How to Beat the GPU CAP Theorem in AI Inference
Authors


Last Updated
Share

In our 2024 AI Inference Infrastructure survey, one finding stood out: enterprises are struggling with GPU availability and pricing. Why is that?
Different from training, inference is driven by real-time usage, often bursty and unpredictable. It requires on-demand scaling: the ability to have the right amount of compute at the right time.
When enterprises handle inference with a training mindset (e.g., locking in fixed GPU capacity through long-term commitments), they quickly run into trouble:
- Over-provisioning leads to underutilized GPU clusters, wasted resources, and high costs.
- Under-provisioning means dropped requests, slow response time, and poor user experience.
- Inflexible budgeting locks enterprises into rigid spending patterns that don’t adapt to actual usage.
At BentoML, we’ve seen this gap firsthand. Our mission is to make inference as scalable, secure, and cost-efficient as it needs to be.
From our work with enterprise customers, we’ve identified three core dimensions that shape the GPU strategy for AI inference: Control, on-demand Availability, and Price. In this blog post, we’ll explore why it’s so hard to get all three and how BentoML helps make it possible.
Concepts#
Let’s first look at what these three dimensions mean.
Control#
Control means having full ownership over your models and data while staying compliant with regulatory requirements.
Inference workloads often interact directly with sensitive enterprise systems. Common use cases include AI agents, RAG pipelines, and autonomous copilots that rely heavily on proprietary data. These applications might access confidential documents, internal APIs, and customer records. This makes data privacy extremely important.
To protect the data, enterprises must run inference workloads in secure environments they control, such as an on-premises GPU cluster or a virtual private cloud network.
In many industries, compliance is the law. Keeping data and models inside a specific region or data center is required by regulatory frameworks, such as GDPR. For sectors like healthcare, finance, and government, even temporary exposure to external infrastructure can be a deal-breaker.
On-demand availability#
On-demand availability refers to the ability to dynamically scale GPU resources up or down based on real-time workloads. This flexibility is critical because AI inference workloads are rarely consistent. Traffic patterns fluctuate throughout the day, week, or product lifecycle.
When usage grows (e.g., more users are interacting with your product), you need to provision more GPUs to maintain reliable performance. Otherwise, your product quality degrades, leading to service failures.
When traffic drops (e.g., during off-hours), you don’t want to keep paying for idle capacity. Releasing unused compute is essential to keeping infrastructure costs in check.
Without true on-demand availability, enterprises are forced to choose between over-provisioning and under-provisioning. Neither of which is sustainable.
Price#
When enterprises launch AI products, price isn't always the top concern. However, as inference workloads grow, the cost of GPUs quickly becomes one of the largest infrastructure expenses.
In this context, Price refers to the unit cost of GPU compute, not the full total cost of ownership (TCO). This cost can vary significantly depending on where and how you run inference workloads.
The GPU CAP Theorem: Why there is always a compromise#
In GPU infrastructure providers, we see a recurring trade-off between the above three requirements. We call this the GPU CAP Theorem. It means a GPU infrastructure cannot guarantee Control, on-demand Availability, and Price at the same time.
Here’s a closer look at how common GPU infrastructure options fall short:

Hyperscaler#
Hyperscalers like AWS and GCP are widely trusted by enterprises. They offer broad regional access, mature tooling, and integrated services. Many enterprises run critical workloads in their private cloud accounts and benefit from their robust security features.
However, the cost of GPUs on hyperscalers is extremely high. While on-demand provisioning is technically supported, the actual availability is inconsistent. Wait time can stretch from several minutes to hours during periods of high demand.
NeoCloud (Serverless)#
Serverless NeoCloud platforms like Modal and RunPod offer great on-demand availability, featuring elastic scaling and simplified deployment.
That said, these platforms are often multi-tenant, with little visibility into where workloads are running or how your data is handled. For enterprises in regulated industries, this lack of control and transparency is a major red flag.
NeoCloud (Long-term commitments)#
Among NeoClouds, players like CoreWeave offer a cheaper solution through long-term contracts. They allow enterprises to get discounted rates and more predictable pricing. In these cases, control also improves with isolated, single-tenant environments, similar to on-premises solutions.
However, you sacrifice on-demand availability since GPU resources are pre-reserved.
On-premises data center#
Building and managing your own on-premises GPU cluster offers the highest level of control. You have complete ownership of the hardware and network, and can design your infrastructure to meet strict compliance and data security requirements.
But this comes with significant cost and complexity. You’re responsible for procurement, installation, maintenance, and in-house operations. Additionally, you give up on-demand availability. Adding GPUs means long procurement cycles and physical deployment delays.
After examining these options, we realize none of them fully satisfies the three fundamental requirements.
BentoML: Scale AI inference without compromises#
At BentoML, we believe enterprises should have full ownership and flexibility over their compute resources, especially for mission-critical AI products. They should be able to control where inference workloads run, expand capacity when needed, and optimize cost, without sacrificing data security or performance.
This ideal state is known as Compute Sovereignty. The key to achieving it lies in the ability to allocate, scale, and govern GPU compute across on-premises, NeoCloud, multi-region, and multi-cloud environments on their own terms.
Unified compute fabric#
BentoML provides a unified compute fabric. It’s essentially a layer of orchestration and abstraction that allows enterprises to deploy and scale inference workloads across:
- On-premises GPU clusters
- Bring Your Own Cloud (including NeoCloud, multi-cloud and multi-region setups) environments
All through a single, integrated control plane.
When deploying an AI inference service with BentoML, you get API endpoints that can be backed by GPU resources from any mix of the above infrastructure options.
Here is how it works in practice:
- Automatic overflow when needed. If your on-premises cluster (or NeoCloud long-term commitment) runs out of capacity, BentoML can seamlessly overflow traffic to cloud GPUs. This ensures you always have enough compute power as you scale.
- Dynamic provisioning and routing. Within your cloud account, BentoML dynamically provisions GPUs across the most available and cost-efficient regions that you’ve pre-configured. You can run the same model and inference code on a different provider with minimal operational effort. This ensures true on-demand availability.
- Cost optimization with hybrid workloads. BentoML enables you to mix long-term GPU commitments (from on-prem or NeoCloud) with on-demand and spot GPU capacity. This means you can use low-cost, reserved GPUs for baseline workloads and flexibly overflow to cloud GPUs only when needed. This keeps costs predictable without sacrificing scalability.
- Full control over models and data. For organizations with strict security and compliance needs, BentoML provides BYOC (Bring Your Own Cloud) and supports on-premises deployments. This means your inference workloads always stay within your VPC or data center, never on shared infrastructure.
Customer journeys#
The following two examples show how enterprises use BentoML to scale AI inference across different environments. In both cases, the client-side experience remains consistent. Applications only need to call the same API endpoints exposed by BentoML. All the scaling, routing, and infrastructure changes happen behind the scenes, without affecting user experience.
Example one#
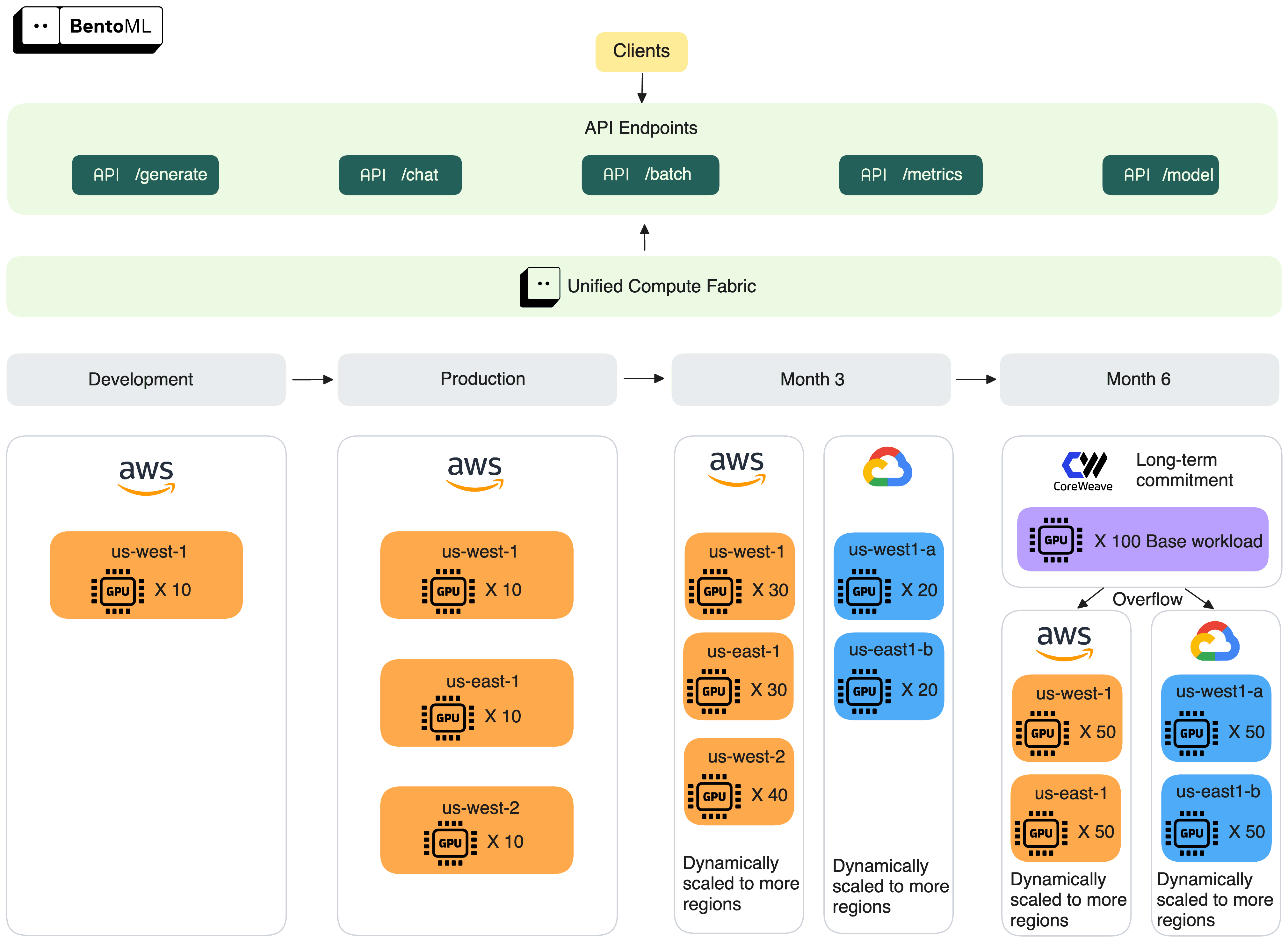
Starting in a single AWS region, this customer expands across multiple regions and clouds. By month 6, they anchor their base workload in long-term GPU commitments, using BentoML to scale overflow across cloud providers.
Example two#
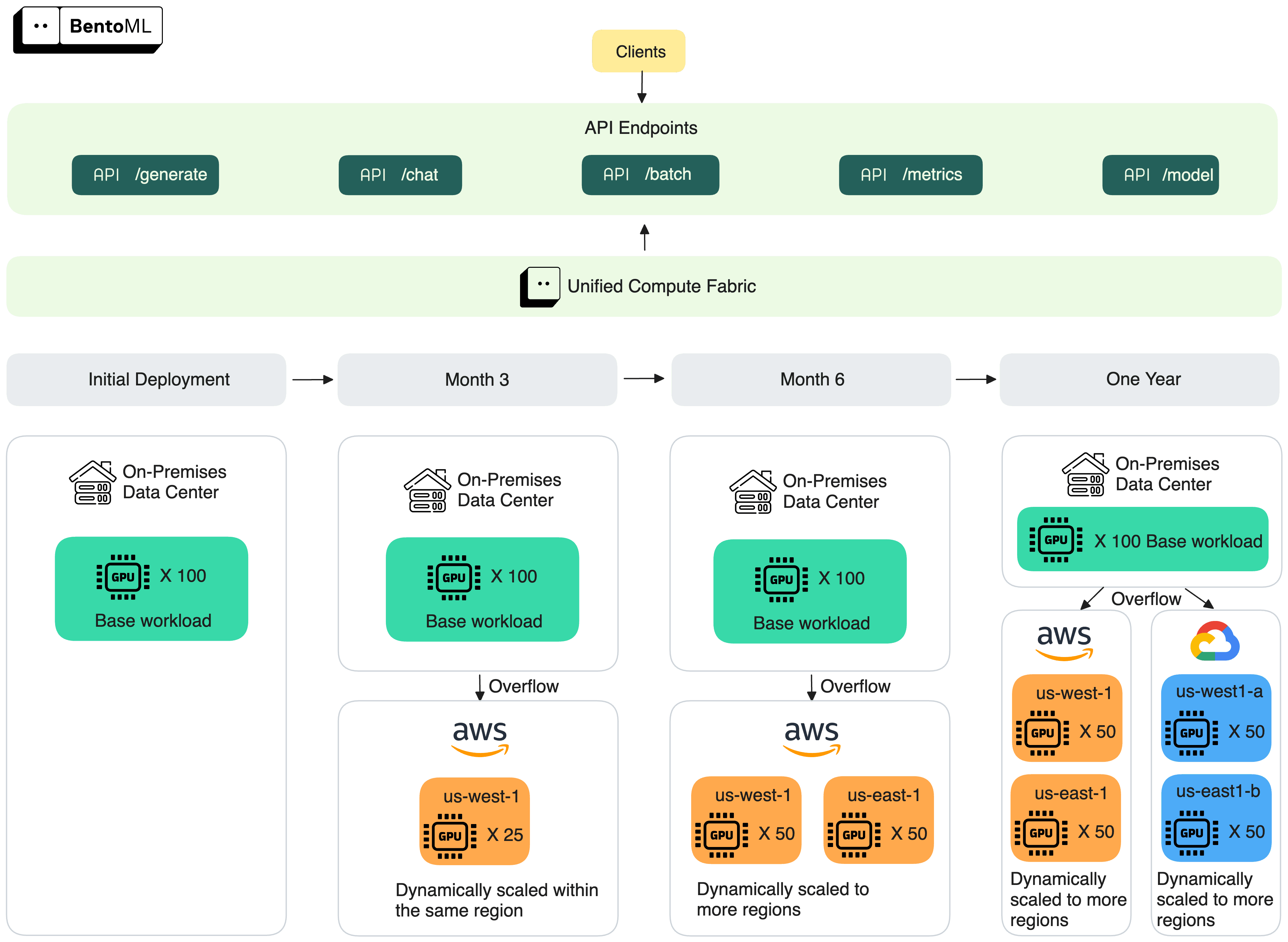
This customer starts with a 100-GPU on-premises cluster. As demand grows, BentoML overflows traffic to AWS and scales across regions, eventually spanning multiple clouds.
Contact Us for Your Use CaseContact Us for Your Use Case
Conclusion#
As AI adoption accelerates, inference infrastructure must evolve to meet the growing demands of security, scaling, and cost-efficiency. The GPU CAP Theorem makes it clear: existing solutions force enterprises to compromise.
At BentoML, we believe you shouldn’t have to choose. Our unified compute fabric gives you the control, on-demand availability, and price flexibility you need to run inference at scale on your terms.
Learn more:
- Choose the right NVIDIA or AMD GPUs for your model
- Choose the right deployment patterns: BYOC, multi-cloud and cross-region, on-prem and hybrid
- Talk to our experts to learn how we can support your specific use case
- Join our community forum to connect with other builders and share feedback with our team
- Sign up for our unified inference platform to get started