Stable Diffusion 3 vs. SDXL vs. Stable Diffusion 2: What’s the Difference
Authors

Last Updated
Share

Stability AI just dropped Stable Diffusion 3 Medium, boasting impressive improvements in image quality, typography, complex prompt understanding and resource efficiency. However, the hype isn't without its caveats. Some argue that SD 3 struggles with human figure generation and performs even worse than its predecessors.
A post from an X user:
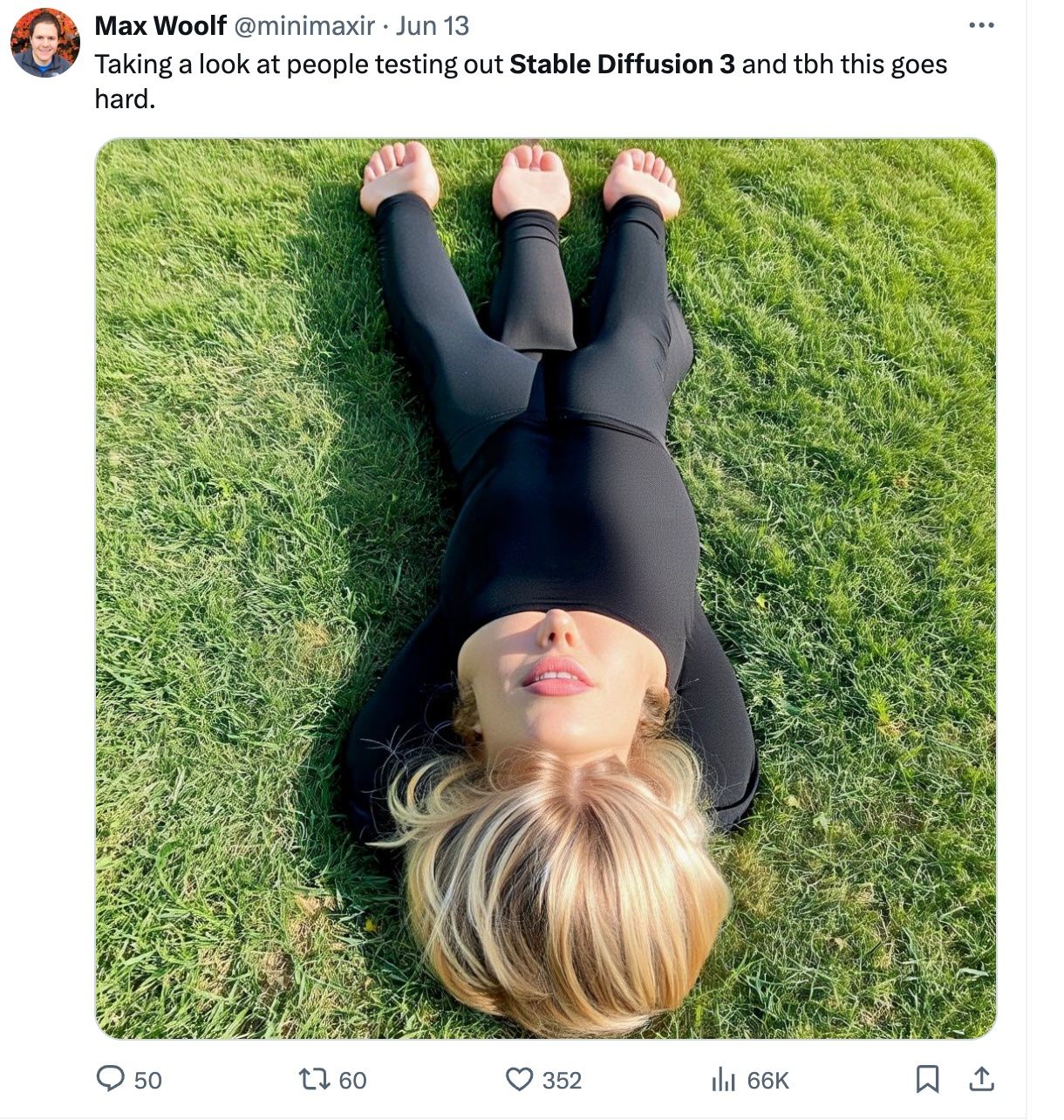
Trying out the upside-down challenge with SD 3 seems to really flip your perspective, which raises more questions for creative workers leveraging the AI model:
- Is SD 3 really the image generation champion, or just another ordinary contender?
- Should you stick with your SD 2, or is it time to change?
- More importantly, as the current landscape is brimming with diffusion models, which model aligns best with your specific artistic vision and requirements?
In this blog post, we will explore these questions hands-on by comparing the performance of SD 3 with its predecessors SD 2 and SDXL in terms of text rendering and human figure generation. In addition, we will try possible solutions for improving the results of SD 3.
Comparing SD 2, SDXL, and SD 3#
To ensure a fair comparison, we tested all three models using the same prompt. Each model had three attempts to minimize the impact of random variations in the generation process.
Round 1: Text rendering#
Text rendering has historically been a stumbling block for image generation models. Words often appear blurry, distorted, or misspelled. If SD 3 could generate more meaningful typography, it would provide more possibilities for creative workers.
We used the following prompt from the Stable Diffusion 3: Research Paper to create a pixel art with text.
Prompt: Beautiful pixel art of a wizard with hovering text “Achievement unlocked: Diffusion models can spell now”
SD 2#
The creations of SD 2 lacked a clear wizard figure, let alone readable text.

Average image generation time: 12.02s
SDXL#
SDXL showed a significant leap in terms of visuals, but it struggled to generate meaningful typography as shown below.

Average image generation time: 21.21s
SD 3#
SD 3 produced the most compelling pixel art with clear text, though with a minor hiccup in individual word spelling.

Average image generation time: 16.86s
Round 2: Human figures#
As we mentioned earlier, the AI art community challenges SD 3’s ability to generate quality human figure images. To put these models to the test, we threw a common prompt to find out if the similar issue exists.
Prompt: A young woman lying on grass, brown hair, high resolution
SD 2#
The faces and hands in its creations appeared distorted and unnatural.

Average image generation time: 11.13s
SDXL#
SDXL displayed better realism in all three attempts; however, the eyes seemed to have some issues.

Average image generation time: 21.77s
SD 3#
While SD 3 delivered decent faces, the hands and arms looked unnatural and deformed.

Average image generation time: 16.84s
Improving the results#
Our initial tests revealed that while SD 3 shined in text rendering, its human figure generation seemed to lag behind SDXL. To figure out how we can improve the results, we experimented with various prompts.
Setting negative prompts#
Negative prompts are used to specify what should not appear in the generated image.
Prompt: A young woman lying on grass, brown hair, high resolution
Negative prompt: distorted, disfigured, deformed, ugly
We instructed SD 3 to avoid distortion features. Unfortunately, this didn’t improve the results and even created incomplete human bodies.

Average image generation time: 16.49s
Using longer and detailed descriptions#
This time we provided two more detailed description prompts about the figure and the environment respectively.
Prompt focusing on the figure: A young woman with long brown hair and a light summer dress lying on a grassy field, emphasizing her relaxed posture and peaceful expression. The image captures her in close-up, highlighting details like the flow of her hair, the texture of her dress, and the subtle interplay of light and shadow on her features. This high-resolution image showcases her natural beauty and the tranquility of her demeanor.

Average image generation time: 16.71s
Prompt focusing on the environment: A young woman with long brown hair lying on a grassy field, dressed in a light summer dress. The scene captures a sunny day, with vivid green grass and scattered wildflowers around her. This high-resolution image emphasizes her peaceful expression and the natural beauty of the serene surroundings.

Average image generation time: 16.23s
However, the generated images didn’t have any significant improvements.
Changing the position#
Analyzing the distorted images, we noticed a common place – the lying down position seemed to cause the problem. It is possible that SD 3 might have a smaller training dataset for figures in this pose.
Prompt: A young woman standing on grass, brown hair, high resolution
With a single word change in the prompt, SD 3 produced more decent and natural results:

Average image generation time: 15.88s
Conclusion#
As SD 3 is a fresh arrival on the scene, definitive conclusions require more exploration. Here are some of our initial findings based on the generated images:
- SD 3 seems to outperform its predecessors in terms of typography and requires lesser generation time than SDXL. However, this may need further test results to justify.
- It is possible that SD 3 has problems with rendering human figures specifically lying down. Avoid prompts with "lying" positions might help create more meaningful images, which suggests potential limitations in SD 3's training data for certain poses.
- Please always remember that the results are heavily impacted by the prompts you provide. If you are a creative worker or AI engineer working with diffusion models, we suggest you experiment with different descriptions to guide SD 3 and feel free to share your findings with us.
All the models in our tests were deployed on BentoCloud, our enterprise platform for running and scaling generative AI model inference. It lets you create custom and dedicated image generation deployment, and expose it to your business application via a scalable API. Here is the BentoCloud console where you can call the SD 3 model inference API directly:
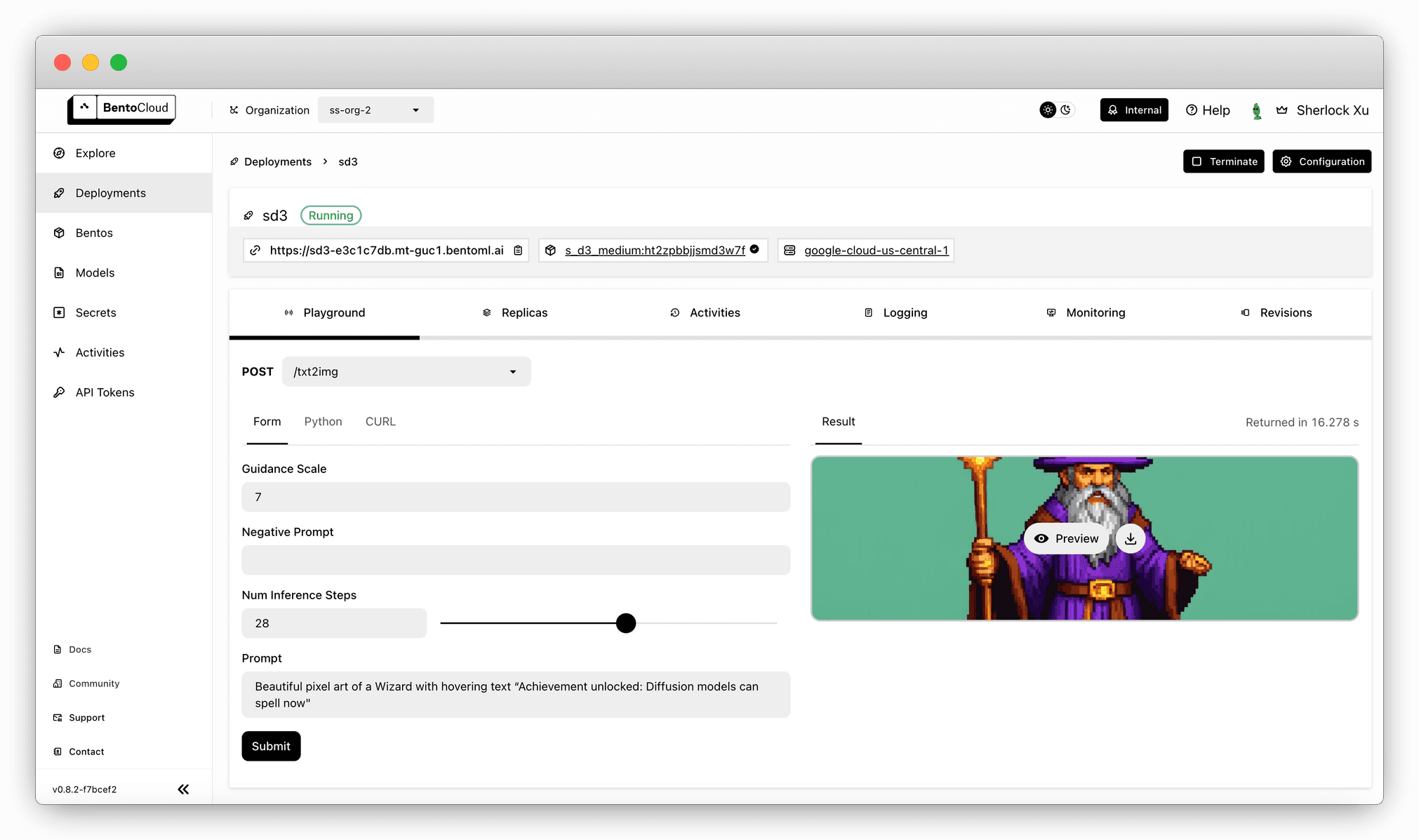
If you are interested, check out the following resources:
- Deploy Stable Diffusion 3 to BentoCloud with a single command
- Try other diffusion models like SDXL, ControlNet, and SVD
- Sign up for BentoCloud
- Join our community forum
- Contact us if you have any questions about deploying AI models