Serving A LlamaIndex RAG App as REST APIs
Authors

Last Updated
Share

Creating REST APIs for a retrieval-augmented generation (RAG) system provides a flexible and scalable way to integrate RAG with a wide range of applications. In this blog post, we will cover the basics of how to serve a RAG system built with LlamaIndex as REST APIs using BentoML.
This is Part 1 of our blog series on Private RAG Deployment with BentoML. You will progressively build upon an example RAG app and expand to a fully private RAG system with open-source and custom fine-tuned models. Topics to cover in the blog series:
- Part 1: Serving A LlamaIndex RAG App as REST APIs
- Part 2: Self-Hosting LLMs and Embedding Models for RAG
- Part 3: Multi-Model Orchestration for Advanced RAG systems
Concepts#
Before we serve the RAG service, let’s briefly introduce RAG and LlamaIndex.
RAG#
Simply put, RAG is designed to help LLMs provide better answers to queries by equipping them with a customized knowledge base. This allows them to return relevant information even if it hasn't been trained directly on that data. Here’s a brief overview of how a typical RAG system operates:
- The RAG system breaks the input data into manageable chunks.
- An embedding model translates these chunks into vectors.
- These vectors are stored in a database, ready for retrieval.
- Upon receiving a query, the RAG system retrieves the most relevant chunks based on their vector similarities to the query.
- The LLM synthesizes the retrieved information to generate a contextually relevant response.
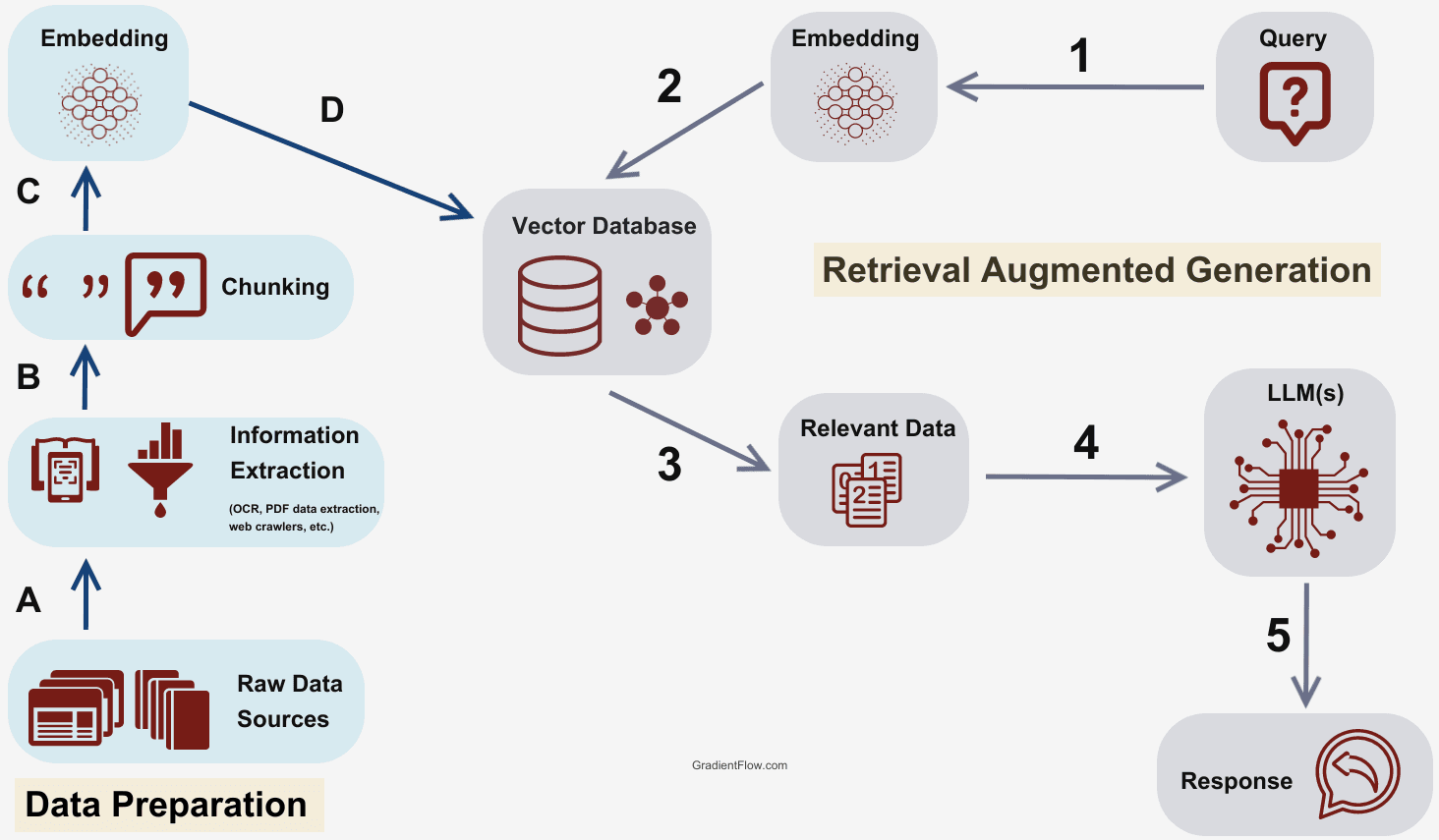
Image source: Techniques, Challenges, and Future of Augmented Language Models
For more information about RAG, you can refer to our previous articles.
- Understanding Retrieval-Augmented Generation: Part 1
- Understanding Retrieval-Augmented Generation: Part 2
- Building RAG with Open-Source and Custom AI Models
LlamaIndex#
LlamaIndex is a Python library that enhances the capabilities of LLMs by integrating custom data sources, such as APIs and documents. It provides efficient data ingestion, indexing, and querying, making it an ideal tool for building compound Python programs like RAG. Therefore, we will use it together with BentoML across this RAG blog series.
What are we building?#
Production use cases often require an API serving system to expose your RAG code. Although web frameworks can help, they become limiting as you start adding model inference components to your server. For more information, see Building RAG with Open-Source and Custom AI Models.
In this blog post, we will be building a REST API service with an /ingest_text endpoint for knowledge ingestion and a /query endpoint for handling user queries. The /ingest_text API lets you submit a text file to populate your RAG system's knowledge base so that you can interact with the /query API to answer questions.
Setting up the environment#
You can find all the source code of this blog series in the bentoml/rag-tutorials repo. Clone the entire project and go to the 01-simple-rag directory.
git clone https://github.com/bentoml/rag-tutorials.git cd rag-tutorials/01-simple-rag
We recommend you create a virtual environment to manage dependencies and avoid conflicts with your local environment:
python -m venv rag-serve source rag-serve/bin/activate
Install all the dependencies.
pip install -r requirement.txt
By default, LlamaIndex use OpenAI's text embedding model and large language model APIs. Set your OpenAI API key as an environment variable to allow your RAG to authenticate with OpenAI's services.
export OPENAI_API_KEY="your_openai_key_here"
Serving a LlamaIndex RAG service#
First, let’s define a class for indexing documents using the LlamaIndex framework:
# Define a directory to persist index data PERSIST_DIR = "./storage" class RAGService: def __init__(self): # Set OpenAI API key from environment variable openai.api_key = os.environ.get("OPENAI_API_KEY") from llama_index.core import Settings # Configure text splitting to parse documents into smaller chunks self.text_splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20) Settings.node_parser = self.text_splitter # Initialize an empty index index = VectorStoreIndex.from_documents([]) # Persist the empty index initially index.storage_context.persist(persist_dir=PERSIST_DIR) # Load index from storage if it exists storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR) self.index = load_index_from_storage(storage_context)
Note: You can find the complete source code here and we will only focus on the core snippets in this article. The code uses local storage for demo purpose and it is not scalable. You will need to integrate a vector database, such as Milvus, Pinecone, or Weaviate, for better performance at scale.
In the above code:
VectorStoreIndexandStorageContextmanage the storage and retrieval of indexed data.SentenceSplitterbreaks down the text into manageable chunks for better indexing and retrieval.
Next, define a function for the RAG system to receive documents, which will be indexed and stored, and another one that responds to user queries by retrieving relevant information from the indexed data.
def ingest_text(self, txt) -> str: # Create a Document object from the text with open(txt) as f: text = f.read() doc = Document(text=text) self.index.insert(doc) # Persist changes to the index self.index.storage_context.persist(persist_dir=PERSIST_DIR) return "Successfully Loaded Document" def query(self, query: str) -> str: query_engine = self.index.as_query_engine() response = query_engine.query(query) return str(response)
To test this class, simply create a RAGService object and call the methods.
# Instantiate the RAGService rag_service = RAGService() # Ingest text from a file ingest_result = rag_service.ingest_text("path/to/your/file.txt") print(ingest_result) # Expected output: "Successfully Loaded Document" # Query for information query_result = rag_service.query("Your query question goes here") print(query_result) # Expected output: Retrieved information based on the query
The code should work well and the next step is to create an API for ingesting knowledge and another one for asking questions. This is where BentoML comes in.
BentoML generates API endpoints based on function names, type hints, and uses them as callback functions to handle incoming API requests and produce responses. To serve this LlamaIndex app as an API server with BentoML, you only need to add a few decorators:
PERSIST_DIR = "./storage" # Mark a class as a BentoML Service via decorator @bentoml.service class RAGService: def __init__(self): ... # Generate a REST API from the callback function @bentoml.api def ingest_text(self, txt: Annotated[Path, bentoml.validators.ContentType("text/plain")]) -> str: ... # Generate a REST API from the callback function @bentoml.api def query(self, query: str) -> str: ...
Note: See the BentoML Services doc to learn more about @bentoml.service and @bentoml.api.
Start this BentoML Service by running:
$ bentoml serve service:RAGService 2024-04-26T08:49:13+0000 [INFO] [cli] Starting production HTTP BentoServer from "service:RAGService" listening on http://localhost:3000 (Press CTRL+C to quit)
The server is now accessible at http://localhost:3000.
Querying the RAG API service#
To begin querying your RAG APIs, create an API client and ingest a file into your RAG system with the ingest_text API:
import bentoml from pathlib import Path with bentoml.SyncHTTPClient("http://localhost:3000") as client: result = client.ingest_text( txt=Path("paul_graham_essay.txt"), )
Now, the text content of paul_graham_essay.txt has been chunked and embedded in your RAG system. Try submitting a query to ask a question about this document:
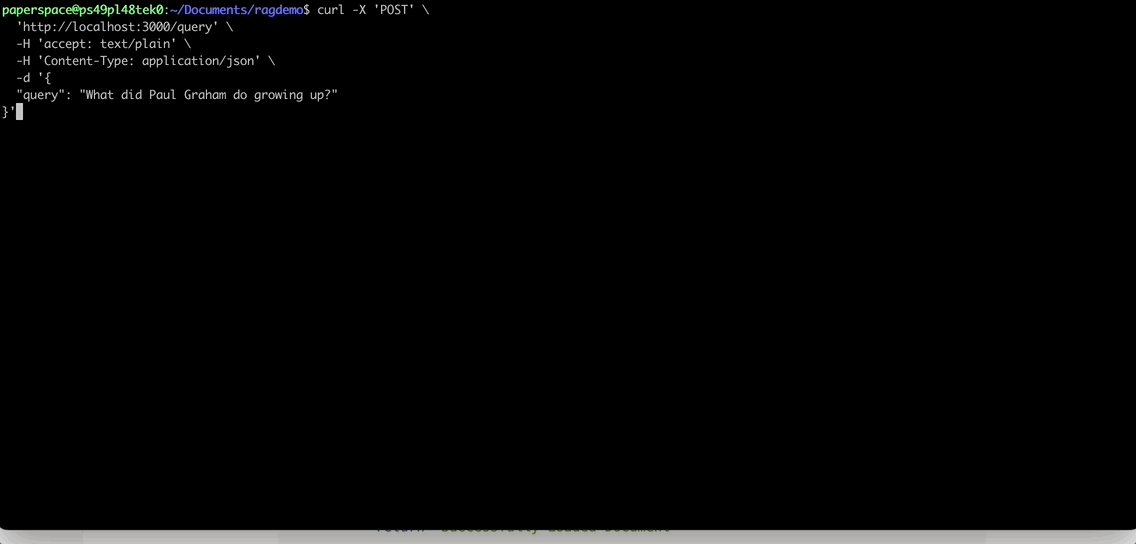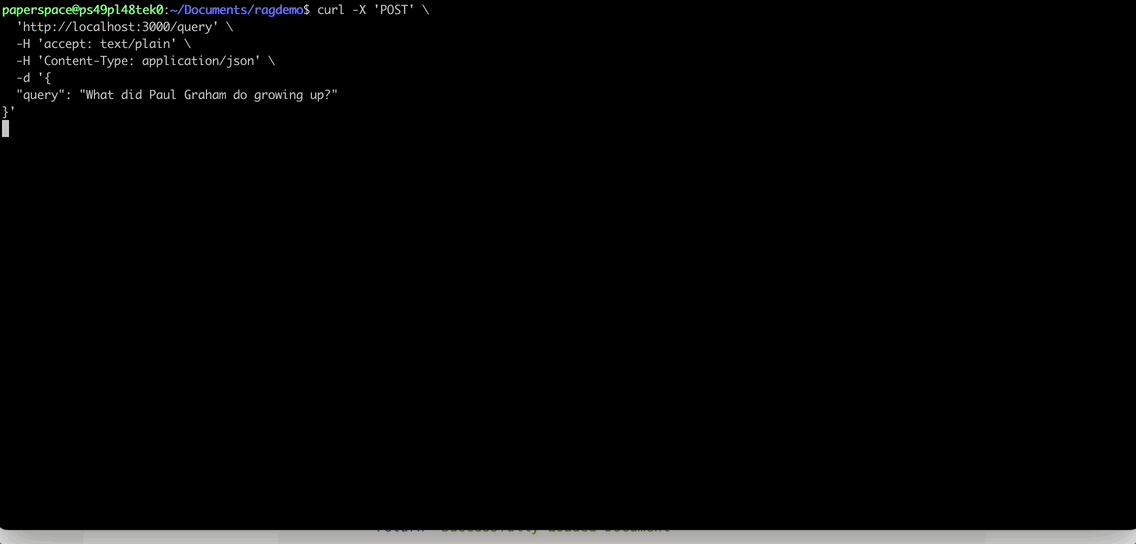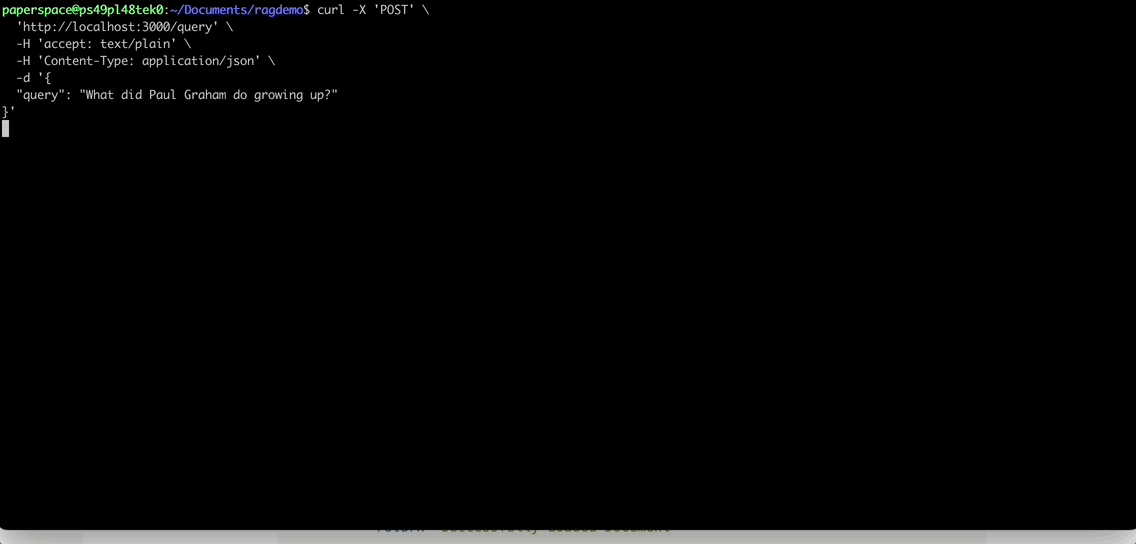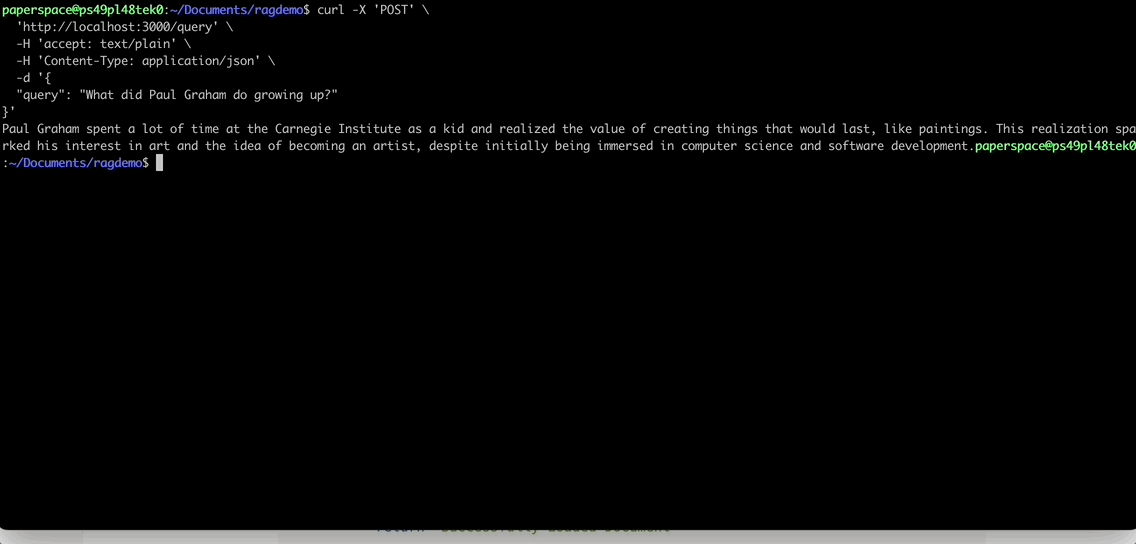
import bentoml with bentoml.SyncHTTPClient("http://localhost:3000") as client: result: str = client.query( query="What did Paul Graham do growing up?", ) print(result)
Example output:
Paul Graham spent a lot of time at the Carnegie Institute as a kid and visited it in 1988. While looking at a painting there, he realized that paintings were something that could last and be made by individuals. This realization sparked his interest in art and the possibility of becoming an artist.
BentoML generates a standard REST API server. You may choose to use any HTTP API client to interact with the endpoint. For example, you can send requests via curl:
Deploying the RAG service for production#
Now, you can deploy this RAG app for production, which means it will be running in a scalable and reliable environment to handle real-world usage and traffic. Before deployment, create a bentofile.yaml file (already in the project directory) to set runtime configurations for your RAG. They will be packaged as a standardized distribution archive in BentoML, or a Bento. All the build options can be found here. Remember to set the OPENAI_API_KEY environment variable.
service: "service.py:RAGService" labels: owner: bentoml-team include: - "*.py" exclude: - "storage/" python: requirements_txt: "./requirement.txt" docker: distro: debian envs: - name: OPENAI_API_KEY value: "sk-*******************" # Add your key here
You can then choose to deploy the LlamaIndex RAG app with Docker or BentoCloud.
Docker#
Use bentoml build to build a Bento.
bentoml build
Make sure Docker is running and then run the following command:
bentoml containerize rag_service:latest
Verify that the Docker image has been created successfully.
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE rag_service 73ikq6ayikzzze5l 0bb88768ea6e 11 seconds ago 917MB
Run the Docker image locally by following the instructions on the printed messages.
$ docker run --rm -p 3000:3000 rag_service:73ikq6ayikzzze5l 2024-05-22T14:05:47+0000 [INFO] [cli] Starting production HTTP BentoServer from "service:RAGService" listening on http://localhost:3000 (Press CTRL+C to quit)
BentoCloud#
Compared with Docker, BentoCloud provides a fully-managed infrastructure optimized for running inference with AI models. This AI inference platform offers more advanced features like autoscaling, GPU inference, built-in observability, and model orchestration, which will be covered in the subsequent blog posts in this series.
Sign up for BentoCloud first, then log in to it via the BentoML CLI.
bentoml cloud login \ --api-token 'your-api-token' \ --endpoint 'your-bentocloud-endpoint-url'
Run bentoml deploy in the project directory (where bentofile.yaml exists) to deploy the LlamaIndex RAG app.
bentoml deploy .
Once it is up and running, use the ingest_text endpoint to inject a text file and then send a query to the query endpoint.
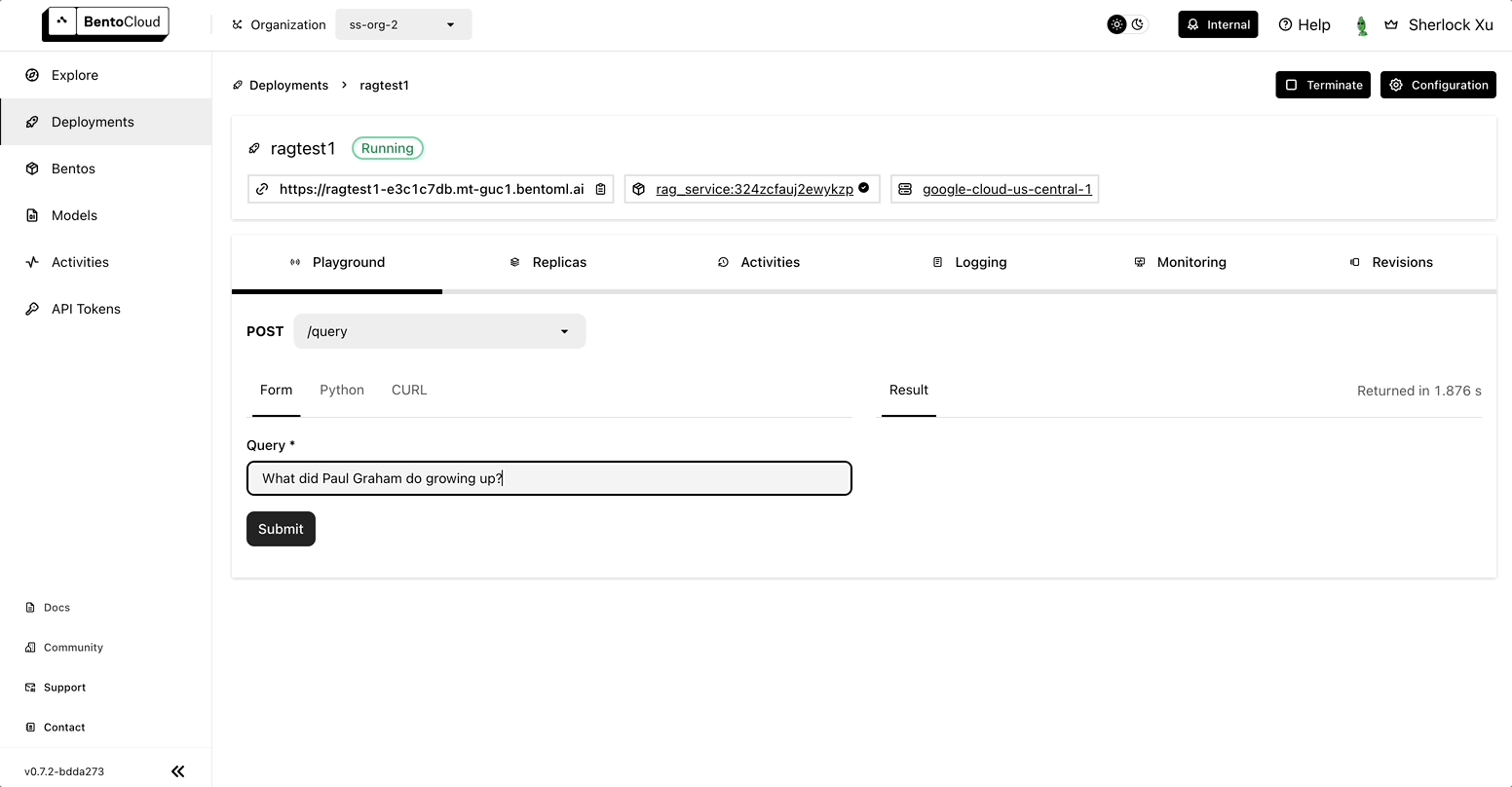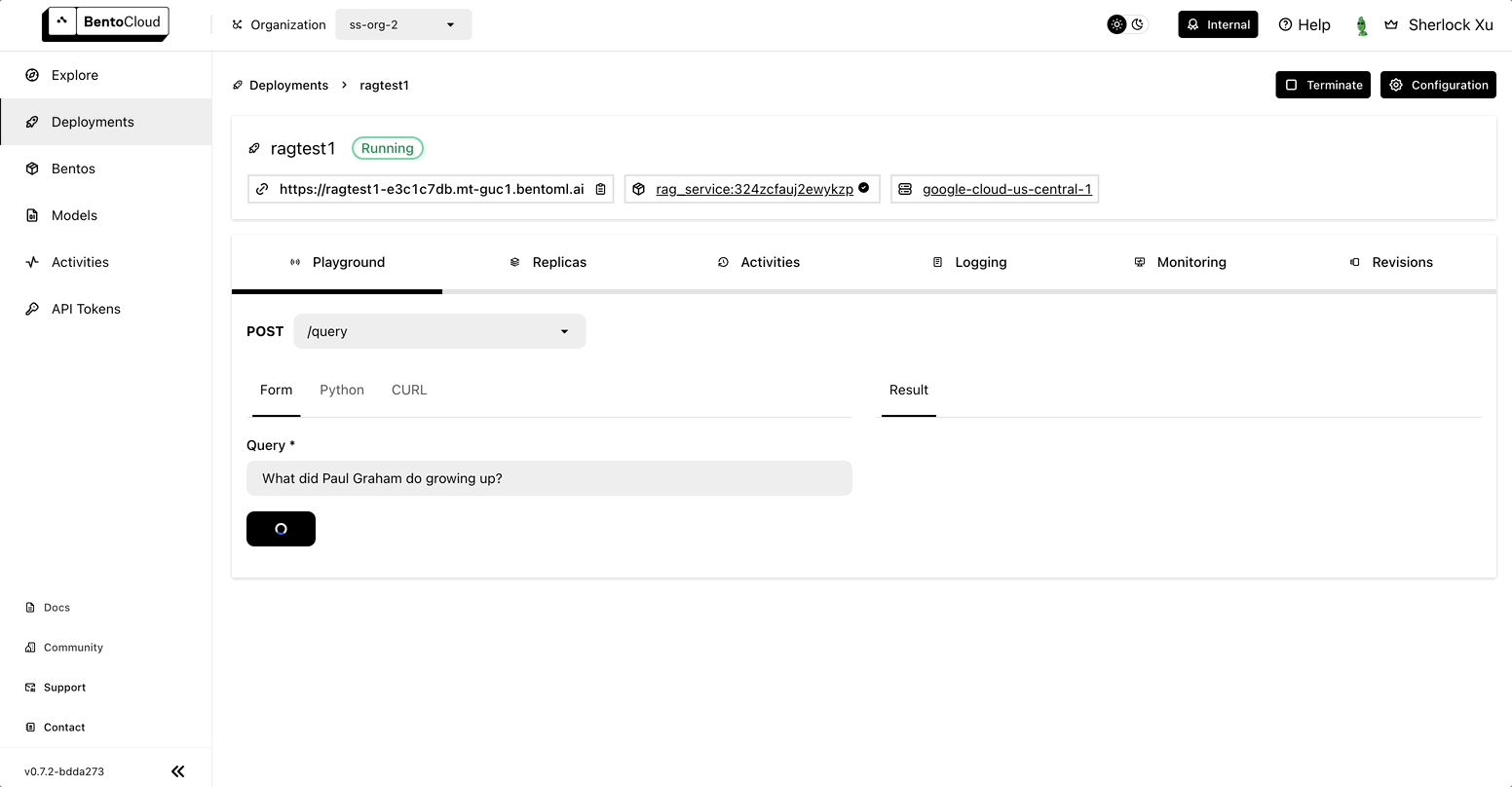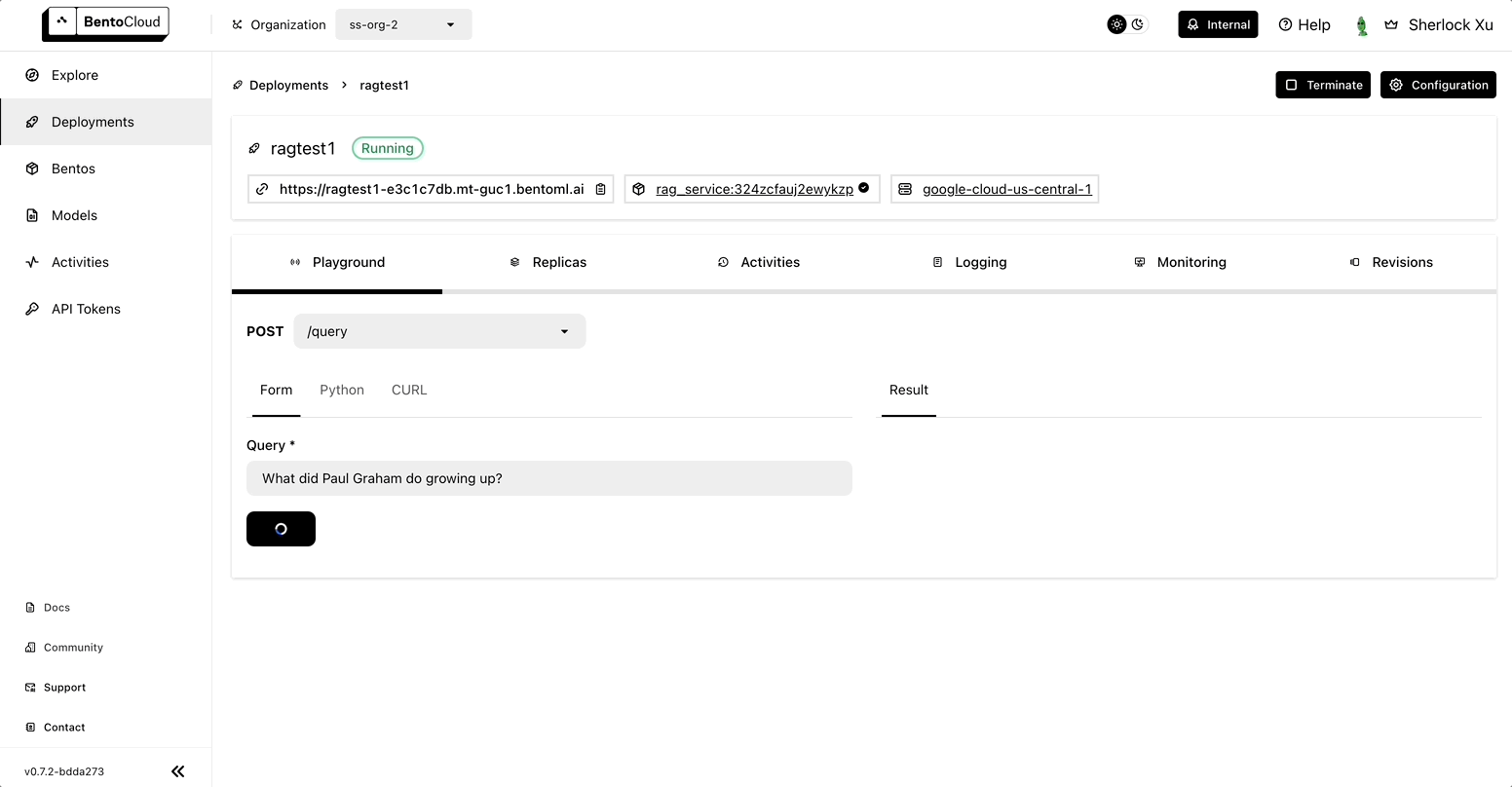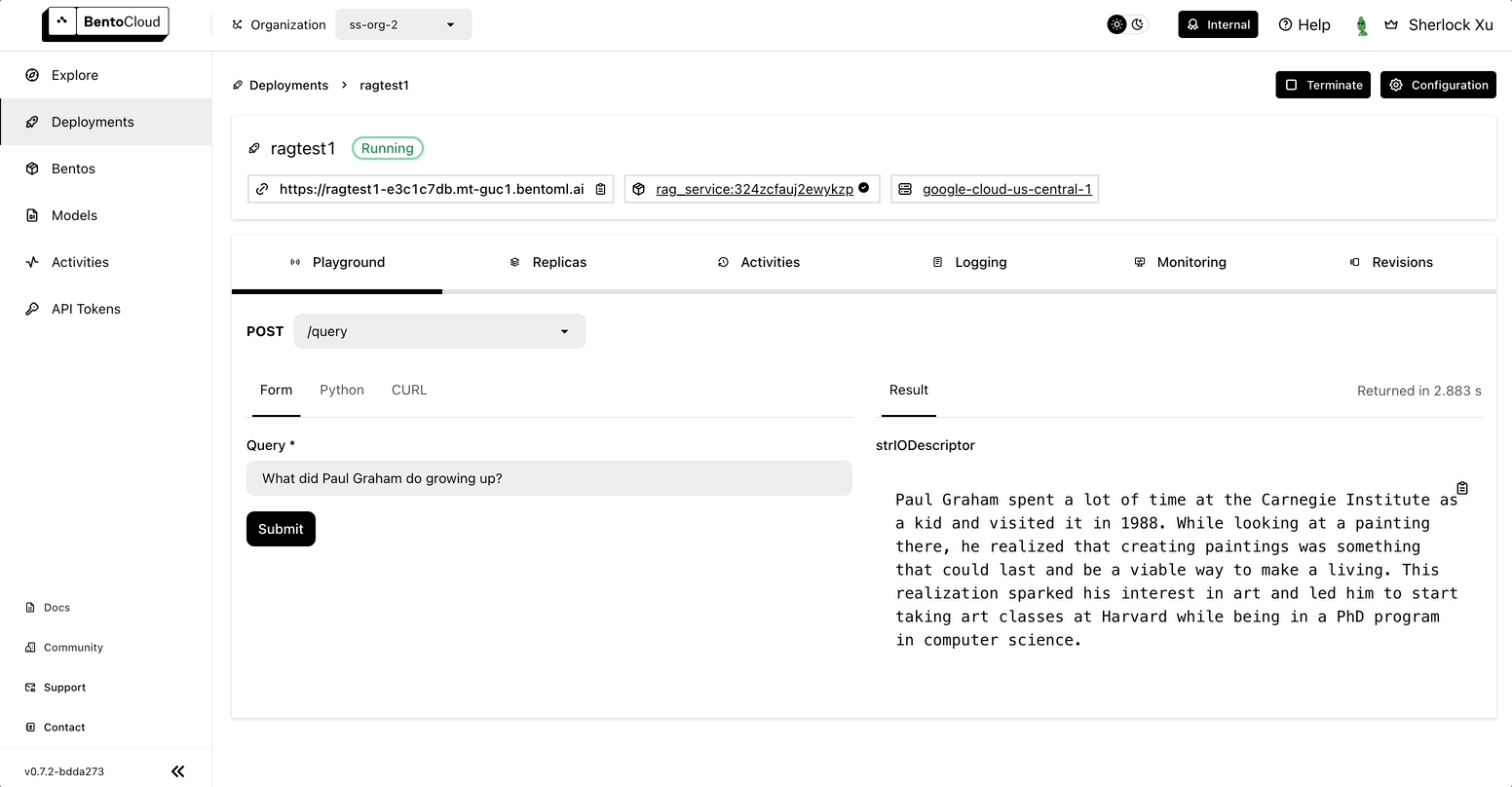
Conclusion#
With BentoML, you can easily serve a LlamaIndex RAG app as a RESTful API server. The entire process only takes two steps: 1) Structure your RAG code into a stateful class; 2) Add type hints and BentoML decorators for generating REST APIs for serving.
With your RAG service as a REST API, you can deploy it with Docker or BentoCloud for production, and integrate other systems, such as web applications, with your RAG code over APIs. Note that this example uses a local file system for storage, which may limit horizontal scalability. For production, we recommend using BentoCloud along with hosted vector database services for enhanced scalability and performance.
While using OpenAI models offers powerful capabilities, some use cases may require more custom solutions to meet specific needs for data privacy and security, cost, latency and reliability. In the next blog post, we will explain how to replace them with open-source embedding and language models to build private RAG.
More on BentoML and LlamaIndex#
Check out the following resources to learn more:
- [Blog] Building RAG with Open-Source and Custom AI Models
- [Blog] Scaling AI Models Like You Mean It
- [Blog] Deploying A Large Language Model with BentoML and vLLM
- [Doc] LlamaIndex Starter Tutorial (OpenAI)
- [Doc] LlamaIndex Indexing
- [Doc] BentoML Services
- Join the BentoML Slack community, where thousands of AI/ML engineers help each other, contribute to the project, and talk about building AI products.
- BentoCloud is a production AI Inference Platform for fast moving AI teams. Sign up now to deploy your first AI model on the cloud and schedule a call with our experts if you have any questions.