Yatai 1.0: Model Deployment On Kubernetes Made Easy
Authors

Last Updated
Share

For years the team at BentoML has proudly worked to maintain and grow our popular model serving framework, BentoML. As our user base has grown in size and maturity, we realized that even though one of the framework’s best features is providing flexibility in deployment, certain deployment features were still missing.
For example, with the proliferation of different ML training frameworks, we’ve seen multi-model deployment grow in popularity. As such, better scaling solutions for graph inference have often been requested. In addition, as Data Science teams grow, better solutions to centralize model storage to streamline collaboration between teams has also become a recurring discussion. Storing models in s3 doesn’t scale forever. ;)
From the team and community behind BentoML, we’re proud to present our latest innovation in ML deployment and operations, Yatai.
Yatai is an open-source, end-to-end solution for automating and running ML deployment at scale. It is specially designed to deploy and operate ML services built from all of the most popular frameworks like Tensorflow, Pytorch and XGBoost. The BentoML framework packages your models into a standardized format which is the foundation for this deployment automation.
Yatai was built for developers who want a robust ML deployment pipeline but don’t want to rebuild a system from the ground up.
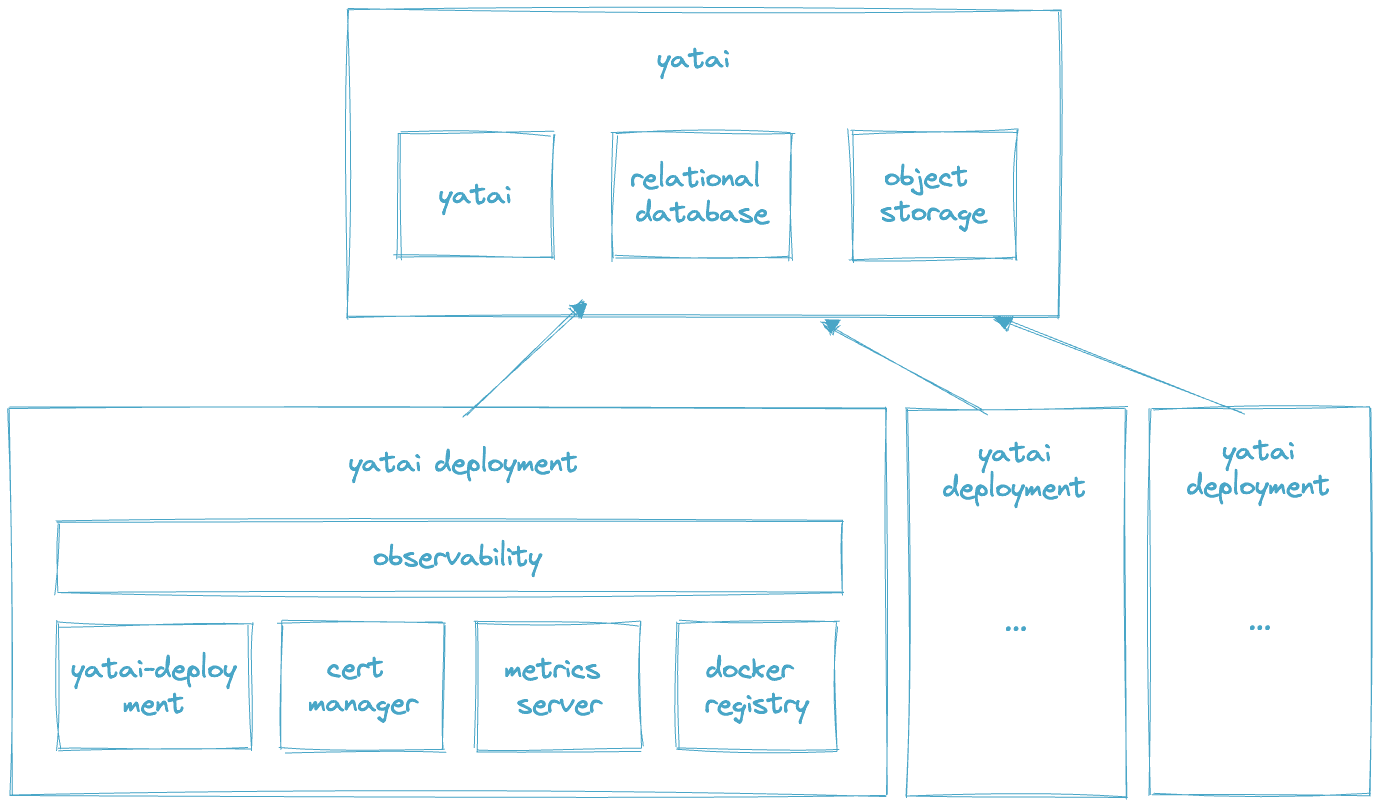
Scaling Model Serving In Kubernetes#
There’s no doubt Kubernetes offers powerful primitives which, if used properly can offer tremendous scaling benefits. Yatai is a Kubernetes-native platform that employs many of those Kubernetes primitives and offers several of its own for seamless ease of use.

Scaling Heterogeneous Workloads#
ML services possess different scaling characteristics than traditional web applications. For example, unlike most web applications, ML services are less IO-intensive and more compute-bound. This means that they are more likely to rely on underlying hardware in order to scale properly. In fact, different parts of the same ML service can perform better if run on separate hardware. This can be challenging to deploy because the ML service itself must be split up into different smaller microservices that run on specialized hardware in order to scale efficiently.
Yatai provides a simple way to deploy these types of heterogeneous workloads. By taking advantage of the BentoML framework, which is easy to implement, Yatai is automatically able to turn an easily understood Python-based Bento into separate micro-services which can be deployed on the hardware of your choice.
For example, this specialized deployment architecture allows users to easily deploy inference and transformations separately, where model prediction can run on GPU nodes and preprocessing transformations can run on cheaper CPU based nodes. This efficiently scales your workloads as traffic increases. No YAML required!
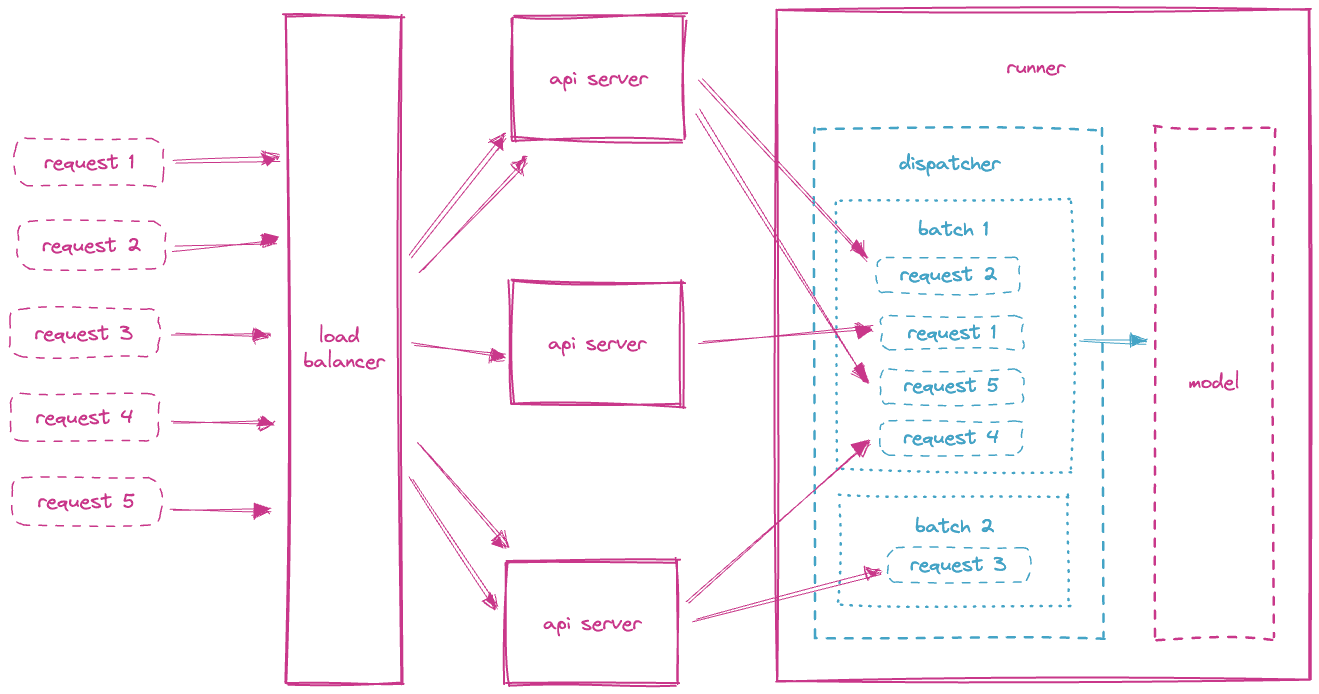

Features like adaptive micro batching provide additional throughput in this type of distributed architecture.
Graph Inference With Dynamic Microservices#
At BentoML, we believe that software should be powerful, but easy to use. Which is why deploying inference graphs with different types of models was a difficult problem. How do you manage a graph of various models and dependencies without getting bogged down by messes of YAML and duplicated deployment pipelines?
Enter BentoML’s Runner abstraction which was specifically designed to solve this problem. Yatai deploys runners in separate autoscaling groups from the API endpoint. This means that you can independently scale up different pieces of your pipeline depending on your specific bottlenecks. Consider the following pseudo-code which is typical of many computer vision services:
@svc.api(input=..., output=...) async def classify(input_image): standardized_data = preprocessing(input_image) return await asyncio.gather( model_a_runner.predict.async_run(standardized_data), model_b_runner.predict.async_run(standardized_data), )
Yatai will automatically create 3 autoscaling groups, one for the “preprocessing” step, and one for each of the “model_X_runner” inference steps. Those individual autoscaling groups can be configured with their own resources and behaviors to ensure your inference graph scales without bottlenecks.
DevOps Practices Baked In From Day One#
Over the years we’ve been asked many questions about how to best integrate BentoML with different types of DevOps tooling. Out of the box, BentoML integrates with a vast number of tools, however there were some common best practices which we repeatedly saw used by the savviest ML teams.
Observability Tooling#
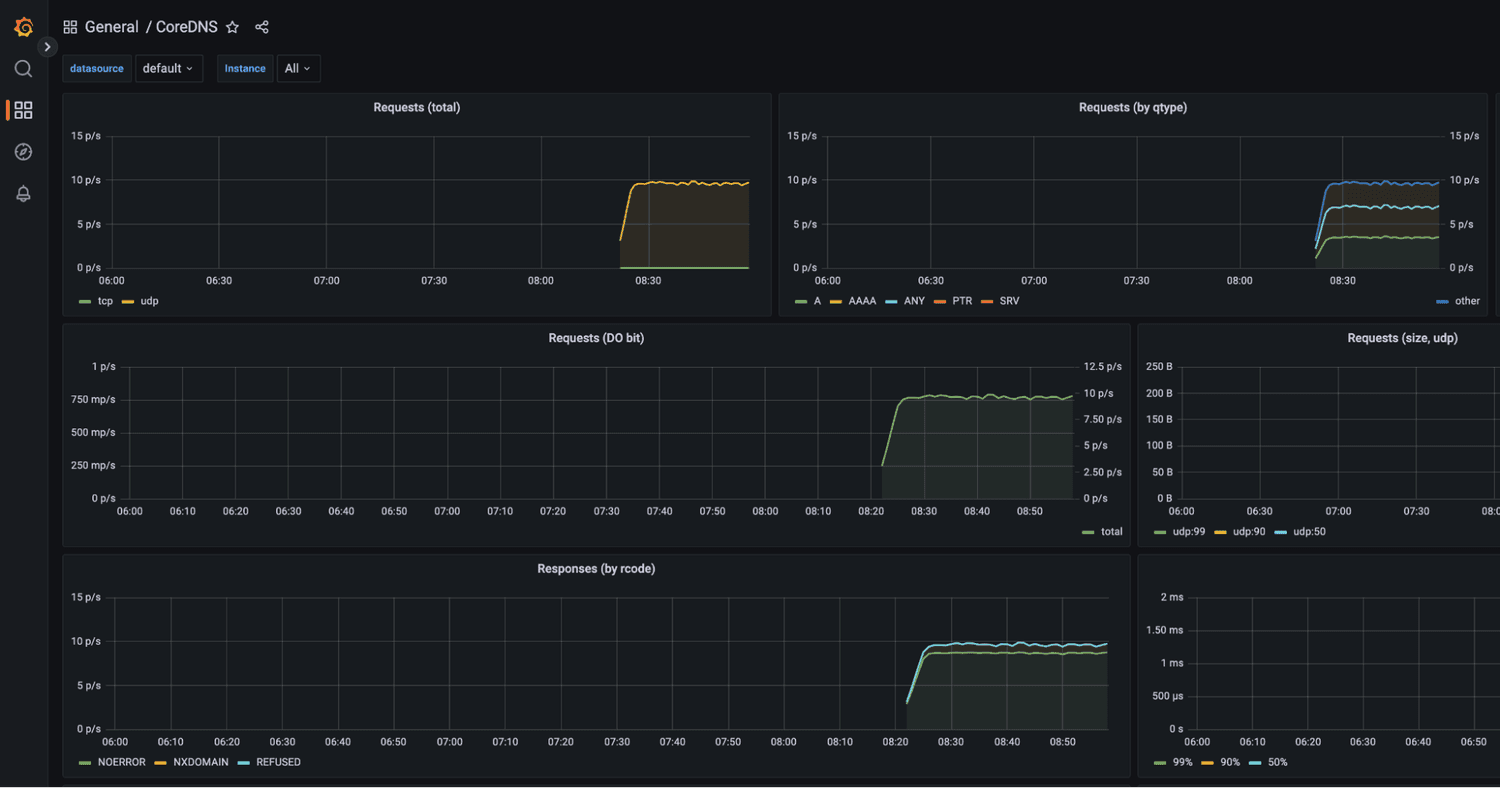
BentoML implements metrics endpoints out of the box, but isn’t opinionated about how you collect or graph these metrics. Yatai gives you the scripts necessary to easily spin up your own observability tools and visualize both your standard and your custom metrics. Our tools of choice are Prometheus to extract the metrics and Grafana to display graphs and alarm if needed. Output monitoring on custom metrics is fully supported and integrated.

Deployment Resiliency#
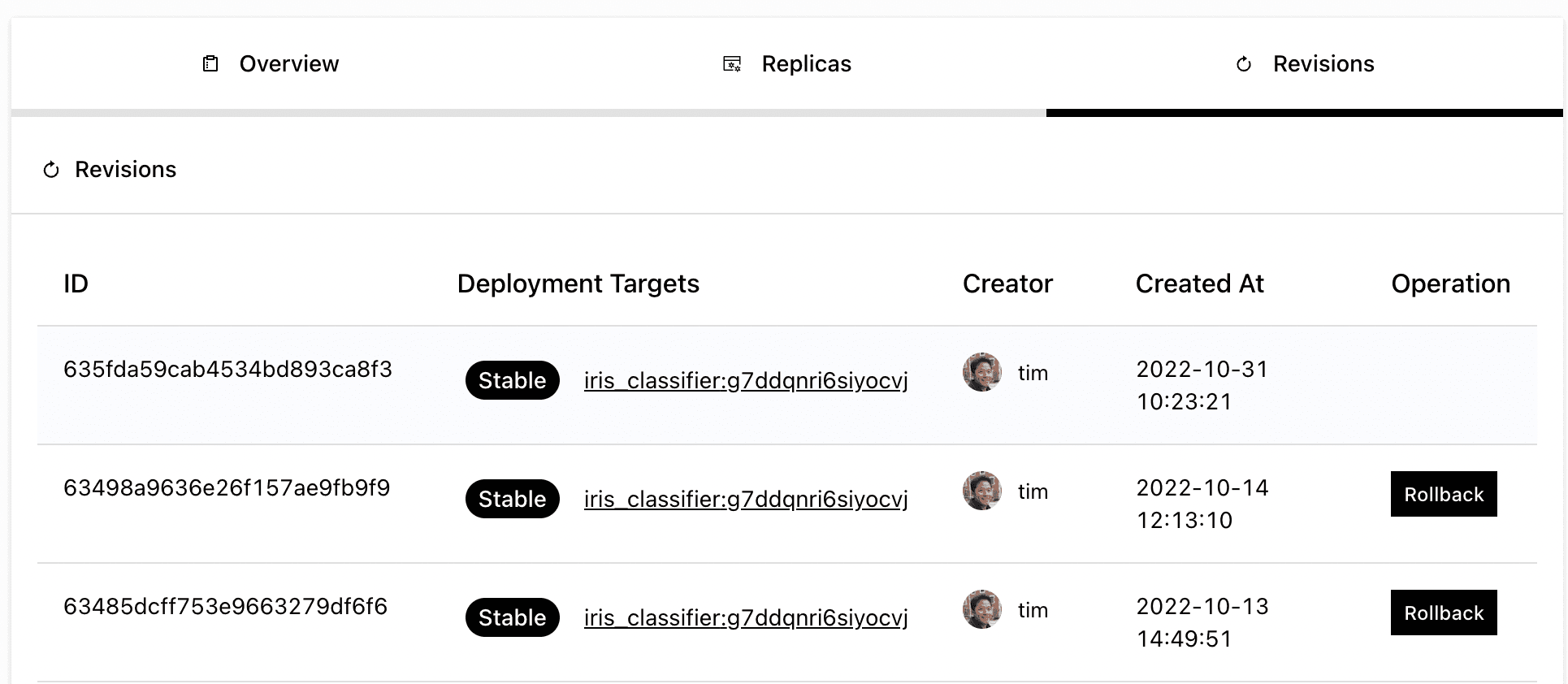
Most deployments when architected well have various ways to detect and rollback to a stable version if a deployment isn’t healthy. However building a system like this requires implementing health checks, proper traffic routing, versioning, and more. Yatai implements Kubernetes standard rolling deployments while automatically making use of BentoML’s standard health endpoints. Finally, because we containerize and store multiple versions of a Bento service, we can easily rollback to an earlier version.

CI/CD Integration#
With constantly evolving data, models and code, in the world of ML, it’s more important than ever to have a bulletproof CI/CD pipeline that automatically deploys to production if everything looks good (without requiring an engineer’s time!). This is why Yatai has many different ways to integrate into your pipeline at the development and production deployment stages.
Single-click deployments from the UI handle straightforward use cases where time is of the essence.
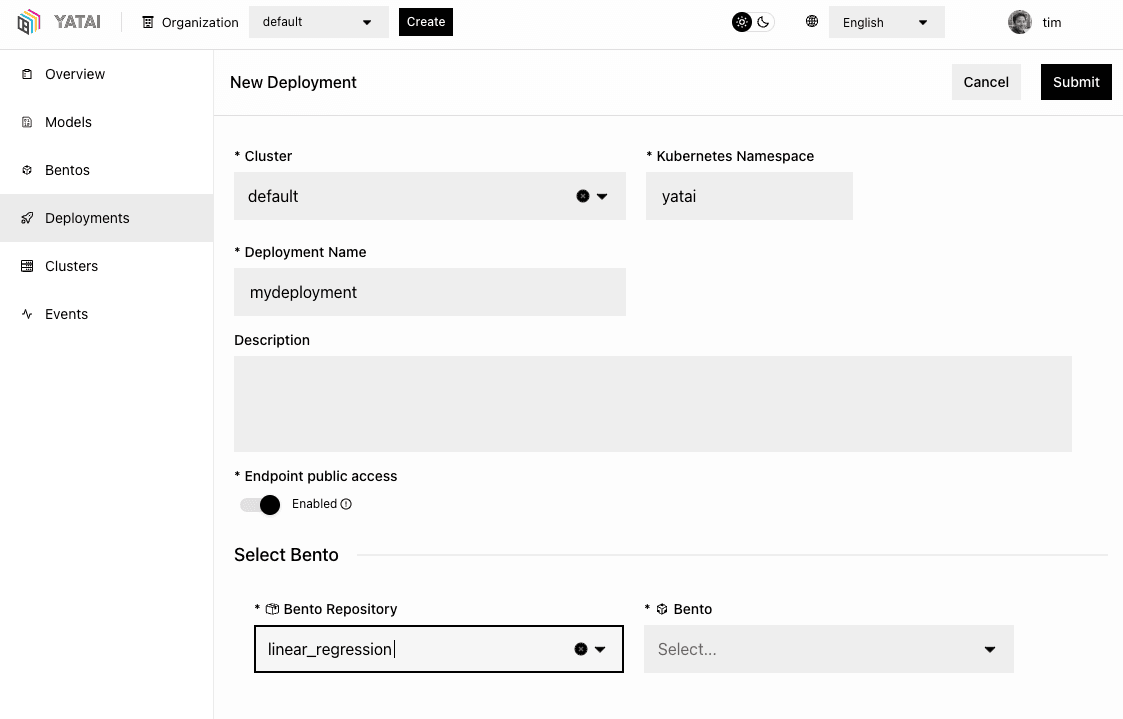

Simple push and pull commands allows you to use your favorite integration tools like Jenkins, CircleCI and Github Actions to build your service then push it to Yatai for deployment.




Yatai also provides a fully featured REST API which has endpoints for all of its functionality.
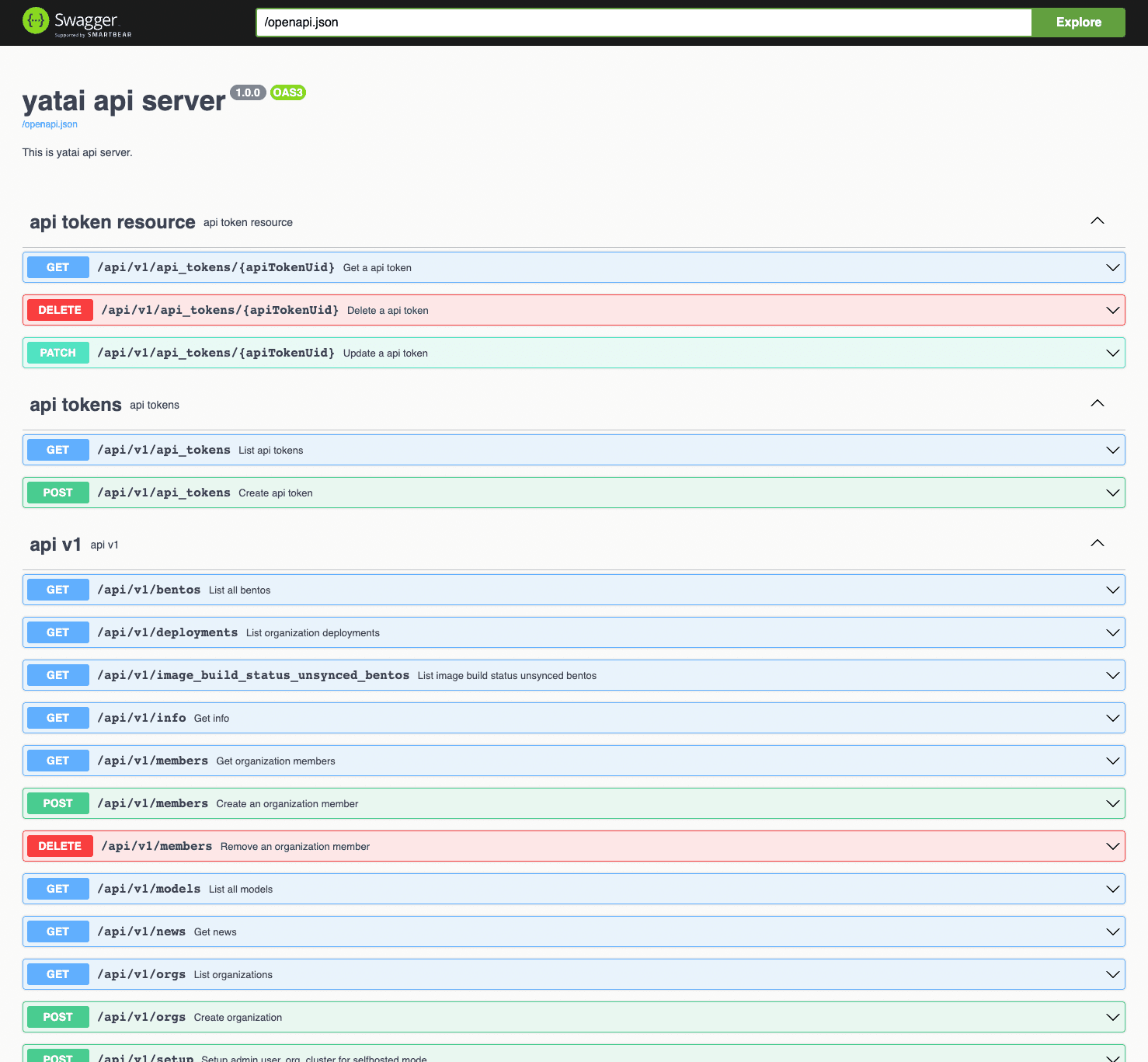

And because GitOps workflows are the emerging best practice for deployment, Yatai fully supports deployment via Kubernetes configuration file which can be stored and versioned as part of your GitOps workflow.
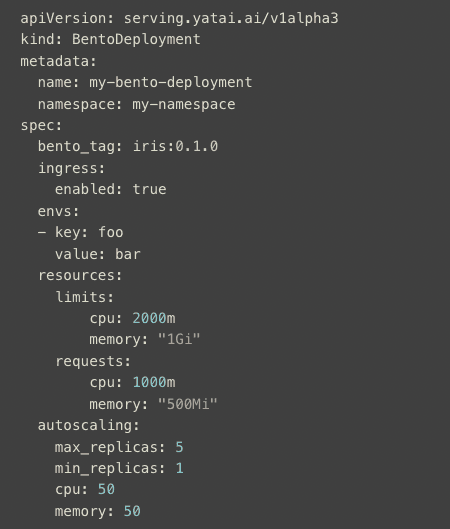

Container Accessibility#
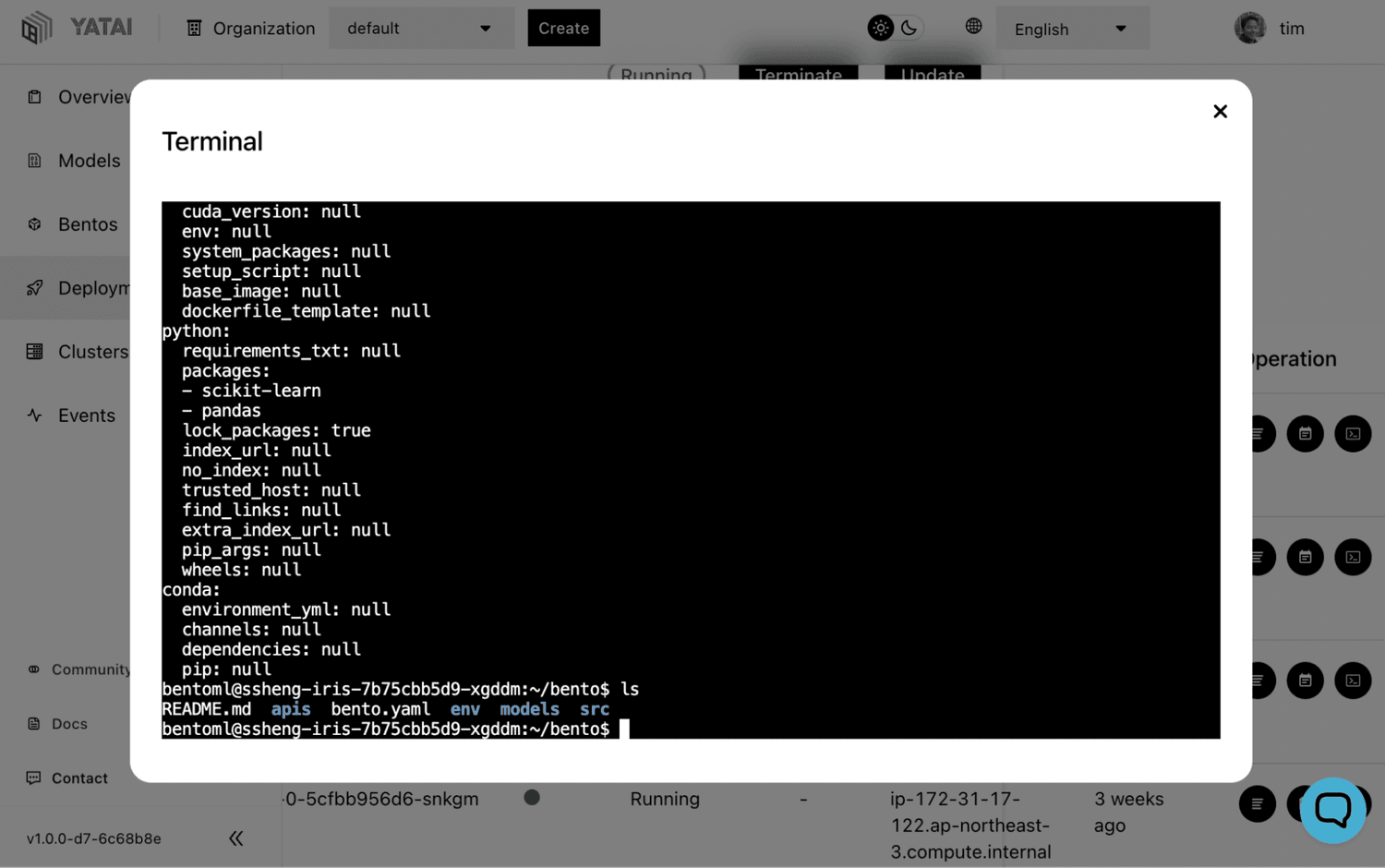
Deployed containerized services can sometimes present accessibility challenges in a fully distributed environment. This is why Yatai provides tools for easily viewing container logs as well as components to ship these logs via Loki integration to other tools for debugging.
One of our favorite features in Yatai is not only the ability to log into each container using our in-browser terminal UI, we also store access logs and give the ability to replay recorded terminal sessions with the click of a button. :)

Distributed Tracing#
Debugging issues or optimizing performance in a production environment can be challenging because some scenarios are difficult to reproduce especially in distributed environments. This is why BentoML implements various tracing protocols, Zipkin, Jaeger and Open Telemetry to name a few. Yatai takes this a step further and provides the necessary dashboards that integrate with these protocols. Take full advantage of the BentoML standard with Yatai’s suite of integrated tracing tools.
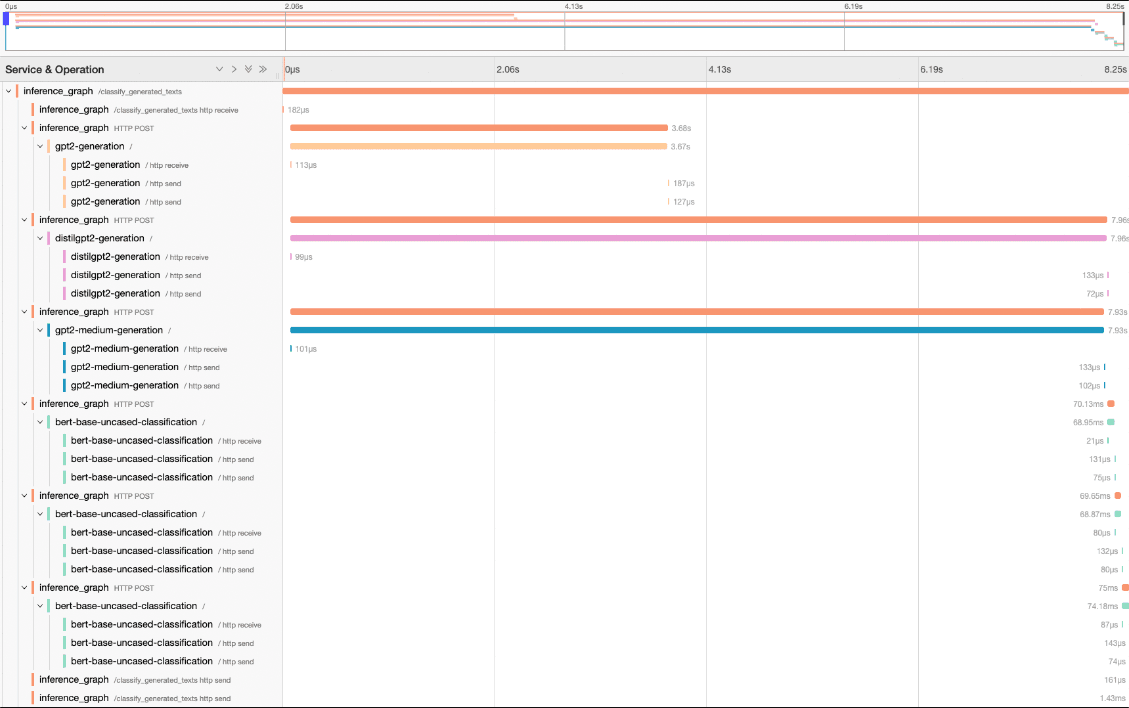

Data Scientists To Ship New Models Faster#
Depending on the ratio of Data Scientists to Software Engineers, we’ve seen a variety of different processes to collaborate and ship models faster. Yatai provides the flexibility you need in order to streamline your ML process. This means Yatai exposes a variety of mechanisms to integrate with your Data Scientists’ workflow. Users can upload models directly from notebooks, their local machines or even remote training frameworks like MLFlow.
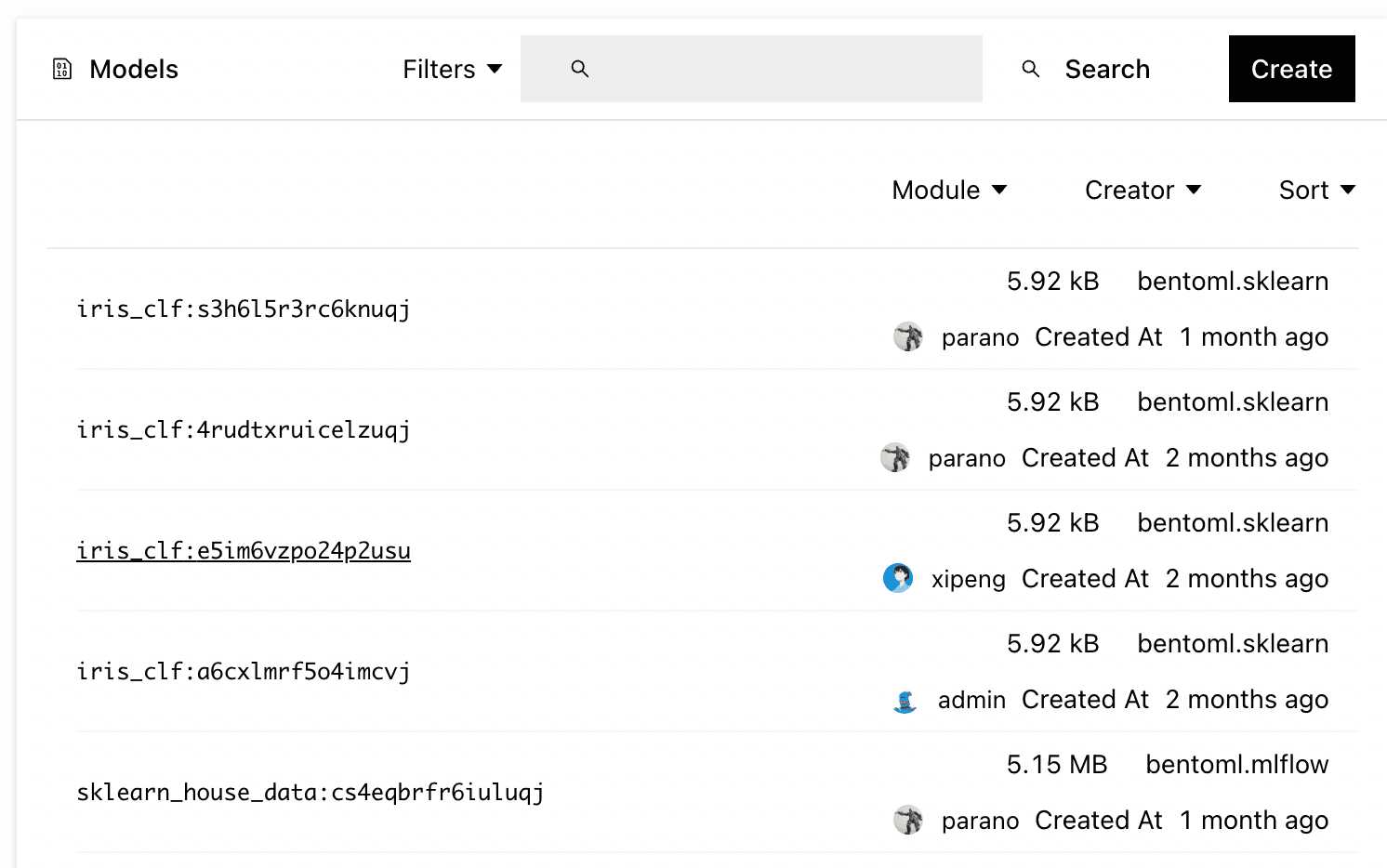

Automatically assigned metadata and manually customized labels allow teams to track a variety of lineage and business specific details so that at any point in the pipeline you can know where a model came from and where it’s about to be deployed.
Getting Started!#
Thanks for reading about our new project release Yatai 1.0. We’re excited about the ways it will help teams grow as they scale their ML workloads.
- To get started, there’s a quickstart guide to the Yatai GitHub repository here!
- For production installations we recommend following this guide.
- And as always, please remember to ⭐ our repo and checkout our Slack community of ML practitioners!