Introducing BentoML 1.0
Authors

Last Updated
Share

The Unified Framework For Model Serving#
When we first open sourced the BentoML project in 2019, our vision was to create an open platform that simplifies machine learning model serving and provide a solid foundation for ML teams to operate ML at production scale. After years working together with our community towards that goal, we decided to embark on a journey towards a 1.0 version. And today, we’re thrilled to announce the general availability of BentoML 1.0!
But First, What Is Model Serving?#
For those who may be unfamiliar with the term, model serving is the process of applying machine learning models to applications and making predictions in real-time. In the last decade, we saw a shift in how businesses uses machine learning as an integral part of their product offering, making operating ML in production an even more critical endeavor.
Here’s what I mean:
Traditionally, data scientists used to train ML models, then present their predictions or projected forecasts on a dashboard for executives. These decisions were made after-the-fact, in a time-delayed manner. In the last decade, we’ve seen the rise of real-time use cases where models exposed to other services can now ask for immediate results. Netflix and Amazon pioneered AI-led recommendations and benefited greatly from the ability to provide users with more interesting options while they were actively engaged in the product.
Today, there are endless use cases that rely on such real-time machine learning systems, from fintech fraud detection to chatbots analyzing intent and sentiment of customer support inquiries.
What Is BentoML?#
BentoML is an open-source framework for serving ML models at production scale. Data Scientist and ML Engineers use BentoML to:
• Accelerate and standardize the process of taking ML models to production across teams
• Build reliable, scalable, and high performance model serving systems
• Provide a flexible MLOps platform that grows with your Data Science needs
BentoML has a thriving community of open source contributors who have built out an ecosystem of ML serving and deployment tools. These tools are built on top of the core BentoML library. Join our community slack and check out how you can contribute on our Github project
What’s Brand New In BentoML 1.0?#
When designing and building BentoML 1.0 our primary focus was to be able to provide users with a high-performance framework that was also easy to use. This resulted in 3 primary focus areas:
• The BentoML Runner: A purpose built ML abstraction for running inference at scale
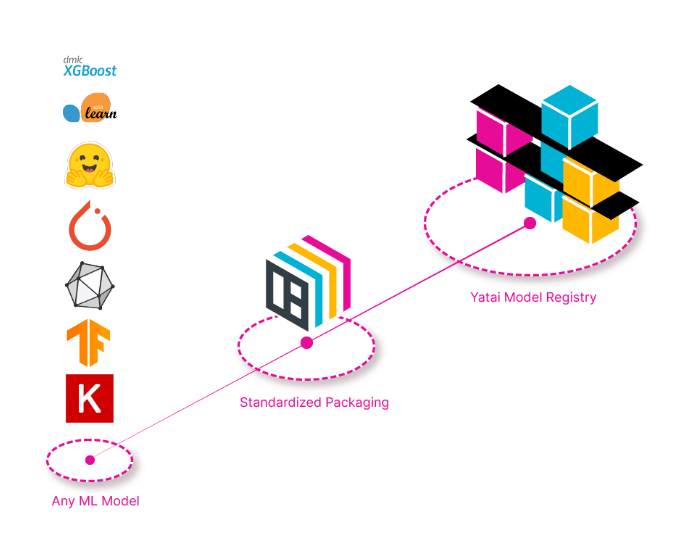
• Standardized packaging tools for saving, loading and managing models (and bentos)
• Integration with Yatai, our new platform for running Bentos at scale in production

With these new enhancements, we feel confident that BentoML not only handles a wide variety of use cases but also that it can provide users with the flexibility and performance that they need as they scale ML workloads.
The BentoML Runner#
The BentoML Runner is an abstraction for parallelizing model inference workloads. It is designed for online model serving scenarios where each stage of the serving pipeline can be demanding different types of resources, such as CPU, GPU, IO, or memory. Most significantly, Runner makes it easy to parallelize the compute intensive model inference workers, apply adaptive batching to its computation, and scale them separately from the feature transformation and business logic.
BentoML 1.0 makes it efficient to run model serving workloads that involves custom pre- and post-processing log as well as inference pipelines that involves multiple ML models. Advanced users can also fine-tune the batching behavior and resource allocation for each step in the serving pipeline. GPU supports has also been drastically simplified comparing to prior versions.
And for all of the domain specific challenges which a user might encounter, we offer a simple way of customizing and extending the runner.
New And Enhanced Primitives For Model Management#
Our users have introduced us to many different scenarios over the years. One thing that we hear often is that they need better tools to manage how the model is persisted, stored, and how it’s loaded back into memory to be invoked again.
It is, for this reason, we redesigned how models are saved, moved, and loaded with BentoML. We introduced new primitives which allow users to call a save_model() method which saves the model in the most optimal way based on the recommended practices of the ML framework. The model is then stored in a flexible local repository where users can use “import” and “export” functionality to move “finalized” models to remote locations like S3, or "push to" and "pull from" Yatai, the centralized repository for BentoML.
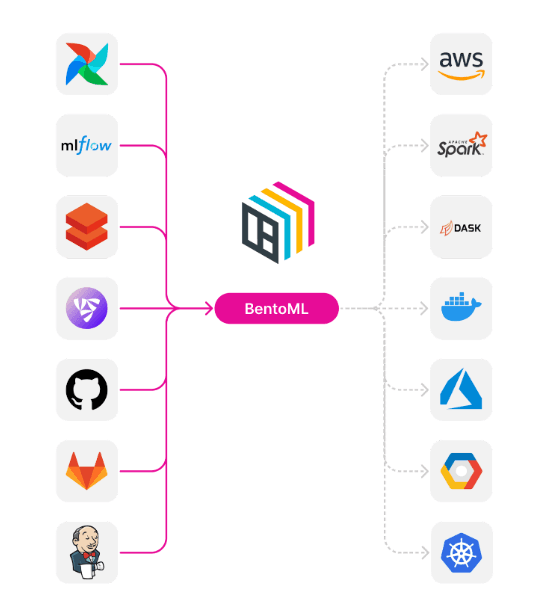

These new features give users flexibility so that BentoML can easily be integrated with existing CI/CD pipelines and follow DevOps best practices when deploying ML services.
Yatai: Production-First ML Platform On Kubernetes#
Yatai is a new project (currently in beta) which we’ve built for users looking to scale their model deployment in production. It’s an open platform built to improve collaboration across data science and engineering while offering all the requirements to run complex ML workflows.
The main Yatai interface gives visibility into the different models and bentos which have been saved across teams and which ones are currently running in production. We integrate with a wide range of cloud native tools to give you DevOps best practices out of the box.
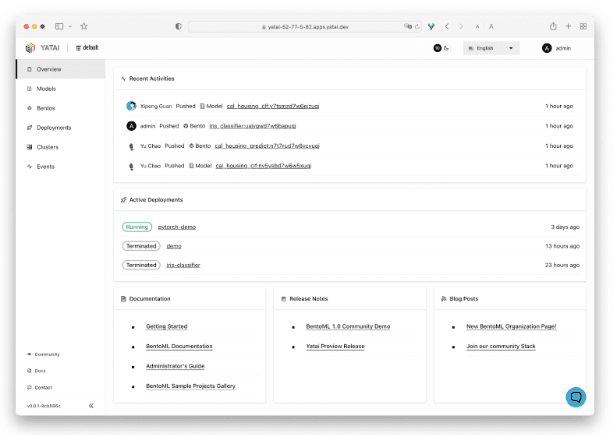

Yatai provides a simple foundation for integrating with your existing training pipelines and your Kubernetes deployments. ML engineers can easily create Kubernetes configurations that can be applied programmatically, or they can use the UI to deploy to any given cluster.
Yatai optimizes BentoML model serving pipelines in a distributed environment. When deploying Bentos, Yatai automatically optimizes the deployment architecture for executing Runners defined in a Bento. In a most common case, each model is deployed into a separate autoscaling group with its own resource requests. This provides maximum flexibility as you scale even more complicated inference graphs.
While you may always use your own tools for log management and metric gathering, Yatai provides these features automatically for production scale. In the future, we are also planning on enabling Data Scientists to easily set up model monitoring and online experiments.
What’s Back And Better Than Ever In BentoML 1.0?#
Adaptive Micro Batching#
Micro-batching is one of our most popular features for high throughput use cases. With the new runner abstraction, batching is even more powerful. When incoming data is spread to different transformation processes, the runner will fan in inferences when inference is invoked. Multiple inputs will be batched into a single inference call. Most ML frameworks implement some form of vectorization which improves performance for multiple inputs at once.
Our adaptive batching not only batches inputs as they are received, but also regresses the time of the last several groups of inputs in order to optimize the batch size and latency windows.
Dependency Management#
In order to ensure the reproducibility of the model, BentoML has always recorded library versions when saving a model. We use the versions to package the correct dependencies so that the environment in which the model runs in production is identical to the environment it was trained in. All direct and transitive dependencies are recorded and deployed with the model when running in production. In our 1.0 version we now support Conda as well as several different ways to customize your pip packages when “building your Bento”.
Docker Image Generation#
Ever struggled with getting the right distribution along with the right libraries and tools stuffed into your docker image? We’ve completely revamped our docker image creation to generate the right image for you depending on the features that you’ve decided to implement in your service. For example, if your runner specifies that it can run on a GPU, we will automatically choose the right Nvidia docker image as a base when containerizing your service. To optimize the build process, we also cache your pip libraries between docker builds.
If needed, we also provide the flexibility to customize your docker image as well.
Input Data Validation#
Among many other things, it has never been easier to configure specification of your prediction service API and validate input data received. We introduced the ability to validate Numpy and Pandas DataFrame base on its shape and dtype, or even dynamically infer schema by providing sample data. For structure input data with JSON, BentoML now supports using pydantic as a means for validation. The input output schema that is produced per endpoint also integrates with our OpenAPI and Swagger UI, making sure that your prediction service is well documented and can be easily integrated into applications.
What’s The Community Saying?#
In the last several months, users from our community have been testing and running our 1.0 beta version to validate the design principles and ensure the scalability in production. Here’s what they’ve been saying so far:
“BentoML 1.0 is helping us future-proof our machine learning deployment infrastructure at Mission Lane. It is enabling us to rapidly develop and test our model scoring services, and to seamlessly deploy them into our dev, staging, and production kubernetes clusters.”
• BentoML 1.0 has helped speed up our adoption and deployment of new ML services. Thanks to the BentoML community for all of the support!
Almir Bolduan from Magazord Tecnologies
• Thank you everyone in the community for contributing to BentoML 1.0 development and helping with beta testing in the past few months!
Ready To Try Out BentoML?#
After years of seeing hundreds of model serving use cases, we’re proud to present the official release of BentoML 1.0. We could not have done it without the growth and support of our community. With over 100 contributors on our Github repo and a rapidly growing Slack group (join us!), we’re happy to see that users are adopting BentoML so quickly.