6 Production-Tested Optimization Strategies for High-Performance LLM Inference
Authors

Last Updated
Share

As enterprise AI systems scale across cloud and on-prem environments, inference quickly becomes the primary bottleneck. Larger models, longer context windows, multi-tenant workloads, and unpredictable traffic patterns place constant pressure on latency, throughput, and GPU spend. What worked during early experimentation or limited production pilots often breaks down once inference becomes a core, always-on part of the product.
For Heads of AI, the symptoms are familiar. Time-to-first-token (TTFT) spikes during peak usage. Decode slows as prompts and conversations get longer. KV cache pressure caps concurrency earlier than expected. Teams respond by adding more GPUs, sharding traffic, or layering ad-hoc fixes, only to find costs rising faster than performance improves. These constraints directly affect user experience, system reliability, and time to market.
Optimization changes that trajectory. With the right inference strategies, teams can extract significantly more performance from the same hardware, improving TTFT, throughput, concurrency, and cost per token.
This guide helps you match specific LLM inference bottlenecks to the highest-impact optimization strategies, and understand when to implement each one as your workloads evolve.
Why optimizing LLM inference is critical for enterprise AI systems#
As LLM workloads scale, inference becomes the dominant driver of system performance and cost. Latency, reliability, and GPU utilization are no longer secondary concerns; they determine whether AI features feel usable, trustworthy, and economically viable in production.
Across enterprise inference stacks, the same failure modes appear repeatedly.
- TTFT delays compound user frustration and churn: When prefill compute saturates or batching breaks down, even modest first-token latency spikes make chat and agent experiences feel hesitant. This erodes trust and directly hurts engagement and conversion in interactive applications.
- KV cache fragmentation creates unpredictable tail latencies: Shared prompts, long contexts, and concurrent sessions rapidly consume KV cache capacity. Fragmentation, eviction churn, and cache misses introduce sudden latency spikes, making tail latency unpredictable and undermining SLA reliability.
- Bursty workloads leave GPUs idle and waste budget: When traffic fluctuates and batching isn’t adaptive, GPUs sit idle during off-peak periods and get overwhelmed during bursts, forcing infrastructure to be sized for worst-case scenarios and inflating cost per token.
- Parallelism becomes an operational bottleneck: In many cases, teams need to combine multiple forms of parallelism across workers, GPUs, and nodes. In practice, these configurations are highly sensitive to model size, batch shape, and hardware topology. Teams often rely on trial-and-error tuning, making deployments slow to optimize and costly to operate.
These issues are often just the tip of the iceberg. Together, they slow teams down and make inference increasingly difficult to operate at scale. The following optimization strategies address these failure modes directly, improving developer productivity, stabilizing system behavior, and extracting more value from existing GPU infrastructure.
6 optimization strategies for improving LLM inference performance#
Most production systems don’t suffer from a single isolated bottleneck. TTFT delays, decode slowdowns, KV cache pressure, and throughput collapse often appear together and reinforce one another. Before diving into individual strategies, it helps to understand how different optimizations map to these bottlenecks and where each is most effective.
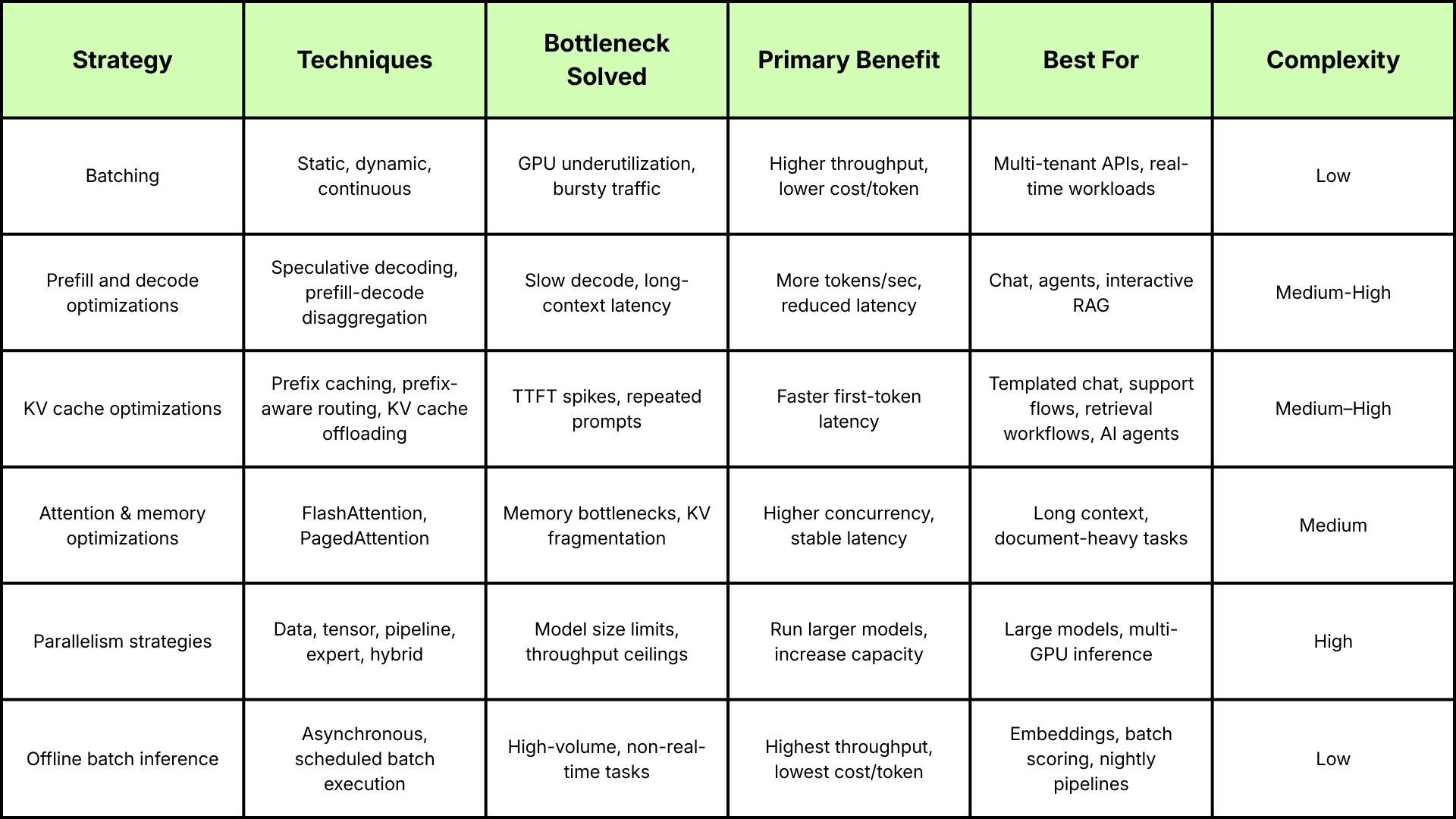
With that high-level map in place, let’s explore each optimization strategy in more detail.
1. Batching#
Batching is often the first and highest-impact optimization that teams apply when scaling inference. At its core, batching improves GPU utilization by processing multiple requests together instead of handling them one at a time.
- Static batching works well for predictable workloads such as embeddings, ETL jobs, or offline ranking, where request sizes and arrival patterns are known in advance.
- Dynamic batching extends this idea to real-time systems by grouping variable-size requests at runtime, allowing GPUs to stay busy without introducing unacceptable latency.
- Continuous batching goes a step further by injecting new requests mid-inference, which is particularly effective for multi-tenant APIs and bursty traffic patterns.
Batching is powerful not just because it increases throughput, but because it lowers cost per token. Instead of provisioning excess capacity to handle peak traffic, teams can smooth variability and operate closer to optimal GPU efficiency.
In practice, these gains compound quickly. Neurolabs accelerated its product launch by nine months and avoided hiring additional infrastructure engineers after standardizing model-serving workflows on BentoML, which enabled efficient batching and scaling without building custom infrastructure.
2. Prefill and decode optimizations#
LLM inference can be divided into two very different phases: a prefill pass that encodes the full prompt and builds the KV cache, and a decode loop that generates one token at a time by repeatedly reading and extending that cache. As sequence lengths grow and concurrency increases, this per-token decode loop becomes the dominant bottleneck. It caps throughput and inflates cost per request even when GPUs appear “well utilized.”
Prefill and decode optimizations focus on shrinking this token loop and reducing KV cache pressure. Common strategies include:
- Speculative decoding introduces a smaller draft model that proposes candidate tokens ahead of the main model. When those candidates are accepted, expensive computation is skipped, reducing end-to-end latency. This is especially effective for chat, agentic workflows, and interactive applications that generate responses token by token.
- Prefill-decode disaggregation separates the compute-heavy prefill phase from the typically memory-bound decode phase. Treating them independently allows teams to scale each phase on the resources it actually needs, instead of overprovisioning GPUs to compensate for slow token generation.
The impact shows up quickly in production. A fintech loan servicer was able to ship roughly 50% more models after improving the reliability and efficiency of its inference pipeline with Bento’s platform, without expanding its GPU footprint.
3. KV cache optimizations#
Many enterprise workloads reuse long system instructions, safety policies, retrieval templates, or structured prompts across thousands of requests. Recomputing these shared tokens on every request is both wasteful and expensive.
KV cache optimizations eliminate this overhead by making prefix computation and cache residency first-class scheduling concerns:
- Prefix caching stores reusable KV segments so that identical or similar prefixes don’t need to be recomputed during prefill. Prefix-aware routing builds on this by ensuring that requests with the same prefix are routed to the same worker, maximizing cache hit rates.
- KV cache utilization–aware load balancing builds on this by routing requests based on available cache headroom, reducing the likelihood of eviction cascades.
- KV cache offloading shifts older cache segments to CPU or low-cost storage, enabling longer contexts and larger batch sizes without exhausting GPU memory.
The primary benefit of these techniques is reduced time-to-first-token (TTFT) and better resource utilization. Responses can start immediately from cached prefixes, and GPU memory is reserved for active decoding rather than repeatedly rebuilding identical prompt state.
Teams implementing KV cache optimization consistently report sharp reductions in inference latency for templated, multi-turn workflows, particularly in support automation and retrieval-heavy applications.
4. Attention and memory optimizations#
As context lengths grow and workloads become more complex, memory pressure, not raw compute, often becomes the dominant constraint. Attention computation and KV cache management play a central role here.
- FlashAttention avoids materializing the full attention matrix in high-bandwidth memory, instead performing attention directly in fast on-chip memory. This reduces memory traffic, improves GPU utilization, and enables significantly longer context windows, often delivering 2–4× faster attention in practice.
- PagedAttention addresses a different but equally common issue: KV cache fragmentation. By allocating KV cache in fixed-size blocks, it prevents memory fragmentation and stabilizes concurrency under load.
At scale, these techniques translate into operational leverage. By standardizing model serving and inference infrastructure on BentoML, Yext reduced development time by 70% and deployed twice as many models into production, while maintaining performance and reliability across a growing catalog of AI services.
5. Parallelism#
Some workloads push beyond what a single GPU can handle, either due to model size or throughput requirements. Parallelism strategies make it possible to scale inference across multiple GPUs or nodes without rewriting application logic.
- Data parallelism replicates model weights across GPUs to increase throughput for the same model.
- Tensor parallelism splits individual layers across GPUs so larger models fit within per-device memory limits.
- Pipeline parallelism stages execution across devices, enabling extremely large architectures to run efficiently end to end.
- Expert parallelism routes tokens across experts in Mixture-of-Experts architectures, activating only a subset of parameters per token.
- Hybrid parallelism blends multiple approaches (for example, tensor + data) to support large models or optimize resource usage.
Parallelism doesn’t replace other optimizations; it amplifies them. Batching, prefill and decode optimizations, and memory strategies all become more important as systems scale across GPUs. However, with so many different variables, it’s time-consuming and error-prone for teams to find out the optimal configurations for their workloads.
This is where llm-optimizer comes in. It helps teams quickly identify the best combinations of configurations for their throughput and latency goals, without endless trial and error.
6. Offline batch inference#
Not all inference needs to happen in real time. For workloads such as embeddings, lead scoring, nightly analytics, ETL pipelines, and bulk document processing, offline batch inference is often the most cost-effective option.
By running these jobs asynchronously and at scale, teams can maximize tokens per second and minimize cost per token, while reducing pressure on real-time systems so interactive endpoints remain fast and reliable.
How to select the right optimization for your workload#
Choosing the right optimization depends on the bottlenecks you’re actually experiencing, not the ones that happen to be most discussed. Once you’ve identified whether your primary constraint is latency, throughput, concurrency, model scale, or cost, you can map it directly to the strategies in this guide.
To validate which strategies will deliver the most impact, use llm-optimizer to benchmark configurations across vLLM and SGLang under your real SLOs. For teams that want a quicker starting point, the LLM Performance Explorer provides real benchmark data and configuration comparisons without needing to run experiments yourself.
If you’re ready to build a tailored optimization plan for your models and infrastructure, book a demo with the Bento team.