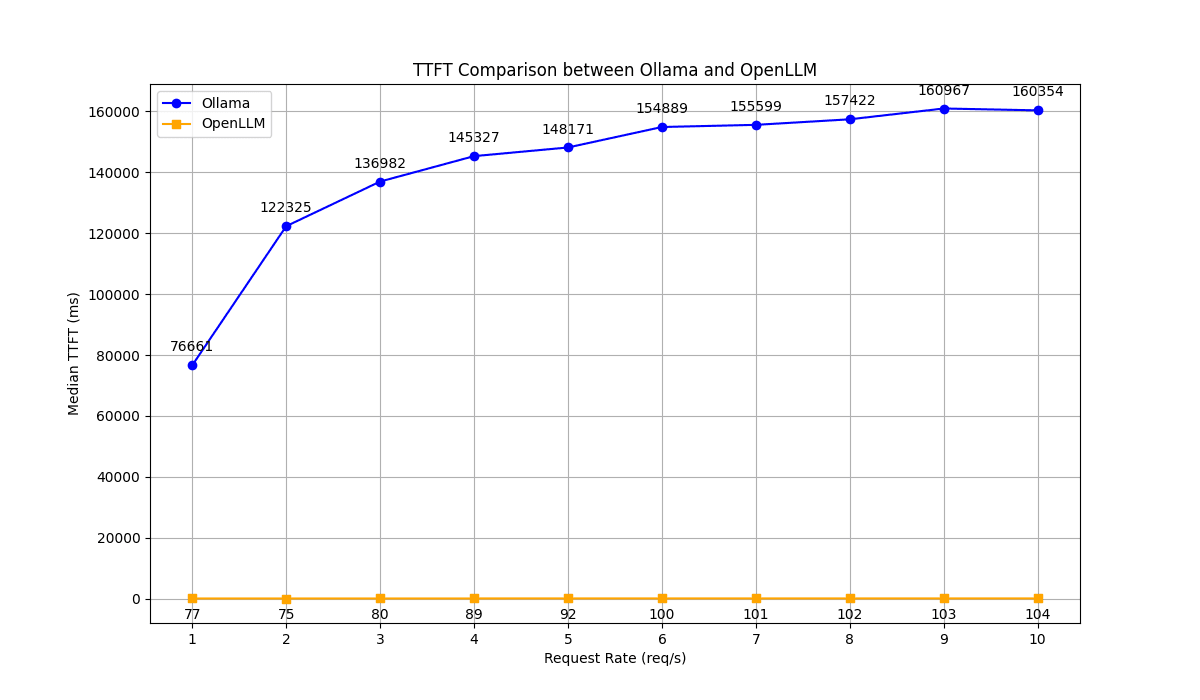
OpenLLM exhibited significantly lower TTFT across all request rates when compared to Ollama, which suggests its better responsiveness.
Time per Output Token (TPOT)#
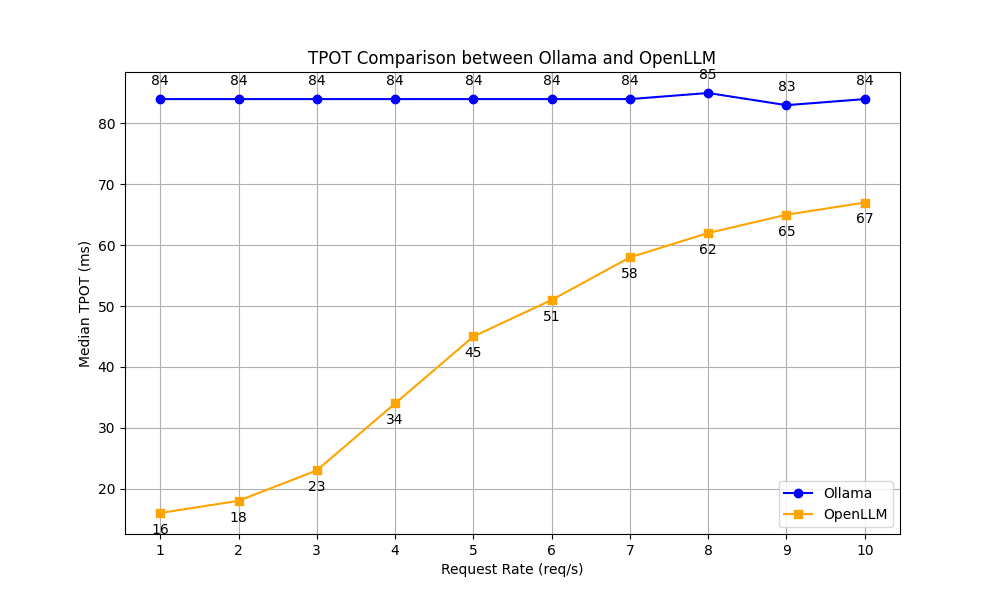
OpenLLM demonstrated significantly faster TPOT than Ollama across all request rates, maintaining a performance advantage of approximately 4x to 5x faster at lower concurrency levels.
Token Generation Rate (TGR)#
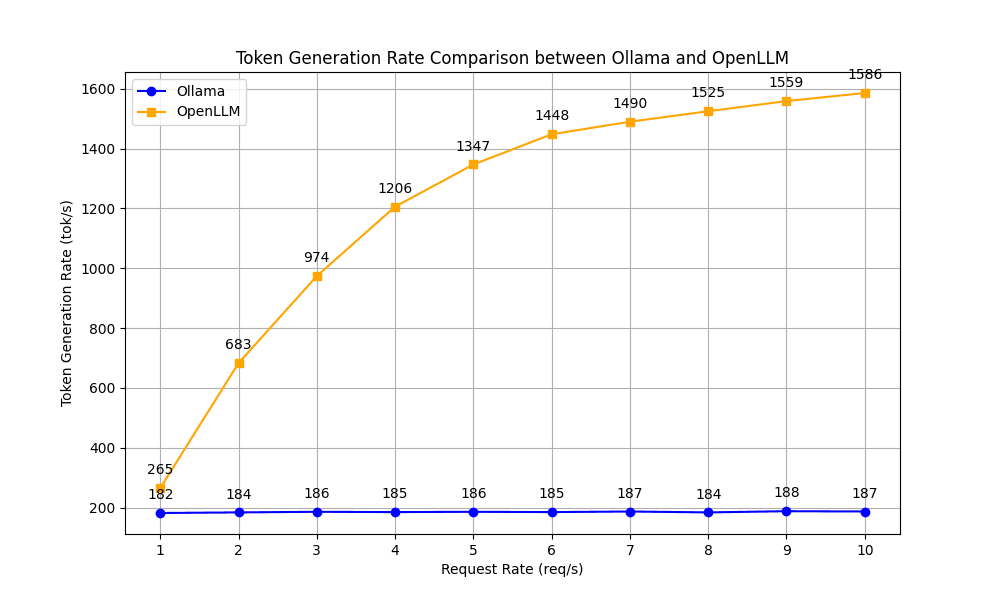
Compared with Ollama, OpenLLM showed an upward trend in TGR as the request rates grew, starting from a much higher base rate (265). This indicates better efficiency, particularly noticeable at higher request rates where OpenLLM reached up to 1586 tokens per second, more than 8 times the rate achieved by Ollama.
OpenAI-compatible APIs#
OpenLLM allows you to run a wide range of open-source LLMs, such as Llama 3, Qwen 2, Mistral, and Phi3, as OpenAI-compatible API endpoints, ensuring a seamless and straightforward transition to utilizing LLMs. See the default model repository to learn more.
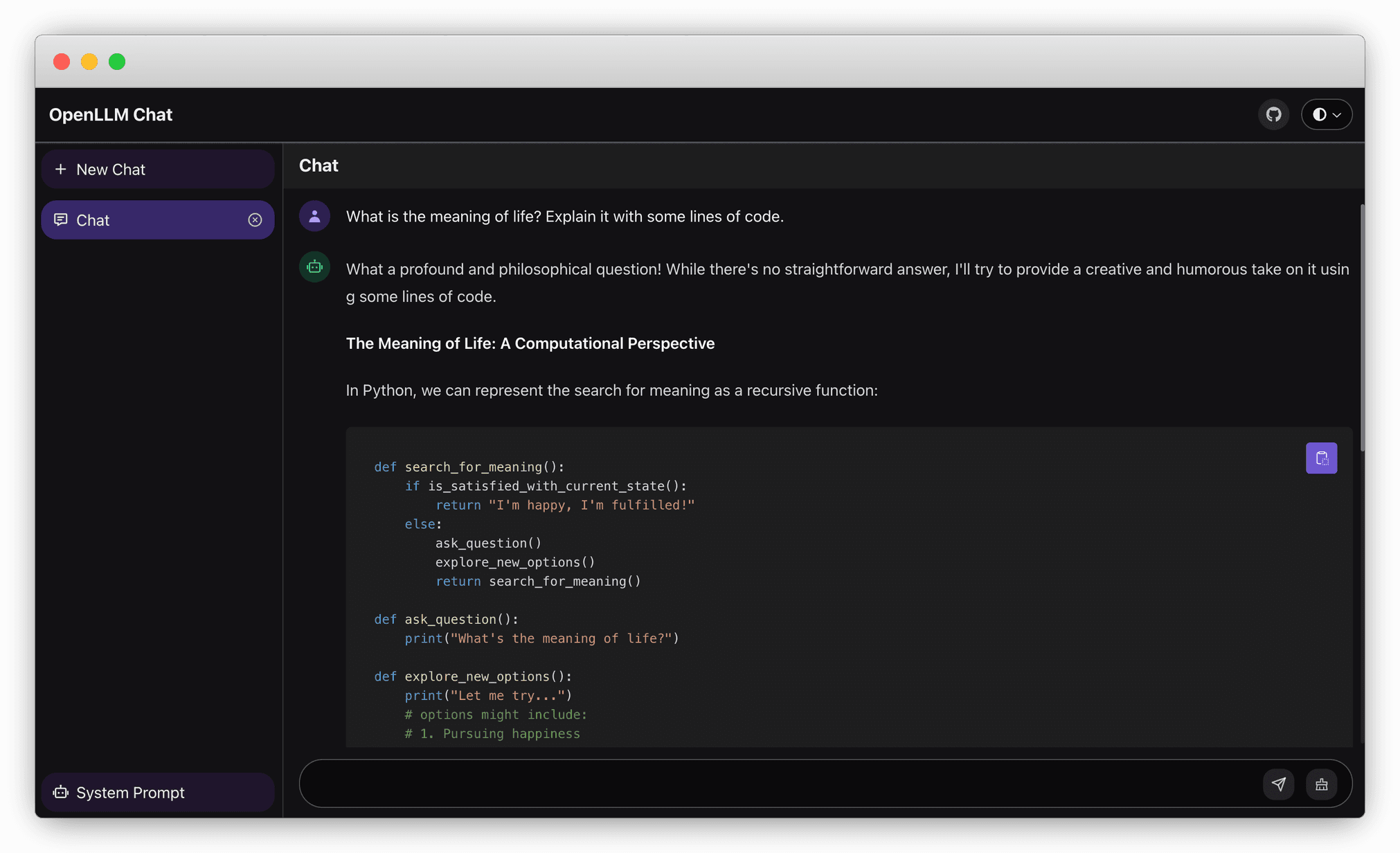
Chat UI#
OpenLLM provides a built-in chat user interface (UI) at the /chat endpoint for an LLM server. You can start multiple conversations with the model in the UI.
Simplified cloud deployment#
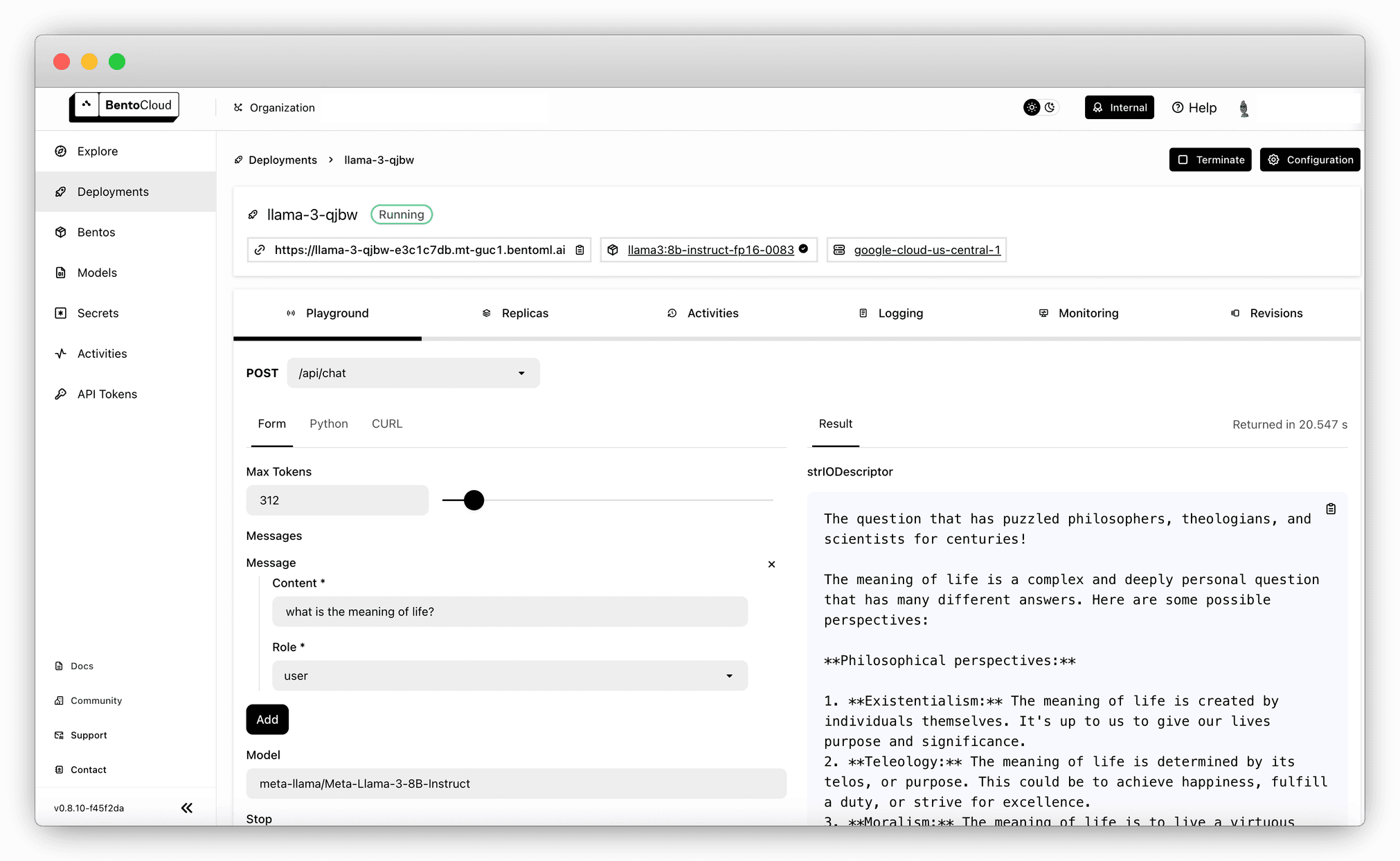
OpenLLM supports one-command deployment to BentoCloud, an inference platform for enterprise AI teams. It provides various GPU types that allow you to run models on fully-managed infrastructure optimized for inference, with autoscaling, built-in observability, and more. BentoCloud’s Bring Your Own Cloud (BYOC) option enhances security, giving you better control over your data and ensuring it never leaves your infrastructure boundary.
Conclusion#
If you are considering deploying an LLM for personal use on your laptop, Ollama is a solid choice, offering developer-friendly features that simply work. However, when it comes to supporting applications with multiple users in the cloud, you need a solution that is able to scale with cloud demands. As shown in our tests, OpenLLM performs better in this regard. It retains the ease of use that Ollama users love and extends it to the cloud with fast scaling and state-of-the-art inference performance, making it the ideal choice for demanding cloud AI applications.