Secure and Private DeepSeek Deployment with BentoML
Authors

Last Updated
Share

The AI world witnessed a seismic shift at the start of 2025 with the emergence of DeepSeek. Its first-generation reasoning model, DeepSeek-R1, matches or even surpasses the performance of leading models like OpenAI-o1 and Claude-3.5 Sonnet across a variety of tasks, including math, coding, and complex reasoning. Even the distilled 32B and 70B models perform on par with models like OpenAI-o1-mini.
However, DeepSeek has also sparked intense discussions about data privacy and security. As organizations weigh their options, many are turning to private deployment as a solution. Fortunately, both DeepSeek V3 and R1 are open-source and licensed for commercial use. This means you can build a fully private, customized ChatGPT-level application within your own secure environment.
At BentoML, we help companies build and scale AI applications securely using any model on any cloud. In this blog post, I’ll explain how BentoML can help you deploy DeepSeek privately. Here’s what you get with our solution:
- A dedicated AI API deployed within your private VPC on any cloud provider (e.g. AWS, GCP, and Azure) or on-premises
- Full control over your model and data assets
- A fast and scalable infrastructure optimized for high-performance AI inference
- Flexibility to choose the best GPU pricing and availability across cloud providers
- Support for custom code and inference backends (e.g. vLLM and SGLang) for all DeepSeek variants
If you have any question, talk to our experts for personalized guidance. Join the conversation in our Slack community to stay updated on the latest insights into DeepSeek private deployment.
Why AI teams are switching to private deployment#
At first glance, the easiest way to build an application with DeepSeek is to simply call its API. While the approach might seem like the quickest path to market with minimal infrastructure overhead, this convenience comes with major trade-offs.
Data privacy concerns#
Calling the DeepSeek API means sending private, business-sensitive data to a third party. This is often not an acceptable option for organizations in regulated industries with compliance and privacy requirements. With a private deployment, you maintain full ownership of your data, ensuring that it stays within your infrastructure and complies with industry regulations and internal security policies.
Limited customization#
Using standard APIs means you’re tied to the same setup as everyone else. There’s no flexibility to customize the inference process for your specific use case, which means no competitive edge. For example, you can’t:
- Adjust latency-throughput trade-offs for your specific use case
- Leverage prefix caching or other advanced optimizations
- Optimize for long context or batching processing
- Enforce structured decoding to ensure outputs follow strict schemas
- Fine-tune the model with your own proprietary data
Unpredictable performance and pricing#
Shared API endpoints come with several operational headaches:
- Rate limits and throttling: If there’s a spike in usage, your requests might be slowed down or even blocked.
- Outages: The API is a black box; when it goes down, your application stops working.
- Price uncertainty: DeepSeek recently adjusted its API pricing due to surging demand for its V3 model. This highlights a major risk of relying on managed AI APIs as your costs can increase overnight without warning.
These problems aren’t exclusive to DeepSeek. They apply to all managed AI API providers, including OpenAI and Anthropic. For details about the trade-offs, see our blog post Serverless vs. Dedicated LLM Deployments: A Cost-Benefit Analysis.
The alternative? Take control by deploying DeepSeek (or any other open-source model) privately on your own infrastructure.
The challenges of deploying DeepSeek privately#
Deploying and maintaining a model like DeepSeek requires substantial engineering effort. Below are the key challenges AI teams face when running DeepSeek in a private environment.
GPU availability and pricing#
DeepSeek models like V3 and R1 are massive, with 671 billion parameters. Running these models requires 8 NVIDIA H200 GPUs with 141GB memory each, which are both scarce and expensive.
The limited availability of these top-tier GPUs makes it difficult to scale efficiently. For example, if you're relying on on-demand GPU instances, you may struggle to secure the capacity you need. And if you pre-provision them to ensure availability, the costs can quickly become prohibitively high.
While you can choose smaller, distilled versions of DeepSeek to reduce hardware requirements, it means potentially compromised performance for certain tasks.
Infrastructure complexity and maintenance costs#
With private deployment, the responsibility for infrastructure shifts to your team. To name a few:
- Cluster management: Setting up and maintaining your own infrastructure.
- Monitoring and observability: Implementing systems to track performance and ensure smooth operation.
- Specialized expertise: Hiring MLOps engineers or other experts to manage and optimize your deployment.
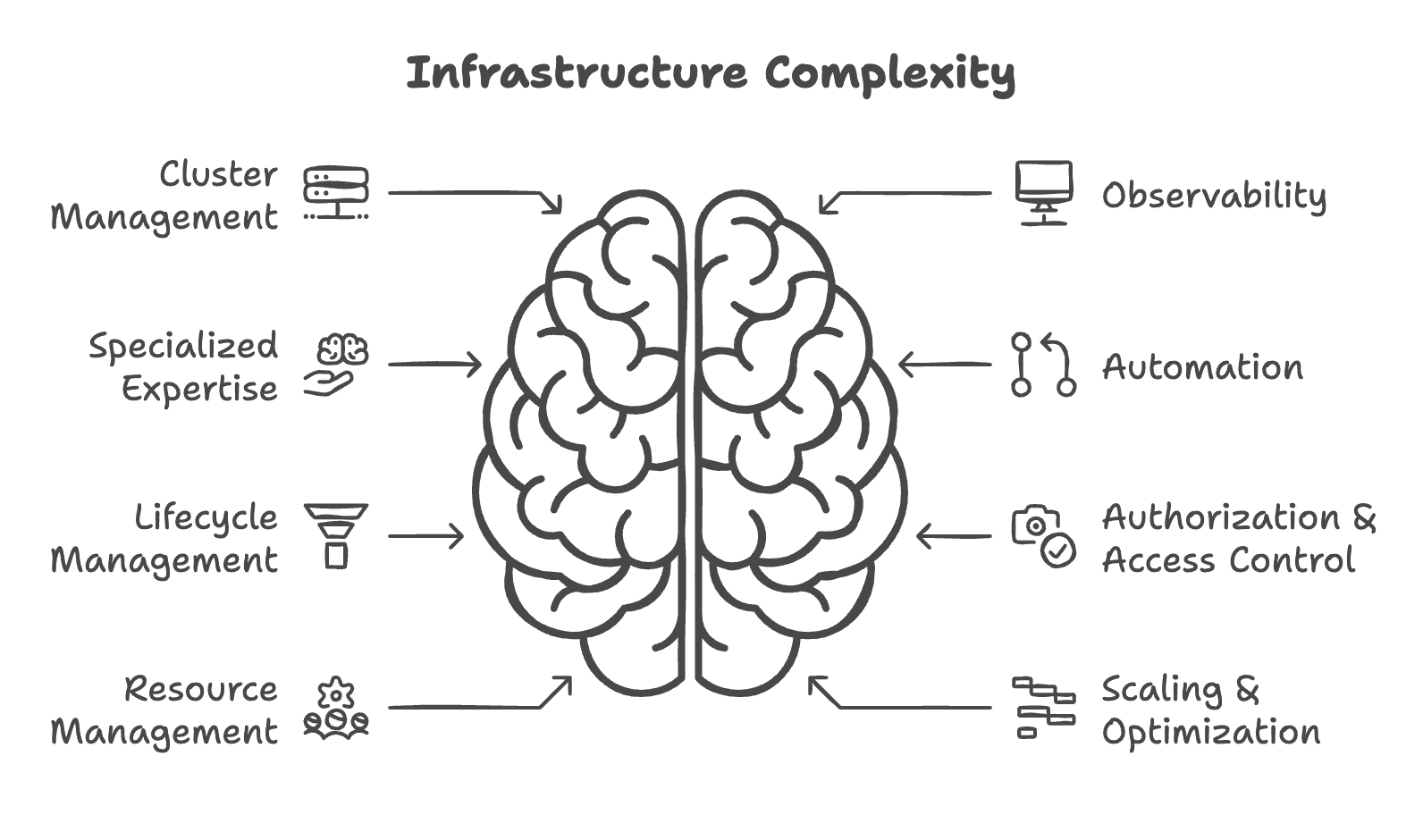
These demands increase the operational overhead, diverting your team’s focus away from core business development and innovation.
Slow cold starts#
Without a highly scalable and optimized infrastructure, startup time can be frustratingly slow. Large models like DeepSeek R1 require significant time to pull container images and load model weights. To avoid performance issues, you may need to over-provision GPU instances. As mentioned above, this will drive up cloud costs, making scaling inefficient and expensive.
How BentoML solves DeepSeek deployment challenges#
At BentoML, we make it easy to deploy private AI applications with any model while ensuring complete data privacy. Let's explore how our solution addresses each of the challenges discussed earlier.
Multi-cloud support#
BentoML lets you choose the most cost-effective and available hardware for your use case. Specifically, you are able to:
- Deploy DeepSeek across all cloud providers (e.g. AWS, GCP, and Azure), GPU cloud providers (e.g. Lambda Labs and CoreWeave), and on-premises infrastructure.
- Access a diverse range of GPUs (e.g. A100, H100, and H200) for different inference needs.
- Optimize GPU spending by selecting the best cloud region and provider based on real-time pricing, performance, and availability.
The flexibility ensures you always get the best performance-to-cost ratio for your AI workloads.
No infrastructure burden with BYOC#
BentoML’s BYOC (Bring Your Own Cloud) option strikes the perfect balance between managed services and security:
- Fully-managed platform with infrastructure burdens offloaded to BentoML
- Secure model and data management within your private VPC
- Access to cutting-edge AI infrastructure innovations
- Focus on core business development rather than infrastructure management
See our blog post BYOC to BentoCloud: Privacy, Flexibility, and Cost Efficiency in One Package to learn more.
Blazing-fast autoscaling with scale-to-zero support#
BentoML accelerates deployment through optimized model downloading and loading strategies. This greatly reduces cold start time and enables rapid scaling and efficient streaming. Additionally, it supports scaling replicas to zero, cutting costs without compromising performance during low-demand periods.
See our blog post Scaling AI Models Like You Mean It to learn more.
Deploy DeepSeek with BentoML#
BentoML makes it simple to deploy DeepSeek securely and privately, supporting all variants, including R1, V3, and distilled versions. You can easily configure inference optimizations, custom backends, and define your own business logic. Explore the BentoVLLM repository for example projects on how to deploy DeepSeek with BentoML and vLLM.
Once your code is ready, you can deploy DeepSeek to BentoCloud, our AI Inference Platform for building and scaling AI applications. After deployment, you’ll have a dedicated, OpenAI-compatible API endpoint that’s entirely under your control.
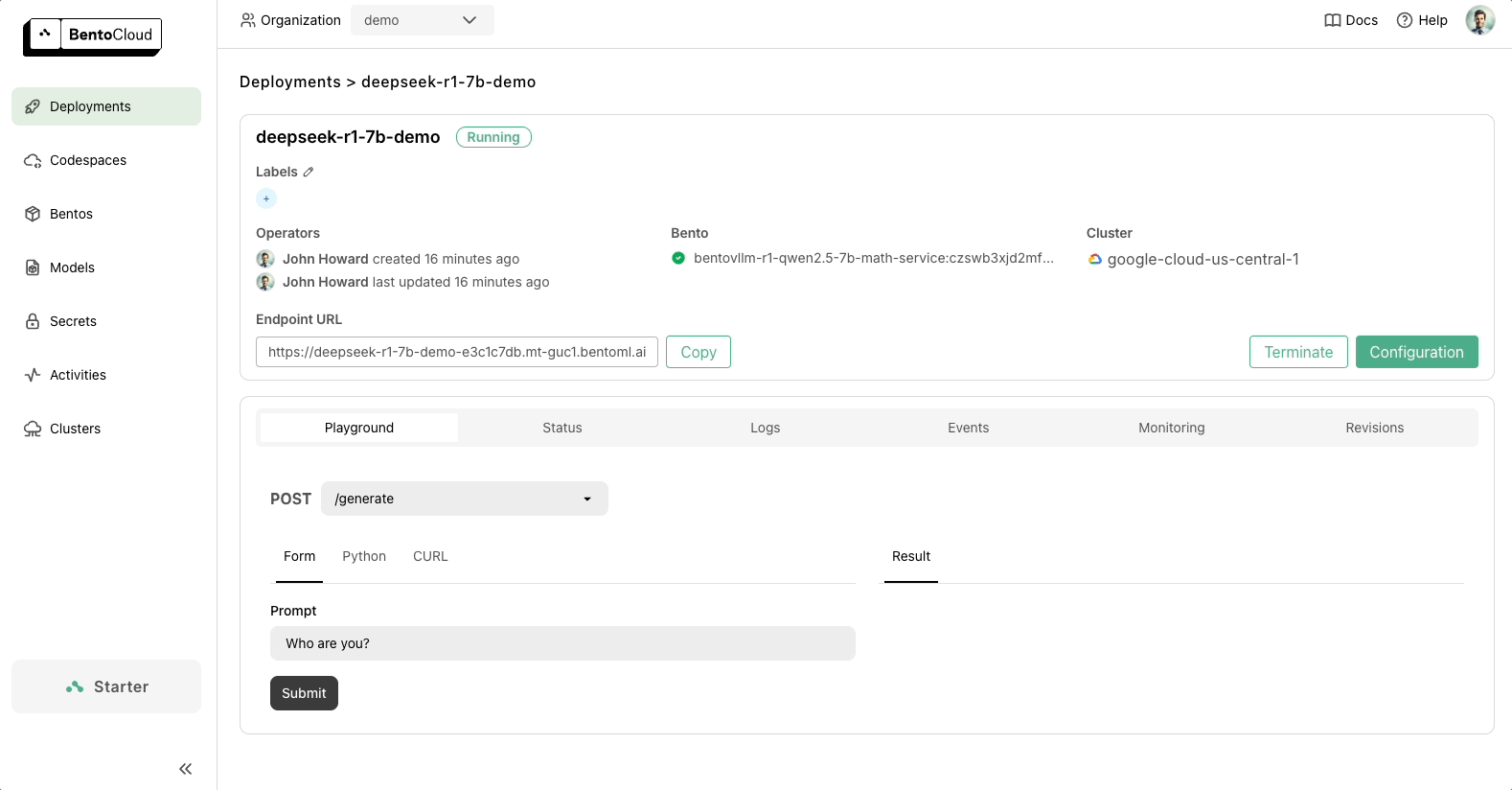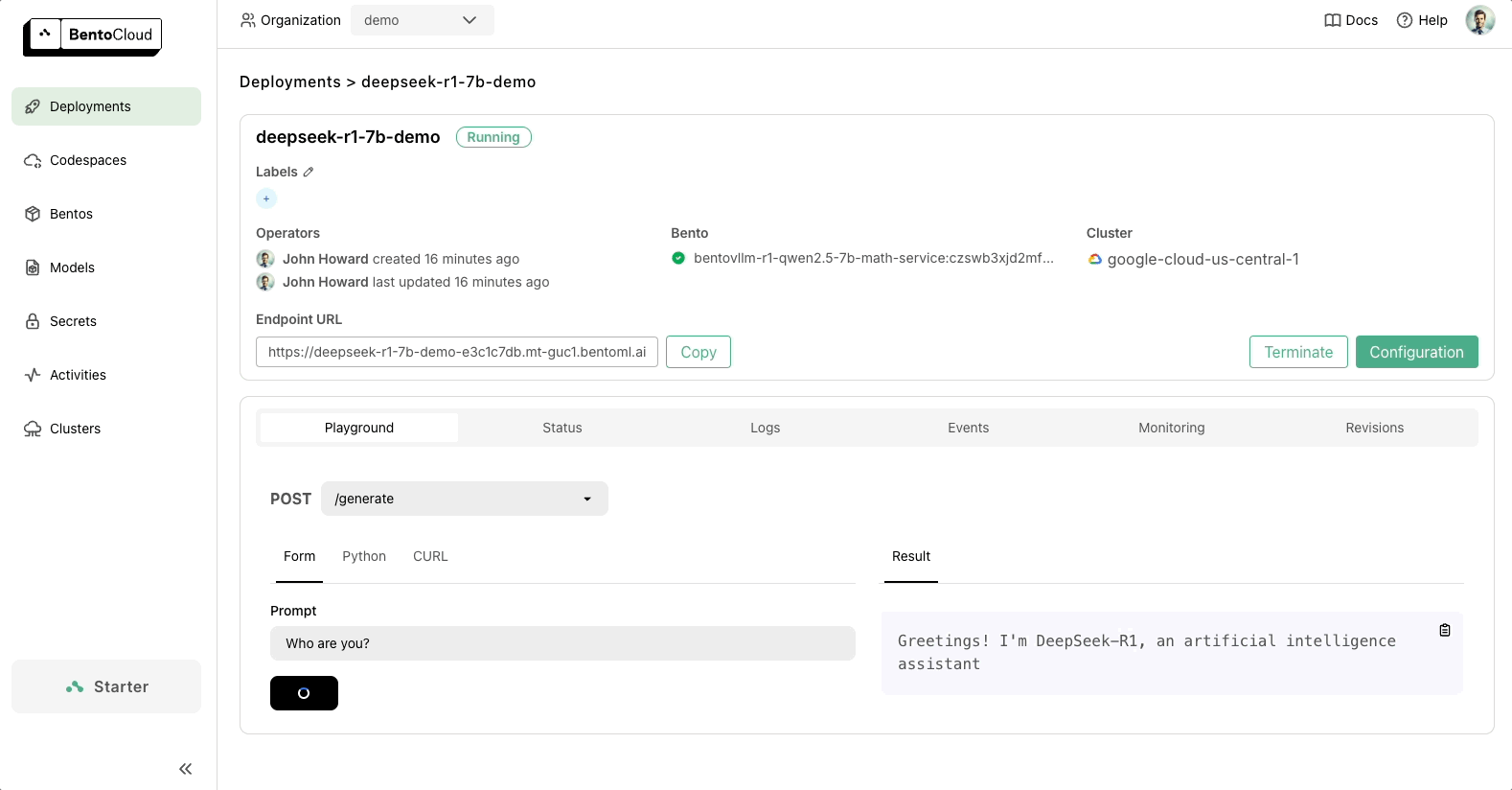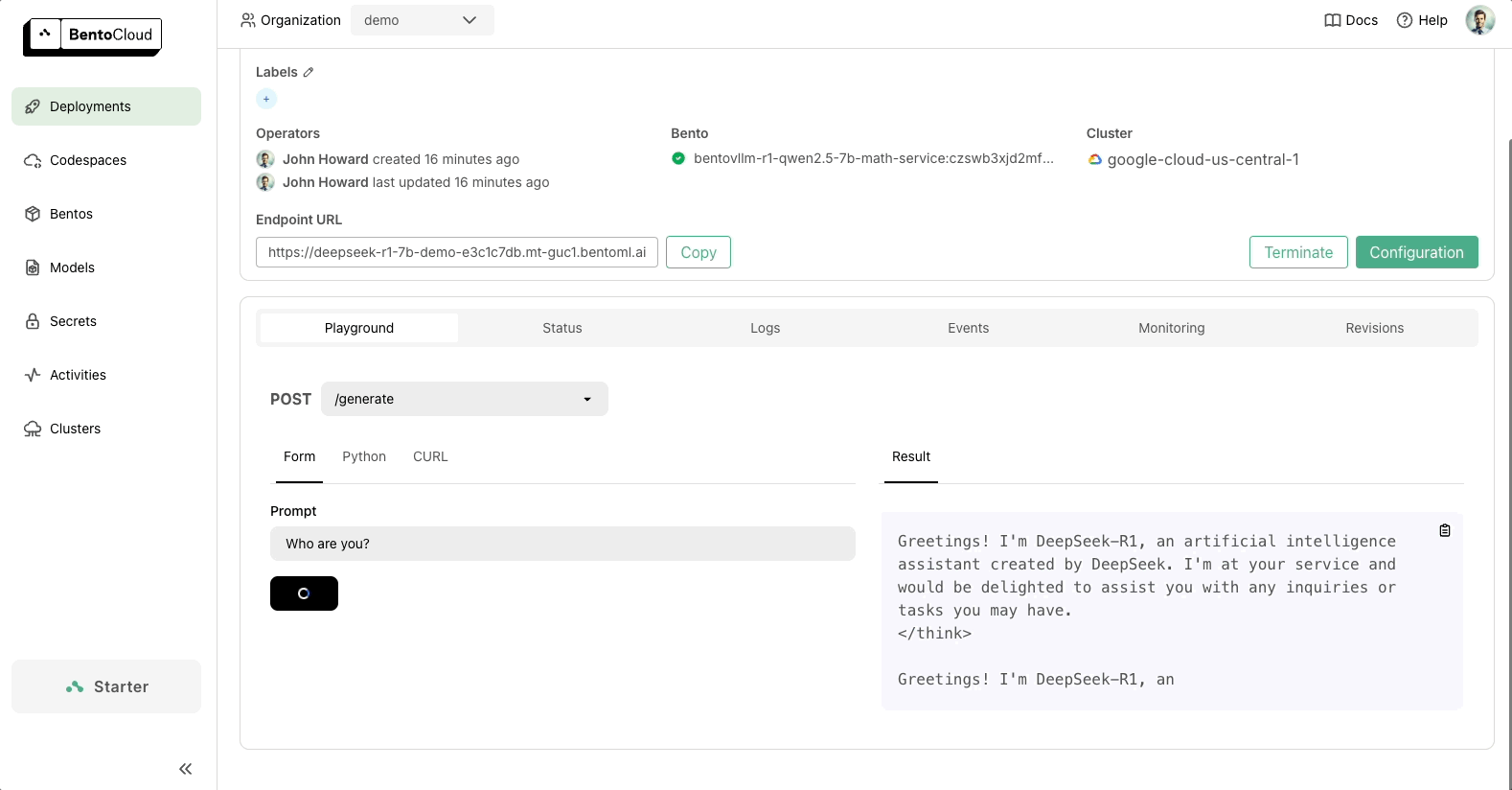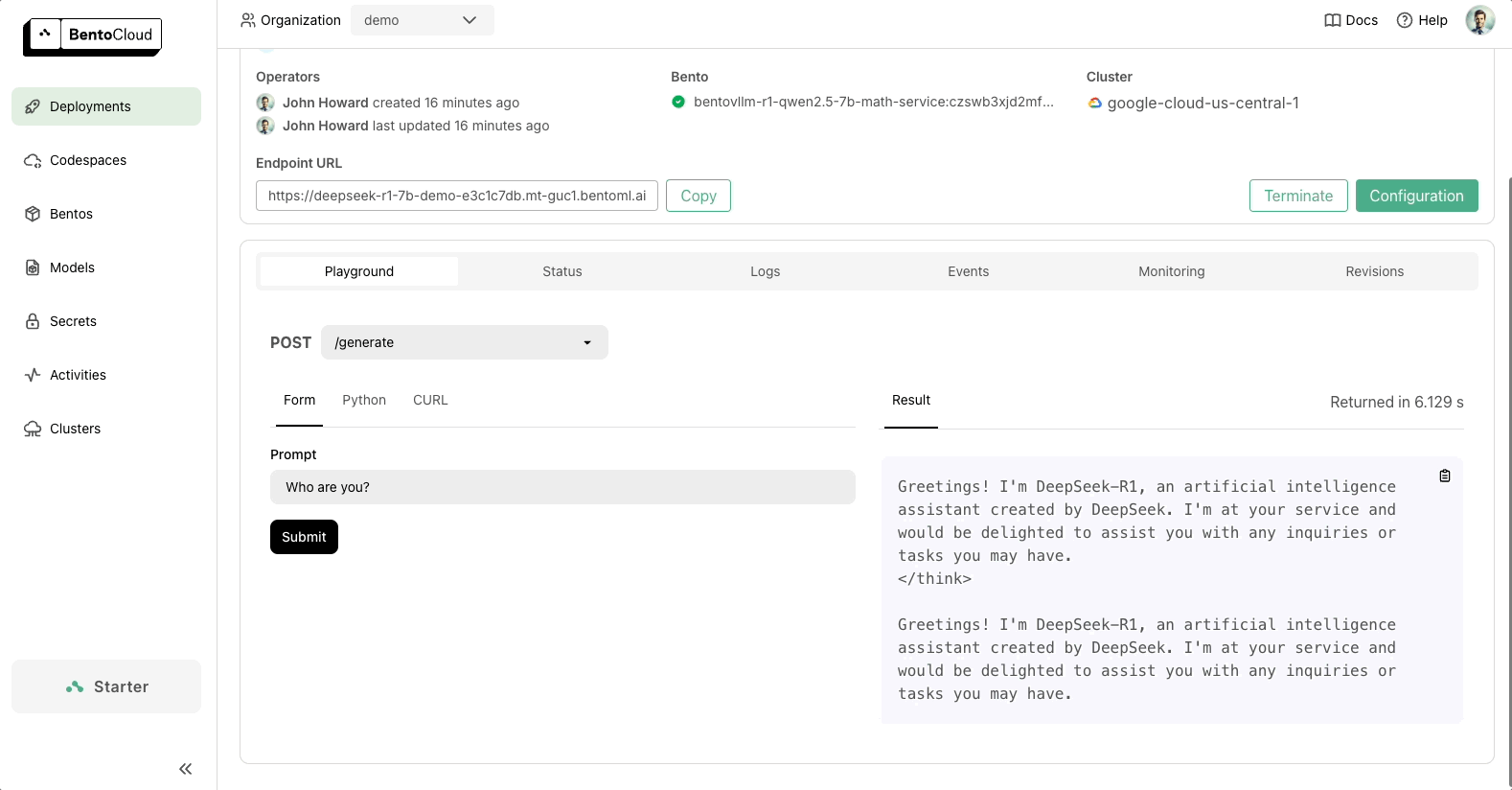
BentoML provides the flexibility to scale with your needs and ensures your AI infrastructure is future-proof. Check out the following resources to learn more:
- [Blog] BentoCloud: Fast and Customizable GenAI Inference in Your Cloud
- [Blog] BYOC to BentoCloud: Privacy, Flexibility, and Cost Efficiency in One Package
- Read our LLM Inference Handbook
- Contact us for expert guidance on secure and private AI deployments
- Join our community forum to stay updated on the latest AI developments
- Sign up for our inference platform and start building today