The Best Open-Source LLMs in 2026
Authors

Last Updated
Share

The rapid rise of large language models (LLMs) has transformed how we build modern AI applications. They now power everything from customer support chatbots to complex LLM agents that can reason, plan, and take actions across tools.
For many AI teams, closed-source options like GPT-5.5 and Opus-4.6 are convenient. With just a simple API call, you can prototype an AI product in minutes — no GPUs to manage and no infrastructure to maintain. However, this convenience comes with trade-offs: vendor lock-in, limited customization, unpredictable pricing and performance, and ongoing concerns about data privacy.
That’s why open-source LLMs have become so important. They let developers self-host models privately, fine-tune them with domain-specific data, and optimize inference performance for their unique workloads.
In this post, we’ll explore the best open-source LLMs. After that, we’ll answer some of the FAQs teams have when evaluating LLMs for production use.
What are open-source LLMs?#
Generally speaking, open-source LLMs are language models whose architecture, code, and weights are publicly released so anyone can download them, run them locally, fine-tune them, and deploy them in their own infrastructure. They give teams full control over inference, customization, data privacy, and long-term costs.
However, the term “open source” is often used loosely. Many models are openly available, but their licensing falls under open weights, not traditional open source.
Open weights here means the model parameters are published and free to download, but the license may not meet the Open Source Initiative (OSI) definition of open source. These models sometimes have restrictions, such as commercial-use limits, attribution requirements, or conditions on how they can be redistributed.
The OSI highlights the key differences:
| Feature | Open Weights | Open Source |
|---|---|---|
| Weights & Biases | Released | Released |
| Training code | Not shared | Fully shared |
| Intermediate checkpoints | Withheld | Nice to have |
| Training dataset | Not shared or disclosed | Released (when legally allowed) |
| Training data composition | Partially disclosed or not disclosed | Fully disclosed |
Both categories allow developers to self-host models, inspect their behaviors, and fine-tune them. The main differences lie in licensing freedoms and how much of the model’s training pipeline is disclosed.
We won’t dive too deeply into the licensing taxonomy in this post. For the purposes of this guide, every model listed can be freely downloaded and self-hosted, which is what most teams care about when evaluating open-source LLMs for production use.
GLM-5.2#
GLM-5.2 is the latest flagship LLM from Z.ai, built for agentic engineering, software development, and long-horizon reasoning tasks. It builds on the foundation of GLM-5.1 and expands the context window to 1 million tokens (which seems to become a standard among frontier open-source LLMs).
Architecturally, GLM-5.2 retains the GLM-5 backbone: a 754B-parameter MoE model with 40B active parameters per token. It also continues to use DeepSeek Sparse Attention (DSA) to make long-context inference more computationally efficient.
GLM-5.2 is released under the MIT license, supporting commercial use, modification, and distribution without restrictions.
Why should you use GLM-5.2:
- State-of-the-art coding performance. GLM-5.2 leads on software engineering and terminal-execution benchmarks (e.g., SWE-Bench Pro, Terminal-Bench 2.1, FrontierSWE), some even surpassing GPT-5.5 and Claude Opus 4.8. It also supports multiple thinking effort levels now to balance performance and latency.
- Built for repository-scale, long-horizon work. The 1M context is the practical centerpiece. It allows coding agents to keep entire mid-sized repositories in context, avoiding the constant compaction that smaller windows force.
- IndexShare. GLM-5.2 adds a new long-context optimization called IndexShare. Instead of recomputing a separate sparse-attention indexer at every layer, IndexShare reuses the same indexer across each group of four sparse-attention layers. Z.ai reports this cuts per-token compute by roughly 2.9× at the full 1M-token context, a meaningful serving saving for long-context agentic workloads.
If your application combines reasoning, coding, and agentic tasks together, GLM-5.2 is a strong candidate. For teams with limited resources, I recommend GLM-4.7-Flash. It's a lightweight 30B MoE model with strong agentic performance and better serving efficiency (e.g., for local coding and agentic tasks).
MiniMax-M3#
MiniMax-M3 is a MoE model built for long-horizon agentic coding and complex task execution, with 428B total parameters (23B active per token).
The biggest upgrade is MSA (MiniMax Sparse Attention), a new sparse attention design that makes it possible to support a 1M context window. MiniMax reports the new architecture cuts per-token compute at 1M tokens to roughly 1/20 of the previous generation, with about 9× faster prefilling and 15× faster decoding.
Why should you use MiniMax-M3:
-
Frontier coding and agentic performance. M3 reaches the frontier among open models on software engineering benchmarks and is close to Opus 4.7 and GPT 5.5. It's tuned for multi-turn collaboration rather than single-shot generation through an interactive user simulator during training. This enables it to clarify requirements, adjust solutions, and iterate with you across a session.
For best results, pair M3 with MiniMax Code, the agent harness trained alongside the model. The Agent Team feature can decompose large tasks into concurrent, self-correcting workflows and run for days without human intervention.
-
Ultra-long, sustained autonomous work. The 1M context window via MSA is built for tasks that span a long thread. In MiniMax's internal tests, M3 reproduced an ICLR paper autonomously over ~12 hours (18 commits, 23 experimental figures), and optimized a Hopper FP8 GEMM CUDA kernel over ~24 hours, pushing hardware peak utilization from 7.6% to 71.3% (a 9.4× speedup) across 147 benchmark submissions. By comparison, most other models stalled within the first 30.
-
Native multimodality and computer use. M3 was trained mixed-modality from step 0. It accepts image and video input and can operate a desktop computer, letting it drive cross-application workflows.
Note that MiniMax-M3 is released under the MiniMax Community License, which carries commercial-use conditions.
Deploy MiniMax-M3Deploy MiniMax-M3
DeepSeek-V4#
DeepSeek came to the spotlight during the “DeepSeek moment” in early 2025, when R1 demonstrated ChatGPT-level reasoning at significantly lower training costs. The latest release DeepSeek-V4 is designed for long-context reasoning, coding, and agentic workflows, with two large MoE models:
- DeepSeek-V4-Pro (1.6T total, 49B active) is the flagship model for maximum reasoning, coding, and agentic performance.
- DeepSeek-V4-Flash (284B total, 13B active) is a more cost-efficient option. It trails Pro on knowledge-heavy tasks due to a smaller scale, but can reach comparable reasoning performance when given a larger thinking budget.
Both variants are pre-trained on over 32T tokens and support a one-million-token context window.
The architecture introduces a hybrid attention mechanism combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) to improve long-context efficiency. Simply put, instead of storing and attending to every token, DeepSeek compresses the KV cache into summaries at different levels.
- In CSA, small chunks of tokens are summarized and each new token attends only to a small set of the most relevant summaries, reducing unnecessary computation.
- In HCA, much larger chunks are aggressively compressed into a single representation, providing a cheap global view of the entire context.
These two mechanisms are interleaved across layers, so the model continuously balances fine-grained reasoning with coarse global awareness. A sliding window of recent tokens is kept uncompressed to preserve local accuracy. Learn more in the tech paper.
DeepSeek-V4 is released under the MIT license, supporting commercial use, modification, and distribution with minimal restrictions.
Why should you use DeepSeek-V4:
-
Frontier-level reasoning and coding. DeepSeek-V4-Pro is one of the strongest open-source models for reasoning-heavy and coding-heavy workloads. The max mode shows competitive results across major reasoning and agentic benchmarks.
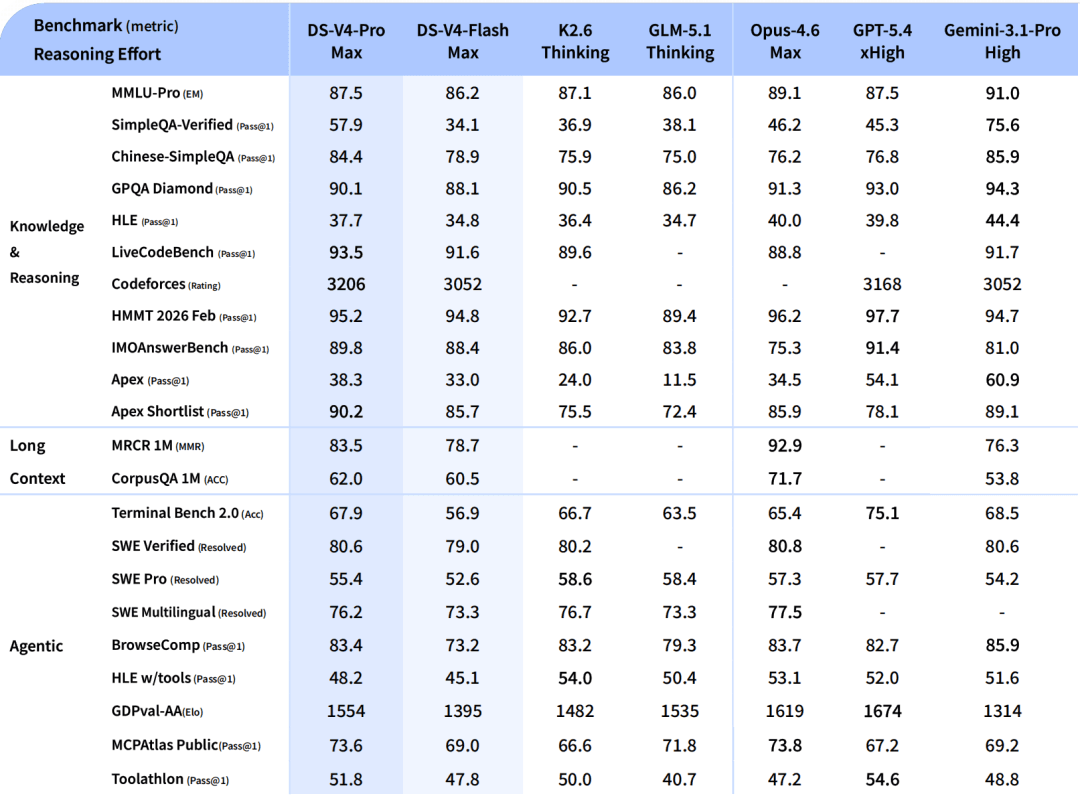
Image Source: DeepSeek-V4 release notes DeepSeek also reveals how they actually use V4: it’s their default internal model for day-to-day agentic coding tasks. They find it more reliable in practice than Claude Sonnet 4.5, with quality close to Claude Opus 4.6 non-thinking mode, though still behind its thinking mode. This highlights a key point: in real-world agent workflows, consistency, latency, and usability often matter more than peak reasoning, with frontier models reserved for the hardest tasks.
-
Adaptive reasoning effort modes. Both models support three inference-time reasoning modes:
- Non-think (fast, intuitive responses for routine tasks)
- Think High (slower but more accurate, deliberate logical reasoning for complex tasks)
- Think Max (maximum reasoning effort, pushing the boundary of model capability).
This lets you tune latency vs. quality per request without model switching.
-
A meaningful leap in world knowledge. One of the most practically significant advances in DeepSeek-V4-Pro is factual knowledge depth. On knowledge benchmarks like SimpleQA-Verified, DeepSeek-V4-Pro-Max outperforms all other open-source models by a margin of around 20 absolute percentage points, only behind Gemini-Pro-3.1. This matters because knowledge retrieval and reasoning are distinct skills. A model can be a strong reasoner and still confidently hallucinate facts.
-
Million-token context with much lower KV-cache pressure. DeepSeek-V4 is designed for long-context intelligence. In 1M-token settings, DeepSeek-V4-Pro only needs 10% of KV cache and 27% of single-token inference FLOPs than DeepSeek-V3.2, which matters for retrieval-heavy workflows, long-document analysis, and extended agentic sessions.
DeepSeek mentions the V4-Pro API throughput is currently constrained by the availability of high-end compute. They expect pricing to drop significantly once Huawei Ascend 950 super nodes ship at scale in the second half of the year. This suggests the model’s real-world cost-performance may improve materially as alternative hardware supply catches up.
Deploy DeepSeek-V4-ProDeploy DeepSeek-V4-Pro
MiMo-V2.5-Pro#
MiMo-V2.5 is the latest open-source model family from Xiaomi for agentic coding, long-horizon reasoning, and multimodal workflows. The lineup provides two MoE variants:
- MiMo-V2.5-Pro (1.02T total, 42B active) is the flagship LLM for coding agents, complex software engineering, and long-horizon tool use. It is trained on 27T tokens using FP8 mixed precision with a native 32K sequence length.
- MiMo-V2.5 (310B total, 15B active) is the native multimodal agent model, supporting text, image, video, and audio inputs. It is trained on ~48T tokens, also in FP8 mixed precision.
The most important architectural update is long-context efficiency. MiMo-V2.5-Pro interleaves sliding-window attention (SWA) and global attention (GA) at a 6:1 ratio with a 128-token window. This cuts KV-cache storage by nearly 7× and still preserves long-context performance.
The post-training stack combines SFT, large-scale agentic RL (across math, safety, tool use, etc.), and Multi-Teacher On-Policy Distillation (MOPD). This leads to more stable behavior across tasks instead of over-optimizing for a single benchmark or domain.
Note: Xiaomi introduced MOPD with MiMo-V2-Flash. Instead of relying only on static fine-tuning data, MiMo learns from multiple domain-specific teacher models through dense, token-level rewards on its own rollouts. This allows the model to efficiently acquire strong reasoning and agentic behavior. For details, check out their technical report.
MiMo-V2.5-Pro is released under the MIT license, supporting commercial use, modification, and fine-tuning.
Why should you use MiMo-V2.5-Pro:
-
Strong open-source coding agent performance. The model matches or surpasses frontier open-weight models like DeepSeek-V4-Pro and Kimi-K2.6 on major coding and agent tasks. Xiaomi also shows examples of sustained tool use across complex workflows such as compiler implementation, desktop app development, and EDA pipelines.
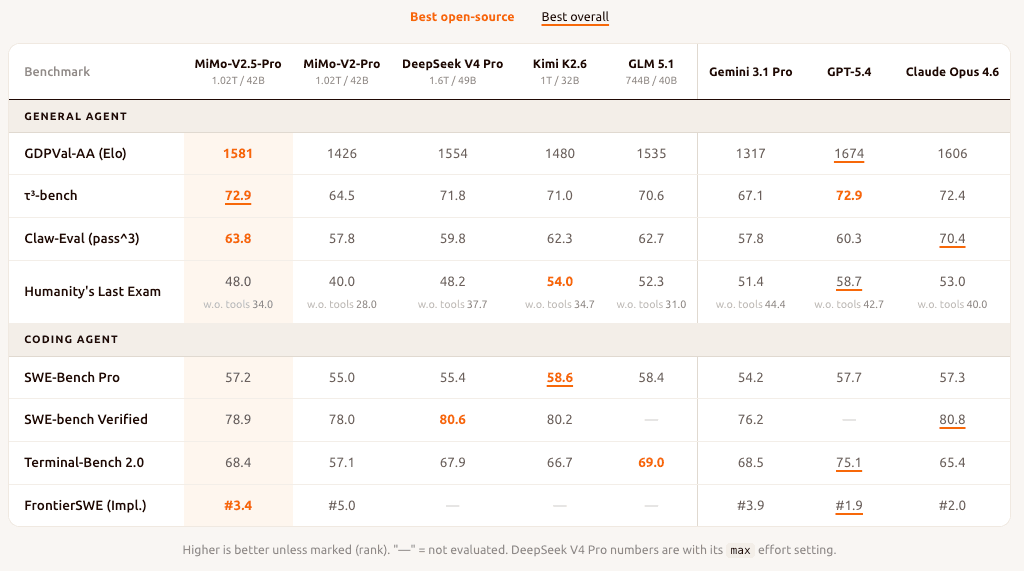
Image Source: MiMo-V2.5-Pro Release Blog -
Token efficiency at scale. On ClawEval, MiMo-V2.5-Pro reaches comparable capability to top proprietary models like Claude Opus 4.6, while using roughly 40–60% fewer tokens per trajectory. For production workloads, this difference compounds quickly across long agentic runs.
-
Long-context reasoning that holds at 1M tokens. The hybrid SWA/GA architecture is purpose-built for long-context tasks. On the GraphWalks benchmark from OpenAI, MiMo-V2.5-Pro maintains strong performance well past 512k tokens. By contrast, the previous V2-Pro collapsed to 0 at that length. This is a meaningful engineering guarantee for repo-scale reasoning, long documents, and persistent agent memory.
Kimi-K2.6#
Kimi-K2.6 is the latest open-weight model from Moonshot AI, positioned as a long-context, agent-oriented LLM for coding. It builds on the base of K2 on practical task execution, with improved stability, tool use, and multi-step coding and planning.
Kimi-K2.6 uses a MoE architecture with ~1T total parameters and 32B active per token. The model combines Multi-head Latent Attention (MLA) for efficient long-context handling with a MoonViT vision encoder (~400M parameters), supporting up to a 256K-token context window.
As a multimodal model, Kimi-K2.6 supports image and video input. Video understanding is still experimental and currently limited to the official API.
Why should you use Kimi-K2.6:
-
State-of-the-art long-horizon coding. Kimi-K2.6 sets a new open-source bar on complex, end-to-end coding, with benchmark results competitive with top closed-source models like GPT-5.4 and Claude Opus 4.6. It generalizes well across languages, including niche ones like Zig, and can sustain long autonomous coding sessions across frontend, backend, DevOps, and performance tuning.
Kimi-K2.6 introduces a
preserve_thinkingmode, which keeps full reasoning traces across turns and improves reliability in agent workflows. For best results, use Kimi-K2.6 with the Kimi Code CLI agent framework, which is purpose-built for the model. -
Agent swarm orchestration at scale. Kimi-K2.6 can dynamically decompose complex tasks into parallel subtasks with up to 300 sub-agents across 4,000 coordinated steps simultaneously. This is a significant expansion from K2.5's 100 sub-agents and 1,500 steps. A single swarm run can deliver complete end-to-end outputs, such as documents, websites, slides, and spreadsheets.
-
Proactive autonomous agents. For persistent, 24/7 background agents (e.g., OpenClaw, Hermes), the model demonstrates strong reliability. In internal tests, a Kimi-K2.6-backed agent operated autonomously for 5 days managing monitoring, incident response, and system operations without human oversight.
-
Coding-driven UI generation. Kimi-K2.6 can translate simple prompts into polished front-end interfaces with aesthetic layouts, interactive elements, and scroll-triggered animations.
Note that Kimi-K2.6 is released under a modified MIT license. The sole modification: For commercial use with 100M+ monthly active users or $20M+ monthly revenue, you must prominently display “Kimi K2.6” in the product UI.
Deploy Kimi-K2.6Deploy Kimi-K2.6
Qwen3.5-397B-A17B#
Alibaba has been one of the most active contributors to the open-source LLM ecosystem with its Qwen series. Qwen3.5-397B-A17B is the latest flagship model from the family. It combines a large MoE architecture with multimodal reasoning and ultra-long context support, making it one of the most capable open models for agentic and multimodal workloads. Compared with the earlier Qwen3-Max generation, the model delivers 8.6×–19× higher decoding throughput, improving serving efficiency for large-scale deployments.
A major focus of Qwen3.5 is multimodal reasoning. Unlike earlier models that bolt vision onto a text backbone, Qwen3.5 integrates vision and language earlier in the architecture. This enables the model to reason across text, images, video, and documents within a unified framework. It is able to call tools such as code interpreters and image search during multimodal reasoning.
Why should you use Qwen3.5-397B-A17B:
-
State-of-the-art performance. The model shows strong capabilities across instruction following, reasoning, coding, agentic, and multilingual tasks. In many benchmarks, it performs competitively with frontier closed-source models such as GPT-5.2 and Claude 4.5 Opus.
-
Ultra-long context. The model supports a 262K token native context window, extendable up to over 1 million tokens. This makes it a perfect choice for systems like AI agents, RAG, and long-term conversations.
However, running such long sequences can require around 1 TB of GPU memory when accounting for model weights, KV cache, and activation memory. If you encounter OOM errors, consider reducing the context length while keeping at least 128K tokens to preserve reasoning performance (Note: Qwen3.5 models run in thinking mode by default).
-
Global language coverage. Qwen3.5 expands multilingual coverage to over 200 languages and dialects.
The Qwen3.5 family also includes a wide range of models beyond the flagship.
- The medium model series (e.g., Qwen3.5-35B-A3B, Qwen3.5-122B-A10B, and Qwen3.5-27B) focuses on improving capability without simply increasing parameter counts. For example, Qwen3.5-35B-A3B already surpasses Qwen3-235B-A22B-2507, demonstrating how architectural improvements, higher-quality data, and scaled reinforcement learning can outperform much larger models.
- Small models (0.8B, 2B, 4B, and 9B) are designed for resource-constrained environments. These models share the same Qwen3.5 foundation, including multimodal capabilities and improved RL training, and support lightweight deployments such as edge inference, compact agents, and mobile applications.
Deploy Qwen3.5-397B-A17BDeploy Qwen3.5-397B-A17B
Gemma 4#
Gemma 4 is the latest generation in Google’s open-weight Gemma family, built for strong reasoning, coding, and multimodal applications. It brings a unified model design across text, image, and audio, with four variant sizes for different deployment targets (from on-device use to large-scale inference).
The architecture centers on a hybrid attention mechanism that interleaves local sliding window attention (1024-token window) with full global attention, always ending with a global layer. This keeps memory usage manageable for long-context tasks without sacrificing deep contextual awareness. The 31B dense variant supports a 256K-token context window, one of the largest in the dense open-source category at this size.
Gemma 4 is released under the Apache 2.0 license, supporting commercial use, modification, and fine-tuning on proprietary data.
Why should you use Gemma 4:
-
Top-tier reasoning and coding performance. Gemma 4 31B delivers top-tier results among open-weight models of similar size, with strong performance on reasoning-heavy benchmarks (e.g., AIME, GPQA) and coding tasks (e.g., LiveCodeBench, Codeforces). It is competitive with much larger models and fits comfortably on a single 80GB NVIDIA H100 GPU.
Note: For best results in multimodal prompts, place image or audio inputs before the text to improve response quality.
-
Flexible model family for different deployment targets. The Gemma 4 lineup spans multiple sizes and architectures:
- E2B and E4B (2.3B and 4.5B effective parameters) are built for on-device deployments, including phones, laptops, and edge hardware. They uniquely support audio input (ASR and speech translation) in addition to text and images.
- 26B A4B is a MoE model with 25.2B total parameters but only 3.8B active per token, giving you near-4B serving cost with significantly better quality.
- 12B is the mid-sized variant for developers who want strong multimodal and reasoning capabilities on consumer hardware (you can run it locally with just 16GB of VRAM).
- 31B is the flagship dense model with the strongest reasoning and coding performance in the family.
-
Native function calling and agentic support. The model supports structured tool use out of the box, including native system prompt support and multi-turn conversations. This makes it a practical drop-in for agentic pipelines without requiring extra prompt engineering to coax tool calls.
-
Multilingual coverage. Pretrained on over 100+ languages and supporting 30+ languages out of the box, Gemma 4 works well for multilingual applications.
Note that the 31B dense model does not support audio input. If you need audio processing (ASR, speech translation) in a self-hosted setup, choose the other three variants in the series.
Now let’s take a quick look at some of the FAQs around LLMs.
What is the best open-source LLM now?#
If you’re looking for a single name, the truth is: there isn’t one. The “best” open-source LLM always depends on your use case, compute budget, and priorities.
That said, if you really want some names, here are commonly recommended open-source LLMs for different use cases.
- Reasoning: MiniMax-M3
- Coding assistants: Kimi-K2.7-Code
- Agentic workflows: GLM-5.2, MiniMax-M3
- General chat: DeepSeek-V4-Pro
- Story writing & creative tasks: DeepSeek-V4-Pro
- OpenClaw: GLM-5.2, MiniMax-M3
These suggestions are for reference only. Use these as starting points, not canonical answers. The “best” model is the one that fits your product requirements, works within your compute constraints, and can be optimized for your specific tasks.
The open-source LLM space is evolving quickly. New releases often outperform older models within months. In other words, what feels like the best today might be outdated tomorrow.
If you are looking for models that can run in resource-constraint environments, take at look at the top small language models (SLMs).
Instead of chasing the latest winner, it’s better to focus on using a flexible inference platform that makes it easy to switch between frontier open-source models. This way, when a stronger model is released, you can adopt it quickly as needed and apply the inference optimization techniques you need for your workload.
Why should I choose open-source LLMs over proprietary LLMs?#
The decision between open-source and proprietary LLMs depends on your goals, budget, and deployment needs. Open-source LLMs often stand out in the following areas:
- Customization. You can fine-tune open-source LLMs for your own data and workloads. Additionally, you can apply inference optimization techniques such as speculative decoding, prefix caching and prefill-decode disaggregation for your performance targets. Such custom optimizations are not possible with proprietary models.
- Data security. Open-source LLMs can be run locally, or within a private cloud infrastructure, giving users more control over data security. By contrast, proprietary LLMs require you to send data to the provider’s servers, which can raise privacy concerns.
- Cost-effectiveness. While open-source LLMs may require investment in infrastructure, they eliminate recurring API costs. With proper LLM inference optimization, you can often achieve a better price-performance ratio than relying on commercial APIs.
- Community and collaboration. Open-source projects benefit from broad community support. This includes continuous improvements, bug fixes, new features, and shared best practices driven by global contributors.
- No vendor lock-in. Using open-source LLMs means you don’t rely on a single provider’s roadmap, pricing, or availability.
How big is the gap between open-source and proprietary LLMs?#
The gap between open-source and proprietary LLMs has narrowed dramatically, but it is not uniform across all capabilities. In some areas, open-source models are now competitive or even leading. In others, proprietary frontier models still hold a meaningful advantage.
According to Epoch AI, open-weight models now trail the SOTA proprietary models by only about three months on average.
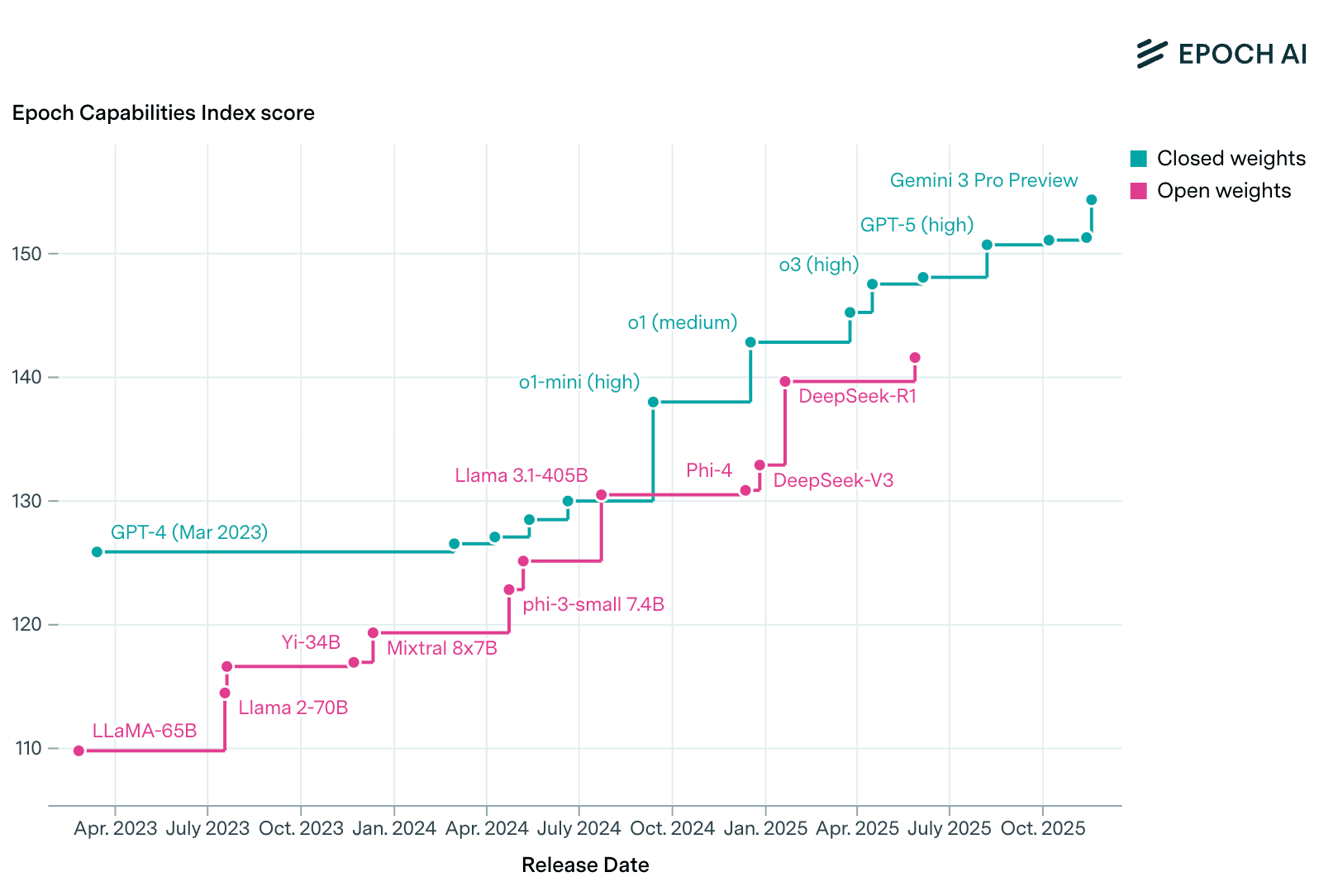
Here is a summary of the current gap:
| Use case | Gap size | Notes |
|---|---|---|
| Coding assistants & agents | Small | Open models like GLM-5.2 or Kimi-K2.6 are already strong |
| Math & reasoning | Small | DeepSeek-V4 reaches Opus-4.6-level performance |
| General chat | Small | Open models increasingly match Opus / GPT-5-level quality |
| Multimodal (image/video) | Moderate–Large | Closed models currently lead in both performance and refinement |
| Extreme long-context + high reliability | Moderate | Proprietary LLMs maintain more stable performance at scale |
How to differentiate my LLM application#
As open-source LLMs close the gap with proprietary ones, you no longer gain an big edge by switching to the latest frontier model. Real differentiation now comes from how well you adapt the model and inference pipeline to your product, focusing on performance, cost, and domain relevance.
One of the most effective ways is to fine-tune a smaller open-source model on your proprietary data. Fine-tuning lets you encode domain expertise, user behavior patterns, and brand voice, which cannot be replicated by generic frontier models. Smaller models are also far cheaper to serve, improving margins without sacrificing quality.
To get meaningful gains:
- Build a high-quality, task-focused dataset based on your actual user interactions
- Identify the workflows where specialization has the biggest impact
- Fine-tune small models that can outperform larger models on your specific tasks
- Optimize inference for latency, throughput, and cost (see the next FAQ for details)
Note that this is something you can’t easily do with proprietary models behind serverless APIs due to data security and privacy concerns.
How can I optimize LLM inference performance?#
One of the biggest benefits of self-hosting open-source LLMs is the flexibility to apply inference optimization for your specific use case. Frameworks like vLLM and SGLang already provide built-in support for inference techniques such as continuous batching and speculative decoding.
But as models get larger and more complex, single-node optimizations are no longer enough. The KV cache grows quickly, GPU memory becomes a bottleneck, and longer-context tasks such as agentic workflows stretch the limits of a single GPU.
That’s why LLM inference is shifting toward distributed architectures. Optimizations like prefix caching, KV cache offloading, data/tensor parallelism, and prefill–decode disaggregation are increasingly necessary. While some frameworks support these features, they often require careful tuning to fit into your existing infrastructure. As new models are released, these optimizations may need to be revisited.
At Bento, we help teams build and scale AI applications with these optimizations in mind. You can bring your preferred inference backend and easily apply the optimization techniques for best price-performance ratios. Leave the infrastructure tuning to us, so you can stay focused on building applications.
What should I consider when deploying LLMs in production?#
Deploying LLMs in production can be a nuanced process. Here are some strategies to consider:
- Model size: Balance accuracy with speed and cost. Smaller models typically deliver faster responses and lower GPU costs, while larger models can provide more nuanced reasoning and higher-quality outputs. Always benchmark against your workload before committing.
- GPUs: LLM workloads depend heavily on GPU memory and bandwidth. For enterprises to self-host LLMs (especially in data centers), NVIDIA A100, H200, B200 or AMD MI300X, MI350X, MI355X are common choices. Similarly, benchmark your model on the hardware you plan to use. Tools like llm-optimizer can quickly help find the best configuration.
- Scalability: Your deployment strategy should support autoscaling up or down based on demand. More importantly, it must happen with fast cold starts or your user experience suffers.
- LLM-specific observability: Apart from traditional monitoring, logging and tracing, also track inference metrics such as Time to First Token (TTFT), Inter-Token Latency (ITL), and token throughput.
- Deployment patterns: How you deploy LLMs shapes everything from latency and scalability to privacy and cost. Each pattern suits different operational needs for enterprises: BYOC, multi-cloud and cross-region, on-prem and hybrid
Final thoughts#
The rapid growth of open-source LLMs has given teams more control than ever over how they build AI applications. They are closing the gap with proprietary ones while offering unmatched flexibility.
At Bento, we help AI teams unlock the full potential of self-hosted LLMs. By combining the best open-source models with tailored inference optimization, you can focus less on infrastructure complexity and more on building AI products that deliver real value.
To learn more about self-hosting LLMs:
- Read our LLM Inference Handbook
- Benchmark and optimize LLM performance with llm-optimizer
- Join our community forum to connect with other builders
- Schedule a call with us to discuss your LLM use case
- Sign up for our inference platform and deploy your first LLM in the cloud