Bring Your Own Cloud (BYOC)
Enterprise AI teams face a challenge: how to quickly scale LLM workloads without losing control of data, infrastructure, or costs.
Most organizations start with SaaS inference platforms because they’re quick to set up and fully managed. As workloads grow, however, these platforms can become expensive and restrictive.
- Your data leaves your virtual private cloud (VPC)
- You never truly know what you’re paying for GPU time
- Compliance checks get harder to pass
That’s where Bring Your Own Cloud (BYOC) comes in.
What is Bring Your Own Cloud (BYOC)?
Bring Your Own Cloud (BYOC) is a deployment model that lets you run a vendor’s software, such as an LLM inference platform, directly inside your own cloud account. You get the convenience of managed orchestration while keeping your compute, data, and networking fully under your control.
This model has become especially important for modern AI infrastructure. On one hand, AI models and tooling evolve so quickly that building and maintaining every part of your inference stack in-house slows innovation and time to market. On the other hand, you still want to own where and how your workloads run, especially when they handle sensitive data.
BYOC bridges this gap. It lets organizations maintain control over data, security, and operations while still benefiting from vendor-managed orchestration. In other words, you can move fast without giving up compliance or sovereignty.
A simple way to picture it:
- SaaS: Vendor runs everything.
- On-prem: You run everything.
- BYOC: The vendor runs the software in your cloud, under your rules.
BYOC began as a niche option for data-sensitive enterprises. Now, it becomes a mainstream deployment pattern for large-scale LLM and AI workloads.
How does BYOC work?
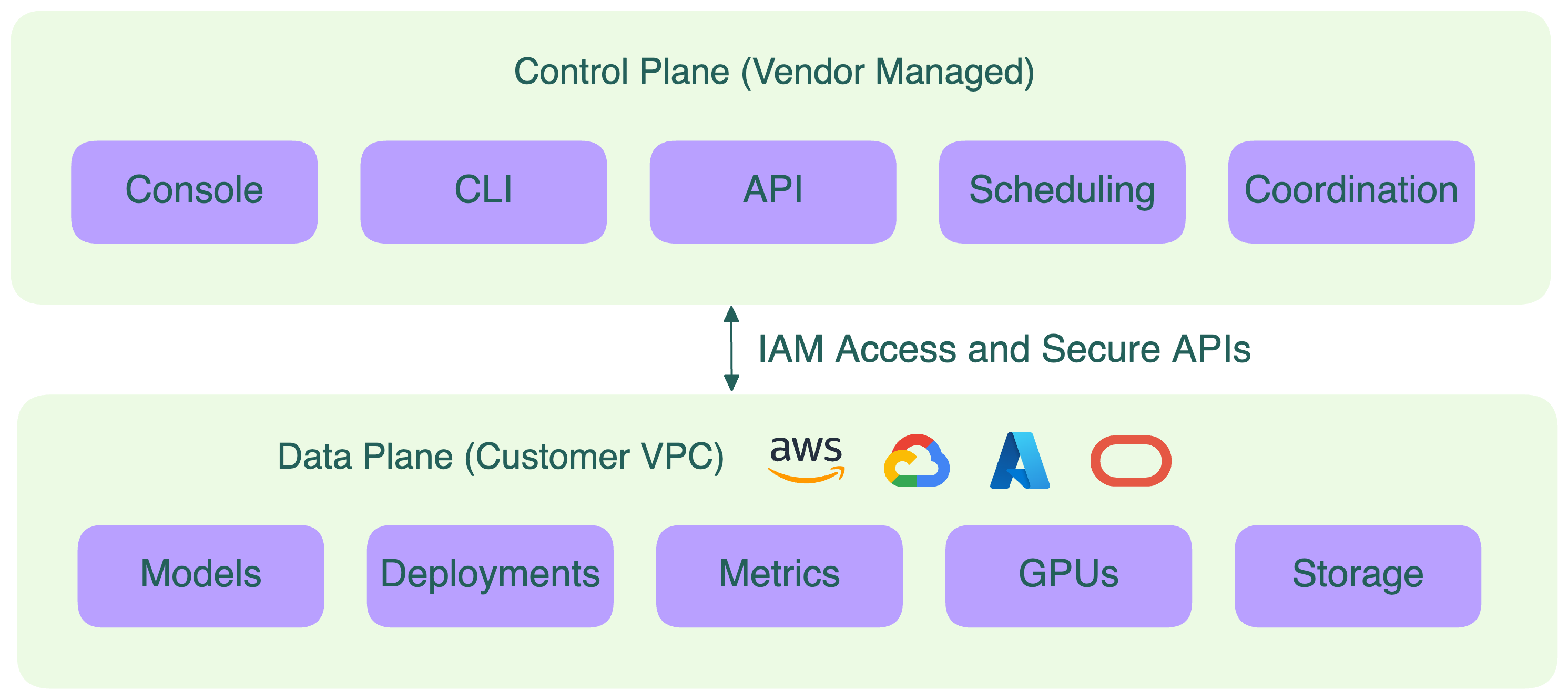
In a BYOC deployment, you and the vendor share responsibility. The vendor manages the control plane while the data plane components stay entirely in your cloud environment. As the customer, you’re responsible for managing your own cloud resources (though some tasks may be offloaded to the vendor), IAM permissions, and networking configurations to ensure security and reliability. Ideally, the vendor never has direct access to your raw data or private network.
Here’s how it typically works:
- Control plane (vendor-managed): Handles deployment coordination, scaling policies, scheduling, updates, and more. It communicates with your environment through secure APIs.
- Data plane (customer-managed): This is where inference happens. Your models, GPUs, compute instances, and data all live inside your own VPC, ensuring compliance, privacy, and full isolation.
- Networking and IAM boundaries: BYOC relies on strict permission scoping. The vendor can manage deployments programmatically (for example, through IAM roles or cross-account access), but is unable to view or exfiltrate data. Logs (the vendor may have access to them for debugging purposes), metrics, and model outputs stay within your environment.
This hybrid design offers the best of both worlds:
- The ease of a managed platform that handles orchestration and updates.
- The assurance that your LLM workloads, data, and GPUs remain in your control.
There may be nuances in how BYOC is implemented, depending on an organization’s requirements. For example, in industries like defense or healthcare, teams may require complete control over both the control plane and data plane. This ensures maximum security and compliance assurance, often within fully isolated or air-gapped environments.
Modern inference systems, like those built on vLLM, SGLang, or BentoML, fit naturally into this model. They run on your existing cloud infrastructure while connecting seamlessly to a centralized control plane.
Benefits of BYOC for LLM workloads
The appeal of BYOC goes well beyond compliance. Here are the key benefits:
Data sovereignty and compliance
LLMs are widely adopted in enterprise systems like RAG or AI agents. These applications often need to access sensitive information (e.g., customer records) that can’t leave a private network.
With BYOC, all model inputs, outputs, and logs stay inside your own VPC and cloud region. Nothing leaves your environment unless you choose to share it. This makes it far easier to meet regulatory requirements such as GDPR and to satisfy internal security reviews.
For organizations in finance, healthcare, or the public sector, this level of control is a must.
GPU flexibility and availability
LLM inference depends heavily on GPUs and supply often fluctuates across regions and providers. Many vendors support multi-cloud architectures for BYOC. They let you choose where to run your workloads, whether that’s on AWS, GCP, Azure, or a mix of all three.
This means you can:
- Pick the cloud provider with the best GPU availability and pricing for your workloads.
- Take advantage of region-specific pricing or promotions.
- Combine different GPU types (e.g., NVIDIA A100, H100, or AMD MI300X) to match cost and performance needs.
This flexibility ensures you’re never stuck waiting for capacity or overpaying for compute.
Cost optimization and efficiency
With BYOC, you run inference in the same environment as your data, reducing expensive egress fees from cross-cloud data transfer. For teams processing large datasets, this alone can translate into major cost savings.
It also helps you make the most of existing cloud investments:
- Use cloud credits or startup programs directly within your account.
- Apply committed use discounts, savings plans, or spot pricing to inference workloads.
- Aggregate spend across workloads to unlock enterprise-level discounts from your provider.
For example, BentoCloud’s BYOC mode provisions compute directly in your account, so you can deploy models using the same credits, discounts, and billing relationships you already have.
No vendor lock-in
BYOC keeps your infrastructure cloud-neutral. You’re not tied to the stack or hardware of a single cloud provider. That means your LLM deployment strategy remains future-proof. As your needs change, you can freely move workloads across clouds, GPUs, or orchestration tools.
SaaS vs. BYOC vs. On-prem vs. Hybrid
Choosing how to deploy your LLMs is essentially about where your models live and who runs the infrastructure. Each deployment model — SaaS, BYOC, On-prem, or Hybrid (On-prem + BYOC) — offers different trade-offs between control, cost, and complexity.
Here’s a quick comparison:
| Model | Where it runs | Who manages infrastructure | Data control | Best for |
|---|---|---|---|---|
| SaaS | Vendor’s cloud | Vendor | Low: data resides in vendor’s multi-tenant environment | Fast setup, minimal ops overhead, quick prototyping, non-sensitive data |
| BYOC | Customer’s cloud account (e.g., AWS, GCP, Azure) | Shared between vendor and customer | High: data stays in customer’s VPC | Enterprises with security/compliance needs, GPU cost optimization, flexible scaling |
| On-prem | Customer’s private data center | Customer | Full: data and compute remain entirely on customer infrastructure | Air-gapped or highly regulated industries (e.g., defense, healthcare) |
| Hybrid (On-prem + BYOC) | Split between customer data center and cloud account | Shared between customer and vendor | Full: on-prem for sensitive workloads, cloud for burst capacity | Organizations needing more flexibility while maintaining strict data boundaries |
For most enterprise LLM workloads, BYOC provides the best middle ground. It’s fast to deploy, secure by design, and cost-efficient at scale. However, hybrid architectures are becoming the bridge between full control and global agility. In a hybrid setup, you can deploy models on-prem for maximum control, data security, and compliance, while overflowing to cloud GPUs during traffic spikes. Learn more in the GPU CAP Theorem blog post.
We offer a fully-featured AI inference platform which can be deployed into your own cloud account for maximum control, security, and customization.
With our BYOC deployment, you can:
- Run models inside your own VPC across providers like AWS, GCP, or Azure and leverage your existing credits and commits
- Keep your data and workloads fully within your environment
- Run and scale inference across NVIDIA, AMD, CPUs, and more in the same BYOC deployment
- Apply the latest distributed inference techniques like prefill-decode disaggregation in your private cloud
Frequently asked questions
Can BYOC work with multi-cloud or hybrid deployments?
Yes. BYOC fits naturally into hybrid and multi-cloud architectures. Depending on your securiy and compliance policy, sensitive workloads can stay on-prem or in one cloud, while overflow or global inference traffic scales into others.
How does BYOC differ from SaaS?
In SaaS, the vendor hosts and manages everything in their own environment. In BYOC, the vendor manages the control plane while the data plane runs in your cloud. You keep ownership of compute, storage, and network resources.
What are the trade-offs of BYOC?
You gain more sovereignty and flexibility but take on part of the operational burden, namely managing your own cloud environment, IAM roles, and monitoring. Many teams offset this by using managed BYOC solutions.