FlashAttention
FlashAttention is an optimized algorithm for computing the attention mechanism in Transformer models. It’s faster, more memory-efficient, and more scalable than standard attention. Introduced in the paper FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness, it has since become a widely adopted attention backend for both training and inference in modern LLMs.
Why attention is slow in the first place
When an LLM reads text, it has to look at every token and compare it with every other token to understand the relationships. This is called attention.
The standard attention mechanism has a fundamental problem: it's memory-bound rather than compute-bound. To understand this, we need to look at what happens during attention computation.
If you want the lower-level GPU context behind ideas like HBM, SRAM, warps, and tiling, see GPU architecture fundamentals.
Standard attention calculates:
The naive implementation follows these steps:
- Compute the attention scores: Multiply Q and K^T to get an N×N matrix (where N is sequence length)
- Apply softmax: Normalize the scores
- Multiply by values: Compute the weighted sum with V
The problem is the memory access pattern. Modern GPUs have:
- High Bandwidth Memory (HBM): Large but slow (1-2 TB/s bandwidth)
- SRAM (on-chip memory): Small but fast (10-20 TB/s bandwidth)
The standard implementation requires writing the full N×N attention matrix to HBM, then reading it back for the next operation. For a sequence length of 4096 tokens, this attention matrix contains ~16 million elements. With multiple reads and writes, the algorithm spends most of its time waiting for memory transfers rather than doing actual computation.
As sequence lengths increase:
- Memory traffic dominates runtime
- GPU utilization drops
- Long context windows become impractical
For example, 16K tokens require 256× more memory than 1K tokens.
How does FlashAttention work?
FlashAttention speeds up attention by reducing memory traffic. The core idea is to never materialize the full attention matrix in HBM. Instead, it uses two key techniques:
- Tiling and recomputation. FlashAttention breaks the computation into blocks (tiles) that fit in fast SRAM:
- Load tiles of Q, K, V from HBM to fast SRAM
- Compute attention for that tile entirely in SRAM
- Update the output incrementally and discard intermediate results
- Kernel fusion. Rather than separate operations (matmul → softmax → matmul), FlashAttention fuses everything into a single GPU kernel. This means:
- No writing intermediate results to HBM
- No separate kernel launches (which have overhead)
- All operations happen in fast SRAM
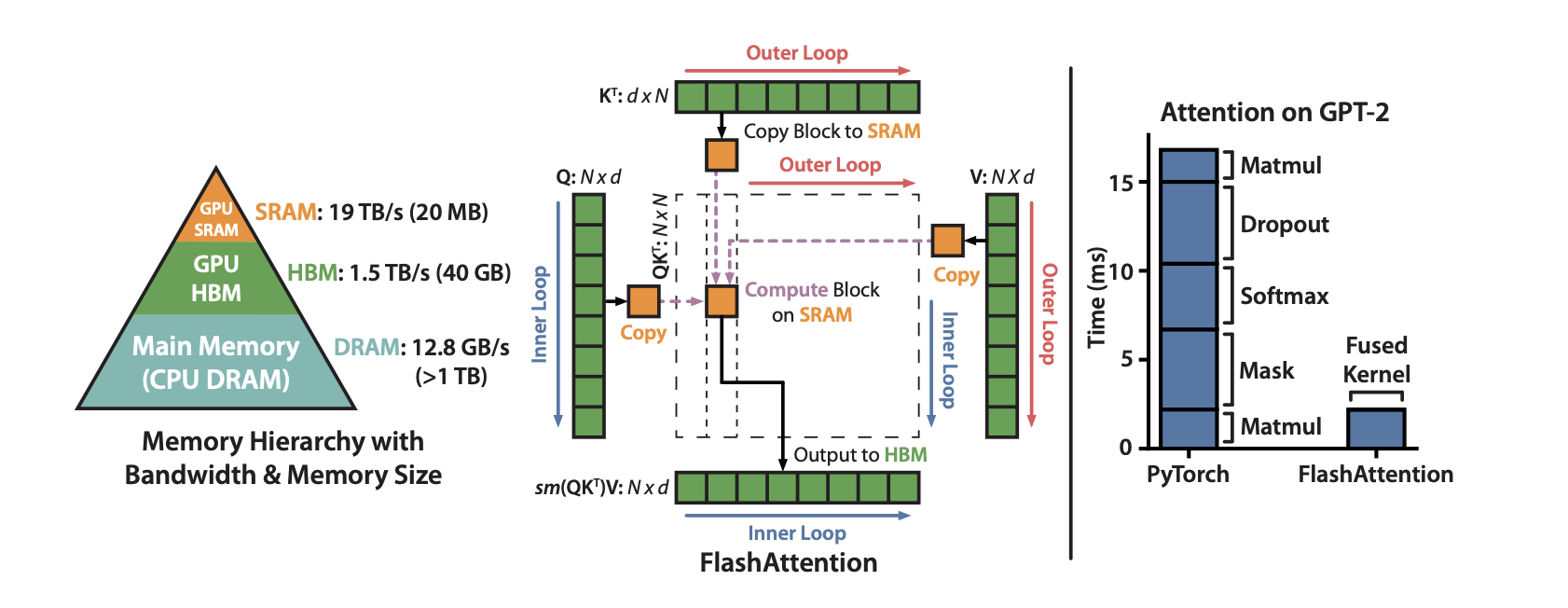
Simply put, FlashAttention makes the attention computation more efficient. It reorganizes the work so the GPU spends less time waiting on memory and more time doing actual computation.
For a broader view of where Triton, CUDA, compiler stacks, and profiling tools fit into this kind of work, see Kernel optimization tools.
The benefits of FlashAttention
FlashAttention provides major improvements in both speed and scalability:
- 2–4× faster attention
- Much lower memory usage since the N×N attention matrix isn't stored
- Allow LLMs to handle longer context windows (e.g., 128K tokens)
- Higher throughput and better GPU utilization
- Faster inference for chat, coding, reasoning, etc.
Currently, FlashAttention is widely used in:
- Training frameworks (PyTorch, DeepSpeed)
- Inference engines (vLLM, SGLang, Hugging Face TGI, TensorRT-LLM)
- Model architectures that support long context
FlashAttention version comparison
The main FlashAttention line now has 4 major versions. Below is a side-by-side comparison that explains how the algorithm has evolved across versions.
| Version | Year | Key Improvements | Performance | Notes |
|---|---|---|---|---|
| FlashAttention-1 | 2022 | Introduced the IO-aware, tiled attention algorithm. Fused softmax + matmul kernels. Avoided materializing the full attention matrix | 2–4× faster attention, up to 10× lower memory | First version; supports practical long-context; exact attention (no approximation) |
| FlashAttention-2 | 2023 | Better parallelism and work partitioning across warps; reduced non-matmul FLOPs | 2× faster than FA-1, especially on long sequences | Powers many long-context LLMs; widely integrated in inference/training frameworks |
| FlashAttention-3 | 2024 | Tensor core acceleration (FP8/BF16); optimized for Hopper GPUs (e.g., H100) | Up to 2× faster than FA-2 and 740 TFLOPS on H100 (75% util); reduced FP8 numerical error by 2.6× | Leverages Hopper asynchronous execution and warp specialization. Many frameworks still upgrade from FA-2 first |
| FlashAttention-4 | 2026 | Fully asynchronous MMA, larger tiles, software-emulated exponentials, conditional softmax rescaling, tensor memory, and 2-CTA MMA | Up to 1.3× faster over cuDNN 9.13, up to 2.7× over Triton, and up to 1613 TFLOPS/s (71% utilization) on B200 BF16 benchmarks | Written in CuTeDSL. The official implementation is exposed through flash-attn-4 and targets Hopper and Blackwell GPUs such as H100 and B200 |
FlashAttention-4 is specifically tuned for the NVIDIA Blackwell architecture. The key insight is asymmetric hardware scaling. Tensor cores (which do the big matrix multiplies like QKᵀ and PV) got much faster on Blackwell. However, other critical resources did not scale as much:
- Shared memory bandwidth.
- Special function units (SFUs) used for exponentials in softmax.
- Register pressure and scheduling overheads.
As a result, on B200, the bottleneck shifts. Learn more in the FlashAttention-4 paper.
How to use FlashAttention
The easiest way to get started is through the official package:
pip install flash-attn --no-build-isolation
Recent PyTorch versions automatically dispatch to FlashAttention via scaled_dot_product_attention when supported. Read the API reference to learn more.
Many inference frameworks have already integrated FlashAttention, including vLLM and SGLang, but their versions may be different depending on their release cycle.
For FlashAttention-4 specifically, the official repository documents a separate CuTeDSL package:
pip install flash-attn-4
On CUDA 13, the repository recommends:
pip install "flash-attn-4[cu13]"
The FA4 API is exposed through flash_attn.cute:
from flash_attn.cute import flash_attn_func
out = flash_attn_func(q, k, v, causal=True)
Check the current FlashAttention repository before relying on it in production, because the FA4 package and framework integrations are moving quickly.
Additional resources
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
- FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
- FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling
- Official FlashAttention repository