Model Serving With BentoML And Continuous Retraining
Authors

Last Updated
Share

Originally posted on the Shopback Tech Blog.
Introduction#
In the modern tech scene, microservice architecture has become the norm for engineering teams to surface their work (services), which is later consumed by others. Same goes for data products such as machine learning models and recommendation systems. In this article, we will share the challenges that we encountered and the learnings from serving our model online. We will also talk about our approach in automating the retraining process to complete the whole MLOps cycle.
PS : If you missed our previous posts in this trilogy, do check it out here, part 1 and part 2.
TLDR : We built a merchant recommendation system using a sequential based deep learning model, and we talked about how we conducted our A/B Test offline and online to validate the performance of the model.
Serving Model As Microservice#
Similar to other tech companies, Shopback’s engineers surface their product through a microservice. Once we have completed the exploration phase and offline experimentation phase for our machine learning model, it is time to build a web service to serve our model.
The Vanilla#
One might ask, isn’t this a trivial task? There are hundreds of articles online giving instructions on how to serve a model in a web service. Just load the model into the memory of a Flask or FastAPI app during startup, then invoke the predict function of the model every time a prediction request comes in.
Indeed, that was our initial setup as well. However, it did not take us long to realise that the web service will be unresponsive while the model is making predictions, and the model is only able to predict one request at a time.
Furthermore, it takes about 100ms for the web service to make each prediction. That means for a single worker service, the best that we can achieve is 10 RPS. If the web service receives 10 requests at once, one of the requests will take as long as 1 second before getting a response. This was a serious scalability issue that needed to be addressed.
Looking For Solution#
The easy solution? Just scale horizontally with multiple pods in Kubernetes, and scale vertically to run multiple workers on each pod. However, we knew that there should be alternatives that could allow us to utilize the compute resources more efficiently. Like our Head of Data, Yann, always said,
“Scalability is about reducing cost per usage as the usage increases.”
We went ahead and explored several model serving frameworks such as:
2. BentoML
3. MLflow Serving
MLflow Serving does not really do anything extra beyond our initial setup, thus we decided against it. We benchmarked both Tensorflow Serving and BentoML, and it turns out that given the same compute resource, they both significantly increase the throughput of the model from 10 RPS to 200–300 RPS. This improvement is predominantly contributed by the feature that both frameworks offer — (Micro) Batching.
What Is Micro Batching?#
Machine learning models’ throughput generally benefits from batching predictions, i.e, predicting 10 data points in a batch is generally faster than predicting them sequentially. Therefore, when the model receives several requests within a short period of time, (e.g 50ms), instead of predicting one by one, we could group these requests together and run a batch prediction.
In the end, we decided to choose BentoML due to its simplicity as it includes both pre-processing and post-processing workflows within the framework. We highly recommend you to try BentoML if you are looking for an off the shelf framework for simple model serving with high performance!
More technical details about batching algorithm by BentoML and Tensorflow.
Continuous Training#
To keep our model fresh, we built an automated retraining pipeline that will run weekly, as illustrated below:
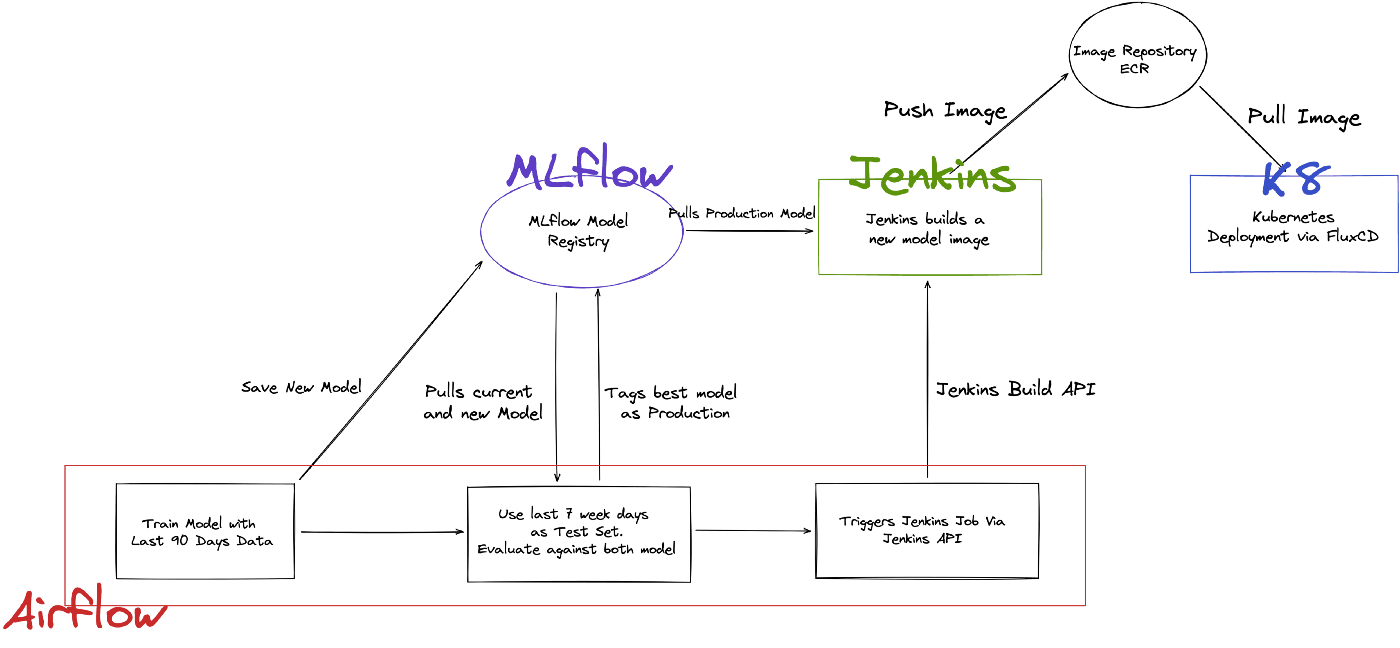
Model Retraining Flow
The whole retraining flow does the following:
1. Pulls last 90 days of data.
2. Use the first 83 days as training set, and last 7 days as test set.
3. Train a new model using the training set.
4. Saves the new model to MLflow.
5. Pull the current model and new model from MLflow, and evaluate both of them using the test set.
6. Sets production tag for the better performing model in MLflow.
7. Triggers a Jenkins Job that will pull the production model from MLflow, builds a new docker image, and push to our image repository.
8. At the same time, Jenkins will trigger a Pull Request to our Github Repository.
9. Once PR is merged, FluxCD detects new change in repository, and triggers a new Kubernetes Deployment.
This workflow will run every week.
The Whole Picture#
Piecing every component together that we discussed about in this series, the figure below illustrates the whole end to end architecture of our merchant recommendation engine.
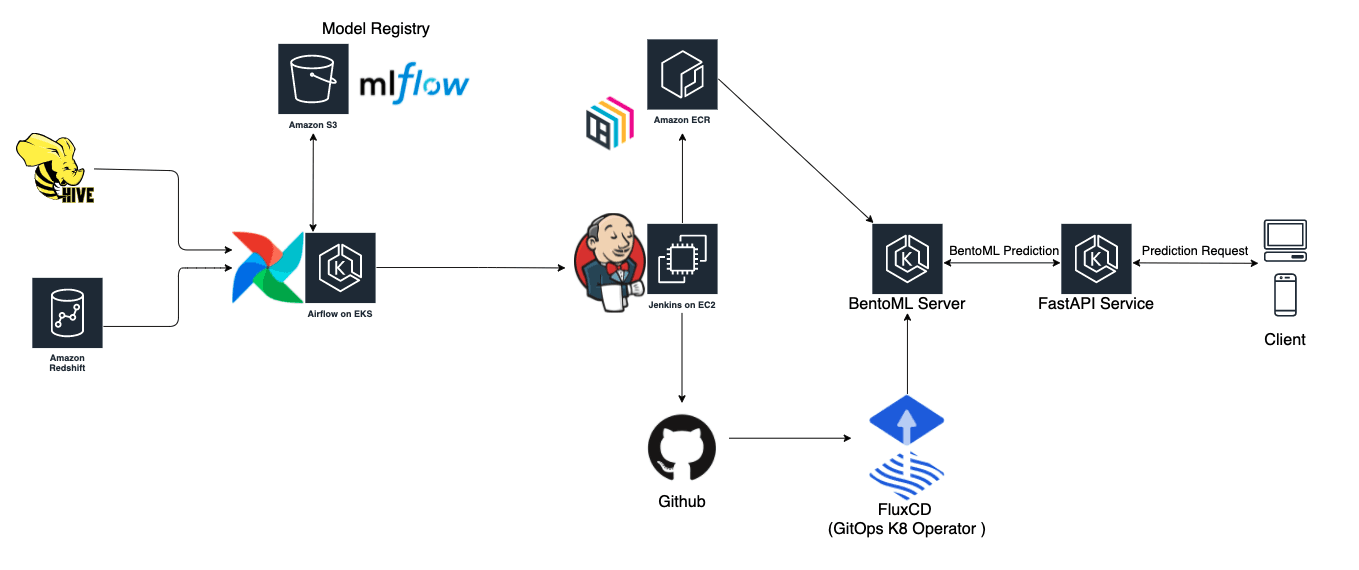

High Level Architecture for Merchant Recommendation Engine
The key components are:
• Model Serving : BentoML
• Model Client Service : FastAPI
• CI/CD/CT : Jenkins, Github, FluxCD
• Orchestration: Airflow
• Data Source : Redshift, Hive on s3
• Model Tracking and Registry : MLflow
There are two service components here for model serving, a BentoML service and FastAPI service. FastAPI service is responsible to perform lightweight processing, and forwards the heavy weight prediction task to BentoML. Another reason for such design is that as we iterate and build better models, we can deploy several BentoML services for A/B Testing, and simply configure FastAPI service to do the appropriate traffic routing.
Closing Thought#
It was a fruitful learning experience, to set up an end-to-end machine learning pipeline from scratch within a few months. At some point of time, as the company grows, we might scrap the current design and explore other options such as building a more generalized ML Platform, switching to the full MLOps suite such as Kubeflow and Seldon, or using a fully managed service like AWS Sagemaker. Nevertheless, this process allowed us to understand the pain points of a machine learning workflow, thus allowing us to build better products in our future projects.
MLOps standards are still constantly evolving, and we are a growing team that is nowhere near the best, so any feedback is highly appreciated! Do leave your comments below if you have questions or suggestions on how we can do better!
❗️ Interested in what else we work on?
Follow us (ShopBack Engineering blog | ShopBack LinkedIn page) now to get further insights on what our tech teams do!
❗❗️ Or… interested in us? (definitely, we hope)
Check out here how you might be able to fit into ShopBack — we’re excited to start our journey together!