Your ML Model Serving Framework
Authors

Last Updated
Share

BentoML Makes ML Model Serving Easy. Read On To Discover How#
We are in the midst of an AI and machine learning revolution.
In the early days, implementing ML was a feat only the largest (and well-financed) companies could achieve. Now, with proven strategies and more ML resources than ever before, we’ve reached an exciting tipping point. Adoption of ML technologies has picked up steam, with applications that touch nearly every industry. The impact of ML is enormous, and shows no signs of slowing down.
But, there are still some critical challenges standing in the way.
ML model deployment sits at the intersection of data science and engineering. This unique position introduces new operational challenges between these teams. Data scientists, who are typically responsible for building and training the model, often don’t have the expertise to bring it into production. At the same time, engineers, who aren’t used to working with models that require continuous iteration and improvement, find it challenging to leverage their know-how and common practices (like CI/CD) to deploy them. As the two teams try to meet halfway to get the model over the finish line, time-consuming and error-prone workflows can often be the result, slowing down the pace of progress.

Who We Are & What We Do#
We at BentoML want to get your ML models shipped in a fast, repeatable, and scalable way. Our open source ML model serving framework was designed to streamline the handoff to production deployment, making it easy for developers and data scientists alike to test, deploy, and integrate their models with other systems.
BentoML standardizes model packaging and provides a simple way for users to deploy prediction services in a wide range of deployment environments.

So, Why Use BentoML?#
With our framework, data scientists can focus primarily on creating and improving their models, while giving deployment engineers peace of mind that nothing in the deployment logic is changing and that production service is stable.
In this article, we’ll dive into some of the key reasons ML teams choose BentoML to simplify model serving:
👍 Designed for ease of use
☁ Deployable in any cloud environment
🚀 Optimized for performance
🌍 Support for all major ML frameworks
Designed For Ease Of Use#
Our “bento” format simplifies the many different aspects that need to be considered prior to deployment. Managing dependencies and versioning code and models becomes simple. Monitoring and logging is included out of the box.
And because ML model deployment scenarios can range from straightforward to fairly complex, we provide users with high-level API abstractions and sensible defaults with built-in best practices for the simpler use cases, and a flexible configuration system and low-level building blocks for users who need more advanced options.
BentoML was also built with first-class Python support, which means serving logic and pre/post-processing code are run in the exact same language in which it was built during model development. You no longer need to juggle handoffs between teams or re-write Python transformation code for deployment environments that use a different programming language. The Python code can be embedded directly within the service itself, saving hours of additional development work.
Deployable In Any Cloud Environment#
Our standardized “bento” packaging provides a simple way for users to standardize running a prediction service in a wide range of deployment environments. Once packaged, our library of deployment targets allow you to easily spin up a scalable, production-ready service in the cloud environment of your choosing.
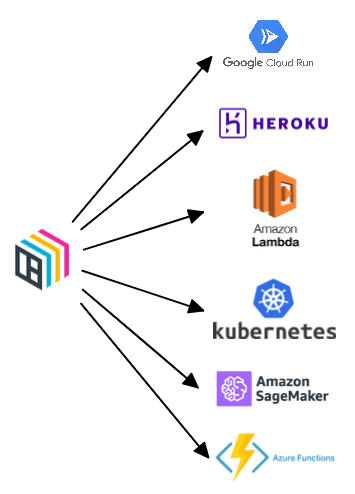
Deploys to any major cloud provider
To make bentos even more portable, BentoML creates docker images that are fully deployable as a service in many different infrastructures. Depending on the cloud environment, BentoML will package the docker image differently to comply with the needed infrastructure requirements. This is one of the many best practices we implement under the hood so that you don’t need to.

Deployables are versioned as docker images and can be easily rolled back
For example, AWS Lambda requires the source code to follow a particular layout in order to be run from a container. While we still have the odd, “Well it worked on my machine” moment, docker’s containerization solution is a fairly standard pattern for minimizing deployment issues that arise from environmental misconfigurations. If you’re not able to use docker, you can still run a production service off of the raw bento itself.
Optimized For Performance#
BentoML’s architecture was designed after years of helping thousands of data scientists and engineers deploy their various prediction services. Our framework provides numerous performance optimizations depending on the infrastructure that you’re running and flexible ways to extend the framework if needed.
Adaptive micro batching allows users to take advantage of native library support to perform faster inference on a group of inputs. At scale, this makes a huge difference in the number of inferences that the service is able to handle. This fairly advanced feature exists as a simple flag that the user can enable.
Additionally, we allow you to take full advantage of multi-core machines by managing different processes for inference — a feature that we provide out-of-the-box. Those of you who know Python well know that the GIL does not make this easy, but we provide it as a straightforward feature that users can easily configure. This architecture allows you to do even more advanced performance tuning. If you have Kubernetes, you can even scale your pod groups depending on the individual compute requirements of a single part of your ML serving pipeline via Yatai, our best of breed deployment service.
Support For All Major ML Model Frameworks#
BentoML integrates with many great modeling and training frameworks in the industry — from industry heavyweights like Tensorflow and Pytorch, to more specialized solutions like EasyOCR. And it doesn’t stop there — our vibrant community of open source supporters contribute to the integration library on a regular basis. Data scientists get to use a tool that they already know, and engineers don’t need to re-adapt the deployment pipeline for new model frameworks.

All major frameworks supported along with easily pluggable system for custom models
So — What About Our Name?#
Our name, BentoML, was inspired by the Japanese bento — a single serving meal in a box, with neat, individualized compartments for each food item. Similarly, we take your model, code, dependencies, and configuration, packaging them into one deployable container!

Your delicious packaging for ML serving and deployment
Get Started With BentoML Today#
Try us out today, and be sure to join our growing Slack community!