The Complete Guide to DeepSeek Models: V3, R1, V4 and Beyond
Authors

Last Updated
Share

DeepSeek has emerged as a major player in AI, drawing attention not just for its massive 671B models like V3.1 and R1, but also for its suite of distilled versions. As interest in these models grows, so does the confusion about their differences, capabilities, and ideal use cases.
- “Which DeepSeek model should I use?”
- “What’s the difference between R1, V3 and V3.1?”
- “Is R1-Zero better than R1?”
- “Do I really need a distilled model?”
- “What's new in DeepSeek-V4?”
These questions echo across developer forums, Discord channels, and GitHub discussions. And honestly, the confusion makes sense. DeepSeek’s lineup has expanded rapidly, and without a clear roadmap, it’s easy to get lost in technical jargon and benchmark scores.
In this post, we’ll break down the key differences and help you choose the right model for your needs.
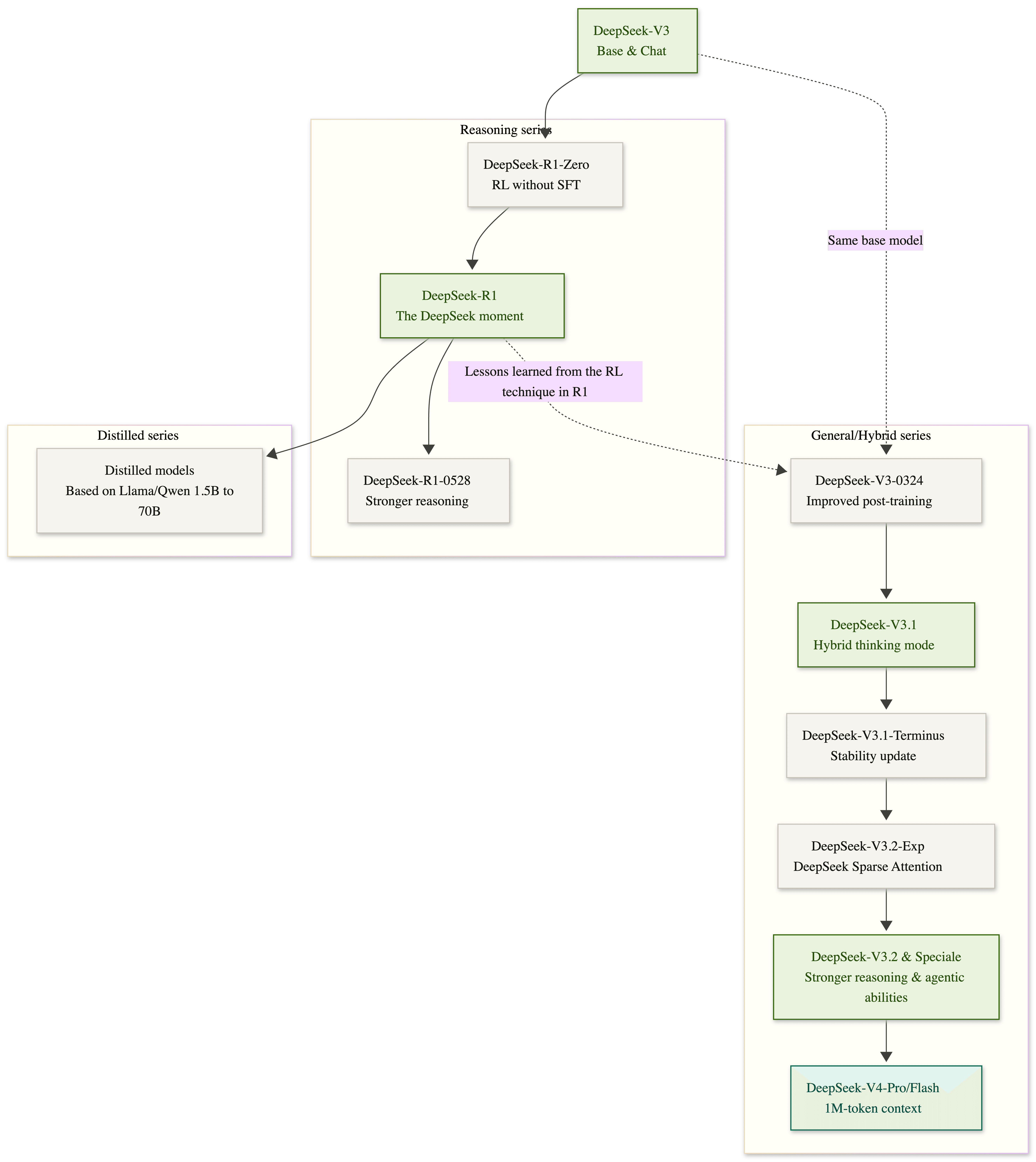
DeepSeek-V3#
Let’s rewind to December 2024 when DeepSeek dropped V3. It's a Mixture-of-Experts (MoE) model with 671 billion parameters and 37 billion activated for each token.
If you’re wondering what Mixture-of-Experts means, it’s actually a cool concept. Essentially, it means the model can activate different parts of itself depending on the task at hand. Instead of using the entire model all the time, it “picks” the right experts for the job. This makes it not just powerful but efficient.
What's perhaps most remarkable about DeepSeek-V3 is the training efficiency. Despite its size, the model required only 2.788 million H800 GPU hours, which translates to around $5.6 million in training costs. To put that in perspective, training GPT-4 is estimated to cost between $50–100 million.
DeepSeek-V3 Base vs. Chat model#
DeepSeek-V3 comes in two versions: a Base and a Chat model.
- The Base model is exactly what it sounds like - the foundation. During its pre-training phase, it essentially learns to predict what comes next in massive amounts of text. After creating this Base model, DeepSeek researchers took it through two different post-training regimes to create models with different capabilities (which leads to two other models: DeepSeek-V3 Chat model and R1).
- The Chat model (aka DeepSeek-V3, and yes, the naming can be confusing) underwent additional instruction tuning and reinforcement learning from human feedback (RLHF) to make it more helpful, harmless, and honest in conversation. It is highly performant in tasks like coding and math, and even compares favorably to the likes of GPT-4o and Llama 3.1 405B.
For DeepSeek-V3-Base, researchers relied exclusively on plain web pages and e-books for training, without deliberately adding synthetic data. They did notice, however, that some crawled web pages used OpenAI-model-generated answers, which means the base model may have indirectly absorbed knowledge from other models. More importantly, during the pre-training cooldown phase, no synthetic OpenAI model outputs were intentionally included.
You can check their benchmark performance in the evaluation results and training details in the supplementary information in Nature.
Deploying DeepSeek-V3#
Both DeepSeek-V3 Base and Chat models are open-source and commercially usable. You can self-host them to build your own ChatGPT-level application.
DeepSeek-R1#
DeepSeek didn’t stop with V3. Just weeks later, they introduced two new models built on DeepSeek-V3-Base: DeepSeek-R1-Zero and DeepSeek-R1.
DeepSeek-R1-Zero: Learning without supervision#
DeepSeek-R1-Zero was trained using large-scale reinforcement learning (RL) without the usual step of supervised fine-tuning (SFT). In simple terms, it learned reasoning patterns entirely on its own, refining its abilities through trial and error rather than structured instruction.
While the results were remarkable, there were also trade-offs. R1-Zero occasionally struggled with endless repetition, poor readability, and even language mixing.
DeepSeek-R1: A more refined reasoning model#
To smooth out these rough edges, DeepSeek developed DeepSeek-R1 using a more sophisticated multi-stage training pipeline. This included incorporating thousands of "cold-start" data points to fine-tune the V3-Base model before applying reinforcement learning. The result was R1, a model that not only keeps the reasoning power of R1-Zero but significantly improves accuracy, readability, and coherence.
Unlike V3, which is optimized for general tasks, R1 is a true reasoning model. That means it doesn’t just give you an answer; it explains how it got there. Before responding, R1 generates a step-by-step chain of thought, making it especially useful for:
- Complex mathematical problem-solving
- Coding challenges
- Scientific reasoning
- Multi-step planning for agent workflows
According to the DeepSeek-R1 paper re-published in Nature and its supplementary information, R1’s training cost was the equivalent of just US$294K primarily on NVIDIA H800 chips. This builds on roughly $6 million spent to develop the underlying V3-Base model. R1 is also thought to be the first major LLM to undergo the peer-review process. This marks a rare moment of transparency in large-scale AI research.

Performance-wise, R1 rivals or even surpasses OpenAI o1 (also a reasoning model, but does not fully disclose the thinking tokens as R1) in math, coding, and reasoning benchmarks. This makes it one of the most powerful open-source reasoning model available today.
Deploying DeepSeek-R1#
R1 is the engine behind the DeepSeek chat application, and many developers have begun using it for private deployments.
Deploy DeepSeek-R1Deploy DeepSeek-R1
Keep these tips in mind when using R1:
- Avoid system prompts and make sure all instructions are included directly in the user prompt.
- For math problems, add a directive like
Please reason step by step, and put your final answer within \boxed{}. - Be aware that R1 may sometimes skip its reasoning process (i.e., outputting
<think>\n\n</think>). To encourage thorough reasoning, tell the model to start the response with<think>\nin your prompt.
See more recommendations in the DeepSeek-R1 repository.
Note: Compared with R1, DeepSeek-R1-0528 supports system prompts and you don’t need to use <think> to force reasoning output. See details about DeepSeek-R1-0528 below.
DeepSeek-V3 vs. DeepSeek-R1: Which one should you choose?#
DeepSeek-V3 and DeepSeek-R1 are the go-to models for many engineers today, but they serve different purposes. If you’re unsure which model fits your needs, here’s a quick comparison to help you decide:
| Item | DeepSeek-V3 | DeepSeek-R1 |
|---|---|---|
| Base model | DeepSeek-V3-Base | DeepSeek-V3-Base |
| Type | General-purpose language model | Reasoning model |
| Response style | Direct answers (e.g., "The answer is 42") | Step-by-step reasoning (e.g., "First, calculate X… then Y… so the answer is 42") |
| Parameters | 671B (37B activated) | 671B (37B activated) |
| Architecture | MoE | MoE |
| Context length | 128K | 128K |
| License | MIT & Model License | MIT |
| Best for | Content creation, writing, translation, general Q&A | Complex math, coding, research, logical reasoning, agentic workflows |
Note that DeepSeek continues to actively update its models. Below are the latest versions of V3 and R1:
DeepSeek-V3-0324#
In March 2025, DeepSeek released a powerful new update: DeepSeek-V3-0324. While it uses the same Base model as DeepSeek-V3, the post-training pipeline has been improved, drawing lessons from the RL technique in DeepSeek-R1. This allows the new model to have better reasoning performance, coding skills and tool-use capabilities. In math and coding evaluations, DeepSeek-V3-0324 even outperforms GPT-4.5.
Deploy DeepSeek-V3-0324Deploy DeepSeek-V3-0324
DeepSeek-R1-0528#
In May 2025, DeepSeek released DeepSeek-R1-0528, a significant upgrade to the original R1 model. While built on the same V3 Base model, this version pushes reasoning and inference capabilities further by leveraging more compute and advanced post-training optimizations.
Deploy DeepSeek-R1-0528Deploy DeepSeek-R1-0528
What’s new in DeepSeek-R1-0528:
- Stronger reasoning. R1-0528 shows a significant leap in reasoning quality. The average token usage during reasoning tasks nearly doubled, from 12K to 23K tokens per AIME question. Its overall performance now approaches that of leading models in mathematics, programming, and general logic, including OpenAI o3 and Gemini 2.5 Pro.
- Reduced hallucination rate. Hallucination has been cut by 45–50% in tasks such as rewriting, summarization, and reading comprehension.
- Function calling improvements. R1-0528 shows solid performance on Tau-Bench with scores of 53.5 (Airline) and 63.9 (Retail). Note that tool use is not currently supported with the thinking mode.
- Vibe coding enhancements. In our experiments, R1-0528 generated more coherent and accurate frontend code. However, it’s still unclear how much it actually improved and it needs more experimentation.
Additional updates over the original R1 include:
- System prompt support
- No need to manually insert
<think>to force reasoning behavior.
DeepSeek-V3.1#
In August 2025, DeepSeek released DeepSeek-V3.1, a major update that combines the strengths of V3 and R1 into a single hybrid model. It features a total of 671B parameters (37B activated) and supports context lengths up to 128K.
Key takeaways:
-
Hybrid thinking mode: V3.1 can switch between “thinking” (chain-of-thought reasoning like R1) and “non-thinking” (direct answers like V3) just by changing the chat template. This means one model can cover both general-purpose and reasoning-heavy use cases.
-
Extended training: Built on DeepSeek-V3.1-Base, V3.1 went through a expanded long-context training process (630B tokens for the 32K extension phase and 209B tokens for the 128K phase).
-
Smarter tool calling: Thanks to post-training optimization, V3.1 is much stronger in tool usage and agentic workflows. It outperforms both DeepSeek-V3-0324 and DeepSeek-R1-0528 in code agent and search agent benchmarks.
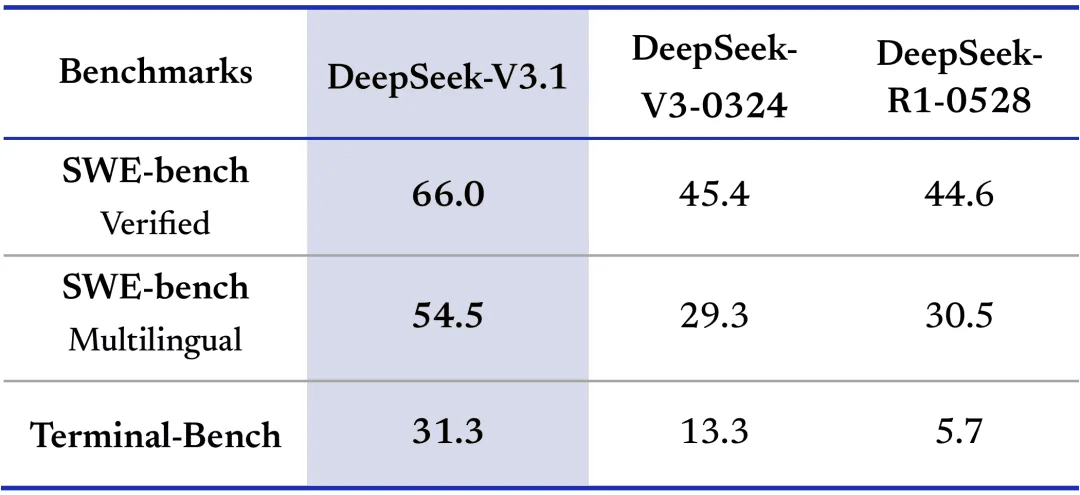
Image Source: DeepSeek-V3.1 release notes -
Faster reasoning: DeepSeek-V3.1-Think achieves quality comparable to DeepSeek-R1-0528, but responds more quickly. Their internal tests show that after chain-of-thought compression training, V3.1-Think reduces output tokens by 20–50% while maintaining almost the same average performance.
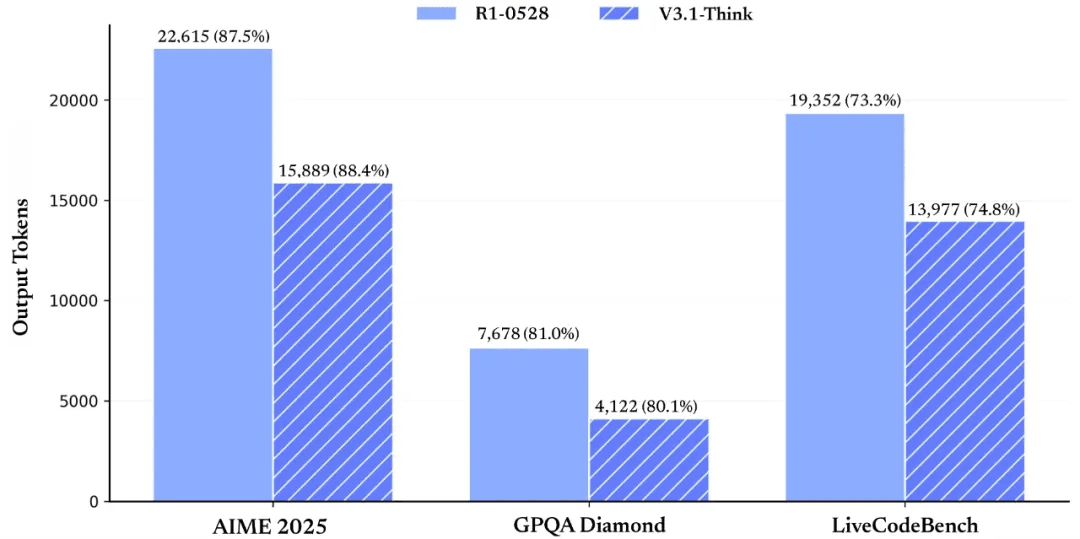
Image Source: DeepSeek-V3.1 release notes
DeepSeek-V3.1 vs. DeepSeek-V3-0324 vs. DeepSeek-R1-0528#
Here is a side-by-side comparison:
| Item | DeepSeek-V3.1 | DeepSeek-V3-0324 | DeepSeek-R1-0528 |
|---|---|---|---|
| Base model | V3.1-Base | V3-Base | V3-Base |
| Parameters | 671B | 660B | 685B |
| Context length | 128K | 128K | 128K |
| Mode | Hybrid: Thinking (CoT) & Non-Thinking (direct) | Non-thinking (general-purpose) | Thinking (CoT reasoning) |
| Tool and agent use | Strongest among the three; best code & search agent results | Good, stronger than original V3 | Improved function calling; search/tool calling not supported under thinking mode |
| Response style | Flexible — fast direct answers or step-by-step reasoning | Direct answers | Detailed reasoning chains with higher token usage |
| Performance highlights | Comparable reasoning to R1-0528 but faster; reduced CoT tokens by 20–50% | Better coding & math than original V3 and GPT-4.5 | Strongest step-by-step reasoning; reduced hallucinations |
| License | MIT | MIT | MIT |
| Best for | Teams needing both speed & reasoning in one model | General-purpose workloads like content creation and Q&A, with stronger reasoning ability for tasks like coding/math | Complex math, coding, and reasoning tasks which require deep step-by-step logic |
In short, DeepSeek-V3.1 is the most versatile DeepSeek model yet. It is capable of acting like V3 when you want fast, direct outputs, or like R1 when you need step-by-step reasoning. If you need both speed and reasoning power in one model, or your workloads have heavy tool usage and agent tasks, DeepSeek-V3.1 is an ideal choice.
Deploy DeepSeek-V3.1Deploy DeepSeek-V3.1
DeepSeek-V3.1-Terminus and DeepSeek-V3.2-Exp#
One month after releasing V3.1, DeepSeek introduced DeepSeek-V3.1-Terminus, a minor update that improves language consistency and agent performance. Overall, this version delivers more stable and reliable outputs across benchmarks compared to V3.1.
And just a week later, DeepSeek open-sourced DeepSeek-V3.2-Exp, which builds on V3.1-Terminus with the introduction of DeepSeek Sparse Attention, a mechanism to optimize training and inference efficiency in long-context scenarios. Across public benchmarks in various domains, V3.2-Exp demonstrates performance on par with V3.1-Terminus.
DeepSeek-V3.2 and DeepSeek-V3.2-Speciale#
Following the incremental upgrades of V3.1 and V3.1-Terminus, DeepSeek introduced two new versions:
- DeepSeek-V3.2: Designed to balance strong reasoning with shorter, more efficient outputs. It is suitable for everyday use, including Q&A and general agent tasks.
- DeepSeek-V3.2-Speciale (high-compute variant): Created to push open-source reasoning to the limit. It’s an enhanced long-thinking version of V3.2, further strengthened with the theorem-proving abilities of DeepSeek-Math-V2.
According to the research paper, DeepSeek acknowledges that open-source models still lag behind the best proprietary models. In complex tasks, closed-source models have been improving faster, widening the performance gap.
They identified three core issues holding open-source models back:
- Inefficient attention. Most open models still rely on dense vanilla attention, making long-context inference slow and costly.
- Insufficient post-training compute. Closed models invest heavily in RL and alignment. Open models typically cannot match that scale.
- Weak agent, instruction-following & tool-use generalization. They reason well on paper, but may break down when interacting with tools or multi-step environments.
How DeepSeek-V3.2 solves these problems:
- DeepSeek Sparse Attention (DSA). A new sparse-attention mechanism (first tested in V3.2-Exp) that dramatically improves long-context efficiency without hurting model performance.
- A scaled RL pipeline. DeepSeek-V3.2 uses a post-training computational budget exceeding 10% of its pre-training compute.
- A massive agent-training ecosystem. DeepSeek built 1,800+ distinct environments and 85,000+ agent tasks, covering search, coding and tool use, to drive the RL process.

DeepSeek-V3.2 achieves GPT-5-High–level performance, narrows the agent-performance gap with closed models, and remains highly cost-efficient.
DeepSeek-V3.2-Speciale pushes the ceiling even higher with relaxed length constraints, reaching Gemini-3.0-Pro–level performance and earning gold-medal results in the 2025 IMO and IOI. However, it is intended for research use only, does not support tool calling, and is not optimized for everyday chat or writing scenarios.
Deploy DeepSeek-V3.2Deploy DeepSeek-V3.2
DeepSeek-V4#
In April 2026, DeepSeek introduced DeepSeek-V4, with a significant architectural leap to make ultra-long context usable in production.
The series includes two MoE models:
- DeepSeek-V4-Pro: 1.6T total parameters, 49B activated per token
- DeepSeek-V4-Flash: 284B total parameters, 13B activated per token
Both models are trained on over 32T tokens and natively support a 1M-token context window.
The biggest architectural shift in DeepSeek-V4 is a new hybrid attention system.
- Compressed Sparse Attention (CSA): Small chunks of tokens are compressed into summary representations, and each new token only attends to the most relevant summaries via top-k selection. This reduces unnecessary computation.
- Heavily Compressed Attention (HCA): Much larger chunks are aggressively collapsed into a single representation, giving the model a cheap global view of the entire context.
These two mechanisms are interleaved across layers, so the model continuously alternates between fine-grained reasoning (CSA) and coarse global awareness (HCA).
The practical result: in a 1M-token context, DeepSeek-V4-Pro uses only 27% of the inference FLOPs and 10% of the KV cache compared to DeepSeek-V3.2. DeepSeek-V4-Flash pushes this even further, reaching 10% of the FLOPs and 7% of the KV cache.
DeepSeek-V4 is one of the first open-weight models that treats long context as a first-class capability rather than a checkbox feature. The architecture is explicitly optimized for long-horizon tasks like codebase understanding, multi-document reasoning, and agent memory.
Three reasoning modes#
One of the most practically useful features of DeepSeek-V4 is adaptive reasoning effort. Both V4-Pro and V4-Flash support three modes:
| Mode | Characteristics | Best for |
|---|---|---|
| Non-think | Fast, direct answers | Routine tasks, everyday Q&A |
| Think High | Step-by-step reasoning | Complex problem-solving, coding, planning |
| Think Max | Maximum reasoning effort | Pushing the frontier of model capability |
Note that the Think Max mode requires a special system prompt prefix. Refer to the Hugging Face model card for the exact format.
World knowledge#
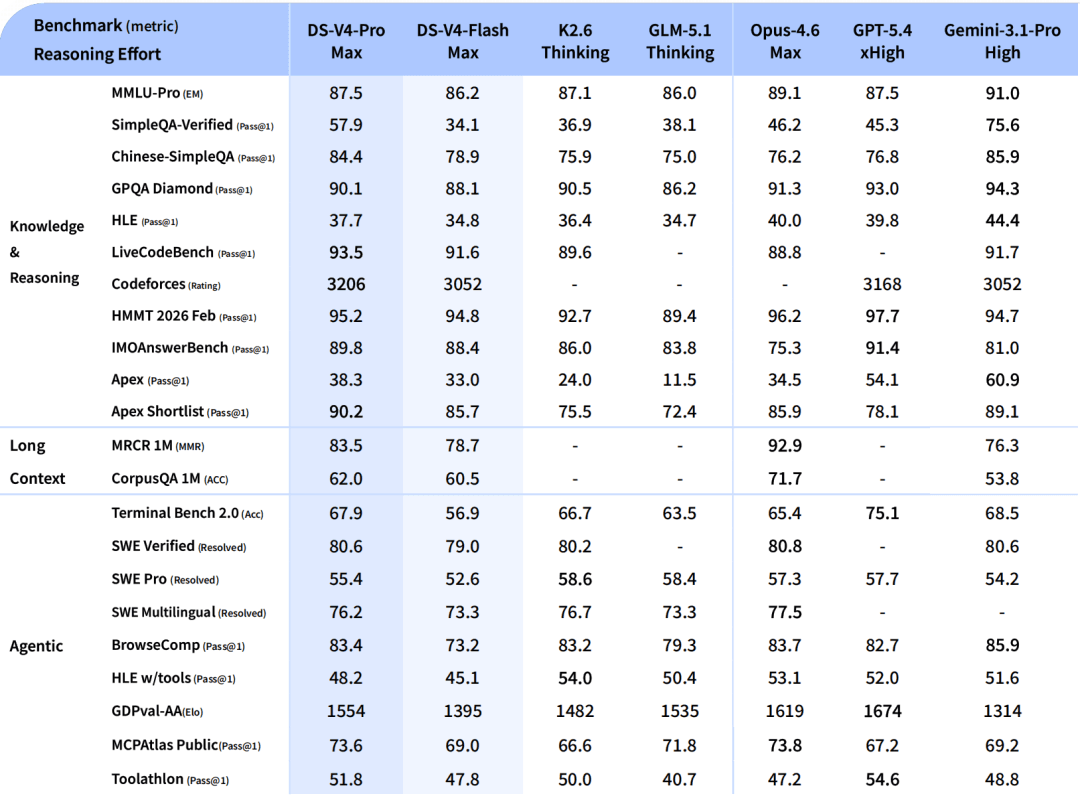
DeepSeek-V4-Pro also makes a notable jump in factual accuracy. On SimpleQA-Verified (a benchmark that tests whether a model actually knows facts, rather than just reasons well), DeepSeek-V4-Pro-Max outperforms all other open-source models by roughly 20 absolute percentage points. This matters because reasoning ability and factual knowledge are distinct. A model can think step-by-step but still hallucinate the underlying facts.
DeepSeek-V4-Pro vs. DeepSeek-V4-Flash#
The table below compares the latest models from the DeepSeek lineup:
| Item | DeepSeek-V4-Pro | DeepSeek-V4-Flash |
|---|---|---|
| Total parameters | 1.6T | 284B |
| Activated per token | 49B | 13B |
| Context length | 1M tokens | 1M tokens |
| Reasoning modes | Non-think / Think High / Think Max | Non-think / Think High / Think Max |
| World knowledge | Significantly stronger | Noticeably weaker at smaller scale |
| Reasoning (Max mode) | Best open-source results across coding, math, agent tasks | Comparable to Pro on reasoning when given larger thinking budget |
| Agent tasks | Stronger, especially on complex multi-step workflows | Matches Pro on some benchmarks; trails on hardest tasks |
| License | MIT | MIT |
| Best for | Highest-capability open-source tasks: research, coding agents, factual Q&A | Cost-efficient inference with strong reasoning; good everyday alternative to Pro |
Distilled DeepSeek models: Bringing reasoning to smaller models#
While V3 and R1 are impressive, running them isn’t practical for everyone. They require 8 NVIDIA H200 GPUs with 141GB of memory each.
That’s where distilled DeepSeek models come in. These smaller, more efficient models bring the reasoning power of R1 to a more accessible scale. Instead of training new models from scratch, DeepSeek took a smart shortcut:
- Started with 6 open-source models from Llama 3.1/3.3 and Qwen 2.5
- Generated 800,000 high-quality reasoning samples using R1
- Fine-tuned the smaller models on these synthetic reasoning data
Unlike R1, these distilled models rely solely on SFT and they do not include an RL stage.
Despite their smaller size, these models perform remarkably well on reasoning tasks, proving that large-scale AI reasoning can be efficiently distilled. DeepSeek has open-sourced all six distilled models, and released their model weights, ranging from 1.5B to 70B parameters.
But before I dive into the individual models, let’s take a quick look at the technique that makes this possible: distillation.
What is distillation#
Distillation is a technique that transfers knowledge from a large, powerful model to a smaller, more efficient one. Instead of training on raw data, the smaller model learns to mimic the larger model’s behavior.
A great analogy comes from the research paper Distilling the Knowledge in a Neural Network by Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. They compare distillation to how insects evolve from larvae to adults:
- The larval stage is optimized for growth, consuming as many nutrients as possible.
- The adult stage is built for efficiency, faster, leaner, and adapted for survival.
Similarly, large AI models are trained with huge datasets and high computational power to extract deep knowledge. But deploying them at scale requires something faster and lighter. That’s where distillation comes in. It compresses the intelligence of a large model into a smaller model, making it more practical for real-world applications.
Distilled models from Llama and Qwen#
Now, let’s take a closer look at each distilled model.
DeepSeek-R1-Distill-Qwen-1.5B#
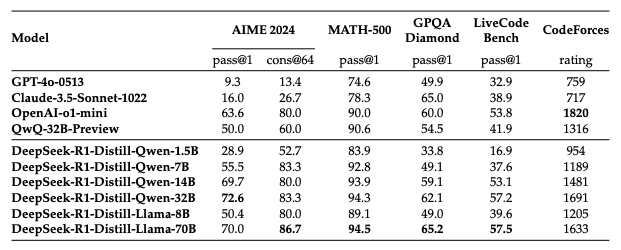
This is the smallest model in the lineup with decent math and reasoning ability. It outperforms GPT-4o and Claude-3.5-Sonnet on AIME and MATH-500, making it a good choice for lightweight problem-solving. However, it struggles with coding tasks, scoring only 16.9 on LiveCodeBench, meaning it's not ideal for programming applications.
DeepSeek-R1-Distill-Qwen-7B#
A step up from the 1.5B model, this version offers stronger performance in mathematical reasoning and general problem-solving. It scores well on AIME (55.5) and MATH-500 (92.8), but still lags behind in coding benchmarks (37.6 on LiveCodeBench).
DeepSeek-R1-Distill-Llama-8B#
Based on the Llama 3.1 architecture, this model shows strong mathematical reasoning. It not only surpasses GPT-4o and Claude-3.5-Sonnet in AIME and MATH-500, but also performs very close to o1-mini and QwQ-32B-Preview in MATH-500. Its coding performance suggests better competitive coding skills, but it's still not on par with larger models.
DeepSeek-R1-Distill-Qwen-14B#
This is a balanced model that offers strong reasoning, math, and general logic capabilities. It’s a great middle ground for those needing better accuracy without high computational costs. While the coding performance is not the best, it’s very close to o1-mini.
DeepSeek-R1-Distill-Qwen-32B#
This is one of the best-performing distilled models. With top-tier reasoning (72.6 on AIME, 94.3 on MATH-500) and a strong CodeForces rating (1691), it's a great option for math-heavy applications, competitive problem-solving, and advanced AI research.
An interesting research insight: DeepSeek used this model to compare distillation and RL for reasoning tasks. They tested whether a smaller model trained through large-scale RL could match the performance of a distilled model.
To explore this, they trained Qwen-32B-Base with math, coding, and STEM data for over 10,000 RL steps, resulting in DeepSeek-R1-Zero-Qwen-32B.

The conclusion is that distilling powerful models into smaller ones works better. In contrast, smaller models using large-scale RL need massive computing power and may still underperform compared to distillation.
DeepSeek-R1-Distill-Llama-70B#
This is the most powerful distilled model, based on Llama-3.3-70B-Instruct (chosen for its better reasoning capability than Llama 3.1). With a 94.5 score on MATH-500, it closely rivals DeepSeek-R1 itself. It also achieves the highest coding score (57.5 on LiveCodeBench) among all distilled models.
Here is a high-level comparison of the six distilled models:
| Model | Base model | Best for | Reasoning strength | Compute cost |
|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | Entry-level reasoning, basic math | 💪💪 | Low |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | Mid-tier math & logic tasks | 💪💪💪 | Medium |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | Mid-tier math & logic tasks, coding assistance | 💪💪💪 | Medium |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | Advanced math & logic tasks, problem-solving, coding assistance | 💪💪💪💪 | Medium-High |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | Complex math, logic, & coding tasks, problem-solving, research | 💪💪💪💪💪 | High |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | Complex math, logic, & coding tasks, problem-solving, research | 💪💪💪💪💪 | High |
Explore our example projects to deploy the 6 distilled models using BentoML and vLLM.
DeepSeek-R1-0528-Qwen3-8B#
When DeepSeek released R1-0528, it also announced DeepSeek-R1-0528-Qwen3-8B. By fine-tuning Qwen3-8B on R1-0528's chain-of-thought outputs, this model delivers strong results. It surpasses both Qwen3-8B and Qwen3-32B on AIME benchmarks, and even Qwen3-235B-A22B on AIME 24.
Specialized models from DeepSeek#
Beyond V3 and R1, DeepSeek has been building domain-focused models to tackle narrower areas.
-
DeepSeek-Prover-V2-671B: An open-source LLM designed for formal theorem proving in Lean 4. It is able to decompose complex theorems into subgoals and produce verified Lean 4 proofs with chain-of-thought clarity. If you’re working in formal mathematics, automated theorem proving, or symbolic reasoning, DeepSeek-Prover-V2 is the model to explore. Note that DeepSeek-Prover-V2 provides two model sizes: 7B and 671B.
Check out the example to deploy DeepSeek-Prover-V2-671B.
-
Janus-Series: A family of unified multimodal models for both understanding and generation:
- Janus: A novel autoregressive framework that decouples visual encoding but keeps a unified transformer backbone. It supports both image understanding (like OCR) and image generation in one model.
- Janus-Pro: A scaled-up and optimized successor with expanded training data and larger model sizes. It improves both multimodal reasoning and instruction-following for text-to-image tasks.
- JanusFlow: Introduces a minimalist architecture that integrates autoregressive language models with rectified flow. It improves stability and efficiency in text-to-image generation while outperforming earlier unified approaches.
You can adopt the Janus line for applications that need vision + language integration, like multimodal assistants.
-
DeepSeek-OCR: DeepSeek’s open-source VLM that redefines optical character recognition through a concept called Contexts Optical Compression. DeepSeek-OCR-2 is the latest iteration.
Beyond DeepSeek: Community-driven innovations#
DeepSeek has ignited a wave of open-source innovation, with researchers and developers extending their models in creative ways. Here are two examples:
- DeepScaleR-1.5B-Preview is a model fine-tuned from DeepSeek-R1-Distill-Qwen-1.5B using distributed RL to scale up long-context capabilities. It improves Pass@1 accuracy on AIME 2024 by 15% (43.1% vs. 28.8%), even surpassing OpenAI O1-Preview — all with just 1.5B parameters).
- Jiayi Pan from Berkeley AI Research successfully reproduced the reasoning techniques of DeepSeek R1-Zero for under $30. This is a huge step in making advanced AI research more accessible.
These community efforts demonstrate how open source enables researchers and developers to create more accessible and powerful AI solutions.
FAQs#
Is DeepSeek better than ChatGPT?#
It depends on what you need.
DeepSeek models like V3.2 and R1-0528 match or even surpass ChatGPT (GPT-4/4o) in tasks such as math, coding, and multi-step reasoning. They’re also fully self-hostable, meaning you can deploy them privately with your own infrastructure using tools like BentoML and vLLM.
In contrast, ChatGPT (powered by OpenAI’s proprietary models) provides stronger general-purpose conversation quality, a smoother user experience, and access to integrated tools (vision, image generation, etc.). However, it’s closed-source and must be accessed through OpenAI’s API.
If you want control, customization, transparency, and cost-efficiency, DeepSeek is a great choice for self-hosting. You can fine-tune it with proprietary enterprise data, making it far more capable in specialized fields like medicine, law, or finance. Note that OpenAI also provides open-source models (gpt-oss) for self-hosting.
If you prefer ease of use with no infrastructure management, ChatGPT (or the OpenAI API) is a more convenient option.
Does DeepSeek have a limit?#
Yes, but it depends on how you deploy it.
If you’re using DeepSeek through its official API, you face usage limits similar to other hosted services, such as rate limits, token quotas, and pricing tiers. These limits are set by DeepSeek’s API provider and can vary depending on your subscription plan.
However, if you self-host DeepSeek, you can remove most usage restrictions entirely. In this case, your only real limits are your hardware capacity (GPU memory, number of concurrent users, etc.) and deployment configuration.
How to run DeepSeek locally#
If you just want to chat with DeepSeek locally on your laptop, you can use Ollama. It’s simple to set up and great for individual experimentation, but not suitable for high-throughput or enterprise deployments.
For teams that need better scalability and reliability, BentoML is the recommended solution. It supports multi-GPU, BYOC, and multi-cloud setups for production-grade DeepSeek deployments. Schedule a call with us if you need any help.
Can DeepSeek generate images?#
No. Most DeepSeek language models are text-only and designed for reasoning, coding, and conversation rather than image generation.
However, DeepSeek has a separate family of multimodal models called the Janus series, built specifically for image understanding and generation.
If your goal is visual generation, try Janus or Janus-Pro.
What’s next#
Now that you’re familiar with the DeepSeek models, you may be thinking about building your own AI applications with them. At first glance, calling the official DeepSeek API might seem like the easiest solution; it offers fast time to market with no infrastructure burden.
However, this convenience comes with trade-offs, including:
- Data privacy and security risks
- Limited customization (no inference optimization or fine-tuning with proprietary data, etc.)
- Unpredictable behavior (rate limiting, outages, API restrictions, etc.)
As organizations weigh their options, many are turning to private deployment to maintain control, security, and flexibility.
At Bento, we help companies build and scale AI applications securely using any model on any cloud. Our inference platform lets you deploy any DeepSeek variant on any cloud provider or on-premises infrastructure, offering:
- Access to a variety of GPUs in the most cost-effective regions
- Flexibility to deploy in your private VPC
- Advanced autoscaling with fast cold start time
- Built-in observability with LLM-specific metrics
Check out the following resources to learn more:
- [Blog] Secure and Private DeepSeek Deployment with BentoML
- Choose the right NVIDIA or AMD GPUs for DeepSeek models
- Choose the right deployment patterns: BYOC, multi-cloud and cross-region, on-prem and hybrid
- Contact us for expert guidance on secure and private DeepSeek deployments
- Join our community forum to stay updated on the latest AI developments
- Sign up for BentoCloud and deploy your custom DeepSeek-powered application today