Inference routing
Inference routing refers to the process of deciding which worker should handle each LLM request. At small scale, this decision may be hidden inside a model server or a simple gateway. As deployments grow across many replicas and GPUs, it becomes an important part of inference optimization.
A routing decision affects things like:
- Whether a request can reuse existing KV cache
- Whether it gets stuck behind long-running generations
- Whether the target worker has enough memory headroom
- Whether prefill or decode work is already saturating the worker
- Whether the overall GPU pool stays busy across uneven traffic patterns
Therefore, inference routing is closely tied to concepts like prefix caching, KV cache offloading, and prefill-decode disaggregation.
At platform scale, routing is also an economic tool. Better placement keeps GPUs useful across heterogeneous tenants and bursty workloads, not just faster for one request.
On this page, a worker refers to a routable unit that can independently run inference and own some runtime state, especially KV cache. Depending on the deployment, it can map to different things:
- Single process or replica. A vLLM, SGLang, or similar model server process.
- Kubernetes Pod. In many Kubernetes deployments, one model-serving Pod is the worker from the router’s point of view.
- Node. Usually not the same thing as a worker unless the whole node is treated as one serving replica. A node may host multiple Pods or workers.
- GPU group. A worker may use one GPU, multiple GPUs with tensor parallelism, or an entire multi-GPU replica.
Why routing is different for inference
Traditional load balancers treat backends as identical black boxes. A request comes in, any backend can serve it, and the response leaves little useful state behind. This pattern works well when requests are short, stateless, and similar in cost.
LLM inference breaks those assumptions in several ways:
- Requests are not equal. A 100-token prompt and a 100k-token prompt have completely different memory and compute footprints. Some requests finish in milliseconds, while others may generate tokens for minutes.
- Workers carry state. During prefill, the model builds KV cache that can be reused by later requests. However, that reuse only happens if the next request reaches a worker that already owns the right cache. This is especially important for multi-turn chats and agent workflows where prompts often share large prefixes.
- Prefill and decode stress different resources. Prefill is mostly compute-bound, while decode is usually memory-bandwidth-bound. A worker busy decoding a long output can still accept new prefill work, and vice versa. Many distributed systems separate them entirely to avoid wasted GPU cycles and memory bandwidth. See prefill-decode disaggregation to learn more.
- Latency goals differ across workloads. Code completion, chat applications, agents, and batch inference jobs all have different latency requirements. Some workloads prioritize low TTFT, while others care more about throughput or total cost. If every worker is treated identically, expensive long-running requests can interfere with latency-sensitive ones. For example, a code completion request may end up waiting behind long agent generations even though the user expects an instant response.
When the router can't see these details, it starts making bad decisions, leading to:
- Missed cache reuse. A follow-up request may land on a worker without the previous KV cache. This forces the system to recompute the entire prefix, increasing TTFT.
- Increased latency. Requests may sit behind long decode-heavy generations or lose cache locality (meaning expensive re-computation).
- Lower throughput. GPU time gets wasted recomputing prefixes instead of serving new work.
- Load imbalance. Some workers become overloaded with long-running generations while others remain mostly idle.
For LLM inference, it is not enough to just spread traffic evenly. More importantly, the router should minimize the serving cost and keep the entire worker pool efficient and responsive.
Routing strategies
An LLM inference router can use many signals to decide where to send a request. The exact signals depend on the serving stack, but the most useful ones usually come from cache locality, worker load, memory pressure, and request priority.
Round-robin routing
Round-robin routing cycles through available workers in order and distributes requests evenly across the pool. It is simple, predictable, and useful as a baseline.
It works best when requests are short, prompts rarely repeat, and each worker can serve any request at roughly the same cost.
The downside is that round-robin routing is completely cache-blind. With N identical workers, a follow-up request has only about a 1 / N chance of landing on the same worker if no affinity mechanism exists.
For long prompts, multi-turn chats, and agent workloads, this often leads to repeated prefill computation and higher TTFT.
Random routing
Random routing selects a worker randomly for each request.
Like round-robin, it is easy to implement and sometimes useful for testing or benchmarking because it introduces little routing bias. However, it ignores almost all inference-specific runtime information, including prefix overlap, active decode load, and queue depth.
Least-loaded routing
Least-loaded routing sends new requests to the worker with the fewest active requests or connections.
This works better than round-robin when request durations vary significantly. A worker handling several long generations will naturally receive less new traffic than a mostly idle worker. This is a reasonable fallback when the router does not have reliable cache metadata.
However, least-loaded routing is still cache-blind. It may choose a lightly loaded worker that has no useful prefix cache over a moderately loaded worker that could skip most of prefill.
Direct routing
Direct routing explicitly targets a specific worker. For example, a gateway, endpoint picker, or custom scheduler may already know which worker owns the KV cache of a conversation. Instead of letting the serving layer make another routing decision, it directly forwards the request to that worker.
NVIDIA Dynamo supports this model through routing hints that specify the target worker.
Strictly speaking, it is not a policy by itself. It is a way to execute a decision made somewhere else.
KV cache utilization-aware routing
This strategy considers how much of each worker's memory is already occupied by KV cache.
This matters because long-context workloads can run into memory pressure even when raw GPU compute utilization looks moderate. A worker with high KV cache occupancy may need to evict useful cache blocks, reject new long prompts, or lose batching efficiency. Routing more requests to that worker can make latency and throughput worse.
A KV cache utilization-aware router can steer new requests toward workers with enough memory headroom.
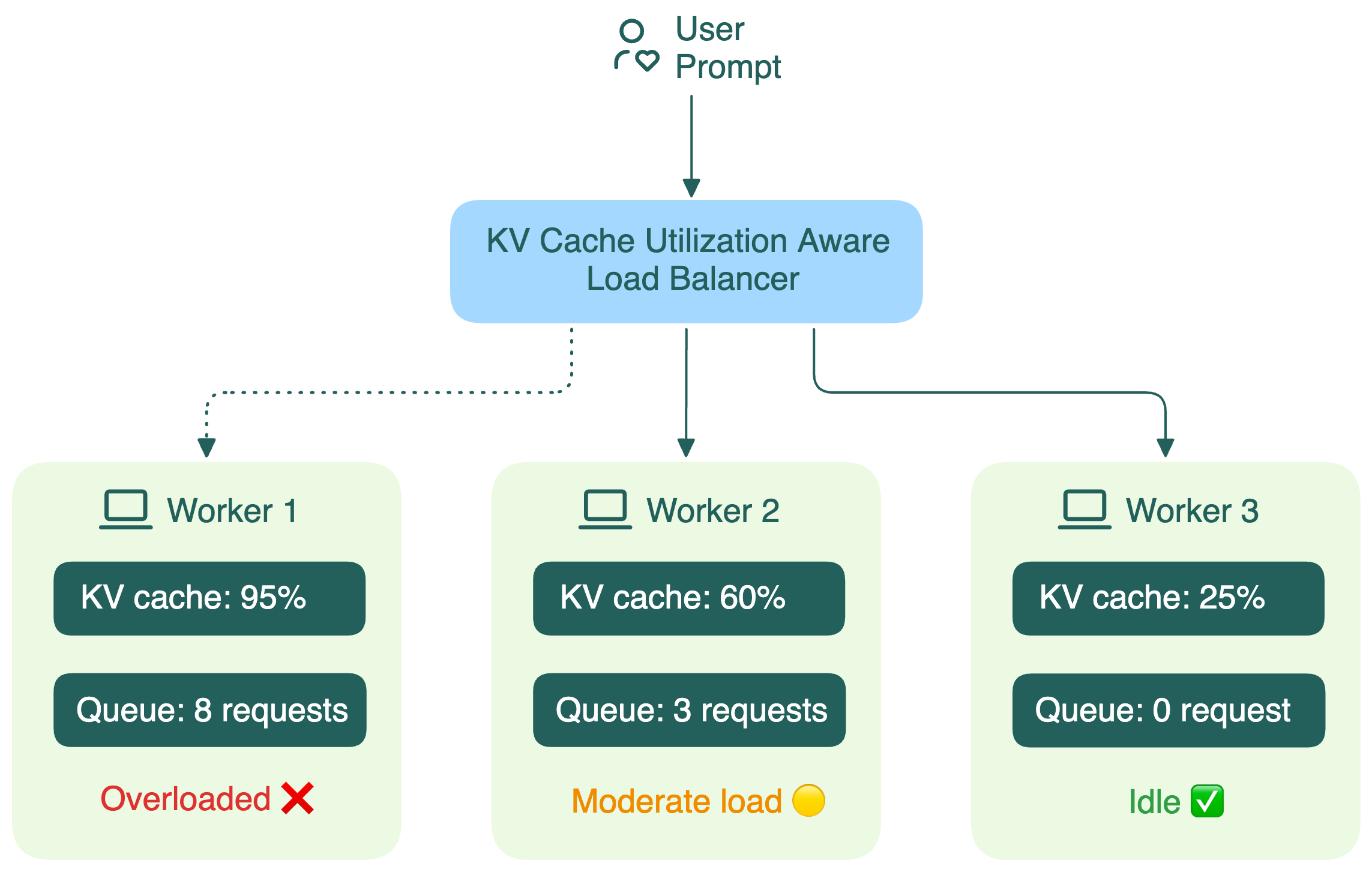
The key point is that a good router does not choose a worker only because it has the right prefix. A cache hit on a saturated worker can still be slower than a smaller cache hit on a worker with enough headroom.
The open-source community is already working on solutions. The Gateway API Inference Extension project uses an endpoint picker (EPP) to collect information on KV cache utilization, queue length, and LoRA adapters on each worker, and routes requests to the optimal replica.
Prefix-aware routing
Prefix-aware routing tries to send a request to a worker that already has the matching prefix cached.
This is relevant because prefix caching only helps if the request reaches a worker that can reuse the cached state. In a single model server, the cache is local and easy to find. In a distributed deployment, each worker has its own cache, so the router needs some way to preserve cache locality across requests.
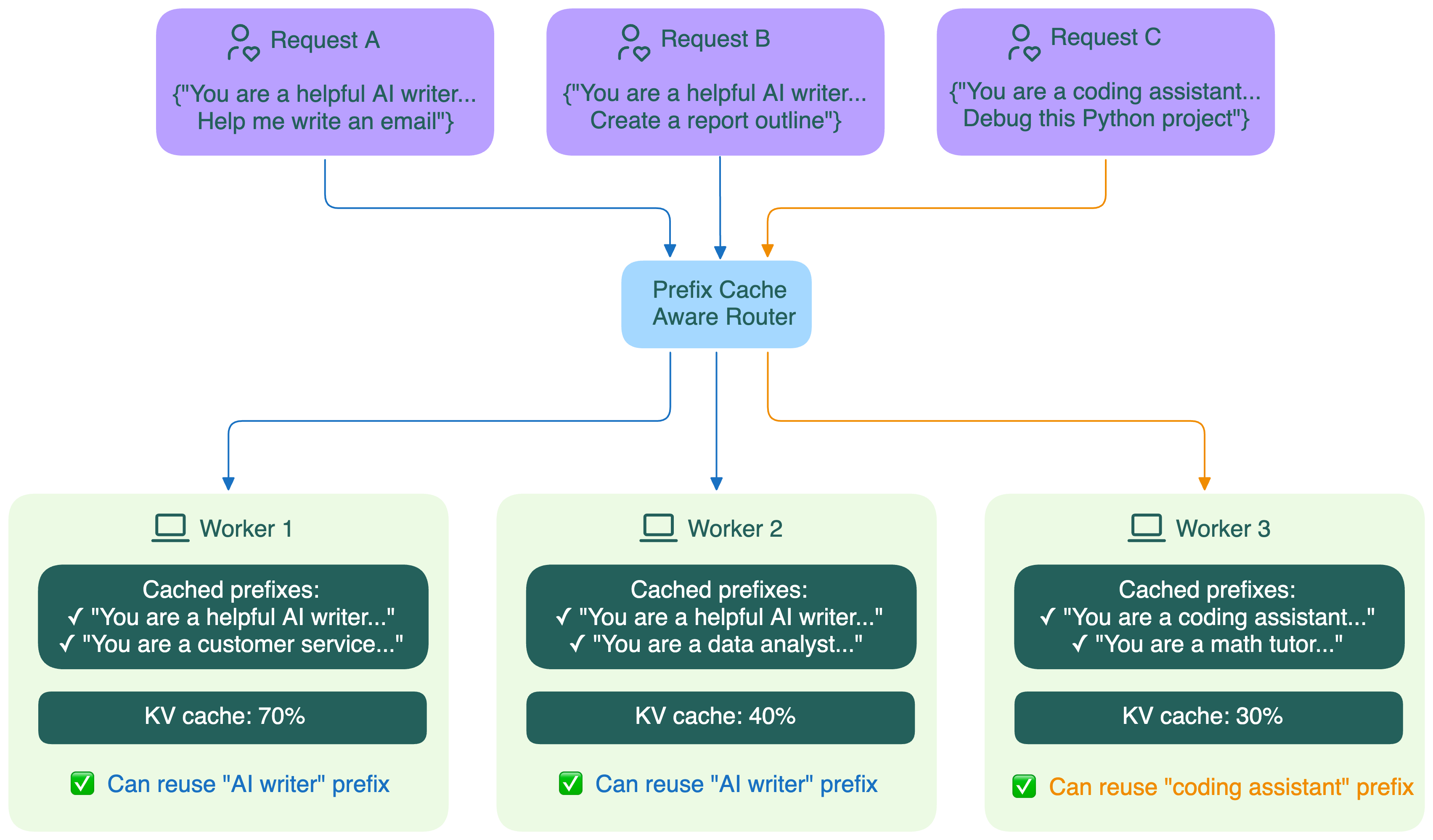
Different systems use different approaches to estimating or tracking cache locality:
- Prefix affinity. Requests with similar prefixes are routed to the same worker using an affinity mechanism. A simple implementation may rely on client-level session affinity, such as routing requests from the same client IP to the same backend. This is easy to implement, but it can overload workers when one client or prefix becomes hot. It also misses cache reuse opportunities across different clients.
- Prefix-aware consistent hashing. The router hashes part of the request prefix so similar prompts land on the same or nearby workers. For example, a simple strategy may hash only the first N tokens or characters of the prompt. This solution requires little routing metadata, but the effectiveness depends heavily on the quality of the hashing strategy and the prompt length distribution.
- Approximate prefix cache on the router. Let the router maintain an approximate lookup cache of the prefix caches on all the backend servers. This avoids detailed cache reporting, but the router's view can become stale after evictions or restarts.
- Precise cache-aware routing. Workers emit KV cache events or detailed cache metadata so the router can maintain an accurate global view of cache placement. For example, llm-d uses KV cache events from vLLM and SGLang to track where cache blocks live across serving Pods. The scheduler then scores workers based on how much of the incoming request’s prefix is already available there. It also combines cache locality with load-aware signals to avoid overloading hot replicas.
In general, more accurate cache signals improve cache reuse and reduce repeated prefill work. The trade-off is higher coordination cost, more metadata exchange, and more work in the routing layer.
Prefill/decode-aware routing
Routing becomes more interesting when prefill and decode are split across different workers. In a disaggregated setup, the router may need to decide:
- Whether the request should use local prefill or a separate prefill worker
- Which decode worker should own the active generation
- How KV cache should move between prefill and decode workers
- Whether cache locality is worth the transfer cost
For short prompts, local prefill may be faster because it avoids moving KV cache between workers. For long prompts with high cache overlap, routing to a worker that can reuse existing cache may matter more. The routing policy has to account for both compute cost and data movement.
This is why inference routing is not just a network-layer concern. It needs information from the model runtime, scheduler, and cache manager.
Hybrid scoring
Some inference routers become multi-signal scoring systems. They combine several factors to estimate the serving cost on each worker.
- Prefix and KV cache hit probability. Does the worker already contain KV cache for part of the request prefix?
- KV cache memory utilization. How much GPU memory is already occupied by active or cached KV state? Is the worker close to eviction pressure?
- Queue length. How many requests are waiting?
- Active tokens and decode load. How many tokens are currently being generated? This is often a good proxy for decode-time memory-bandwidth pressure.
- LoRA adapter availability. Does the worker already have the right adapter loaded? Swapping adapters mid-flight is expensive.
- Prefill vs. decode role. In disaggregated setups, is this worker dedicated to prefill or decode?
- SLA or priority class. Does the request have strict latency requirements or higher scheduling priority?
Several open-source projects already follow this direction:
- The SGLang router uses a cache-aware routing heuristic with load-balancing fallback. It tracks approximate prefix locality using radix trees and queue counts, then switches between cache-aware routing and shortest-queue routing depending on system imbalance.
- Dynamo routes requests by estimating both prefill and decode costs across workers. It considers KV cache overlap, active decode blocks, and workload placement to reduce redundant computation and improve serving efficiency.
- llm-d builds inference scheduling on top of the Gateway API Inference Extension project. It combines cache locality, worker load, and other runtime signals to provide intelligent request routing and scheduling on Kubernetes.
FAQs
Is inference routing the same as load balancing?
Inference routing includes load balancing, but it is broader. A normal load balancer mainly spreads traffic across backends. An inference router also considers cache locality, KV cache memory pressure, adapter state, prefill cost, decode load, and request priority and SLA.
Does cache-aware routing always reduce latency?
It depends. A cache hit on an overloaded worker can be slower than a smaller cache hit on a lightly loaded worker. Good routers combine cache overlap with queue and capacity signals instead of optimizing for cache hits alone.
Should every self-hosted LLM deployment use cache-aware routing?
Not necessarily. Start with simple routing if traffic is low, prompts are short, or cache reuse is rare. Add cache-aware routing when repeated context and distributed workers make recomputation expensive.