Trusted by the best AI teams







Scale Inference, Without Complexity
A complete platform that simplifies inference infrastructure while giving you full control over your deployment.
Deploy Any Model
Open Model Catalog
Deploy popular open-source models with a few clicks.
Custom Models
Unified framework for packaging and deploying models of any architecture, framework, or modality.
Manage Inference
Bento Inference Platform
A complete platform for managing, monitoring, and optimizing Al model inference.
Scale Efficiently
Bento Compute Engine
Intelligent resource management for optimal compute utilization.
Orchestrate Compute
Your Cloud
Complete control over your infrastructure and deployment environment.
Bento Cloud
Access to cutting-edge GPU hardware without the procurement hassle.
Any Open Models
Build and launch faster than ever - easily run and scale any model with unified deployment across frameworks.
Open Source Model Launcher
Pre-optimized models for inference with day 1 access to newly released models.
Custom Model Serving
Deploy models of any architecture, framework, or modality with full customization.
vllm_image=bentoml.images.Image(python_version='3.11').system_packages('curl', 'git').requirements_file('requirements.txt') @bentoml.service( image=vllm_image, resources={'gpu': 1, 'gpu_type': 'nvidia-h100'}, ) class VLLM: model = bentoml.models.HuggingFaceModel("meta-llama/Meta-Llama-3.1-8B-Instruct") def __init__(self) -> None: ... @bentoml.api async def generate( self, prompt: str, max_tokens: typing_extensions.Annotated[ int, annotated_types.Ge(128), annotated_types.Le(MAX_TOKENS) ] = MAX_TOKENS, ) -> typing.AsyncGenerator[str, None]: ...
Production-Ready Inference, Now
A complete platform that simplifies inference infrastructure while giving you full control over your deployment.
Tailored Optimization
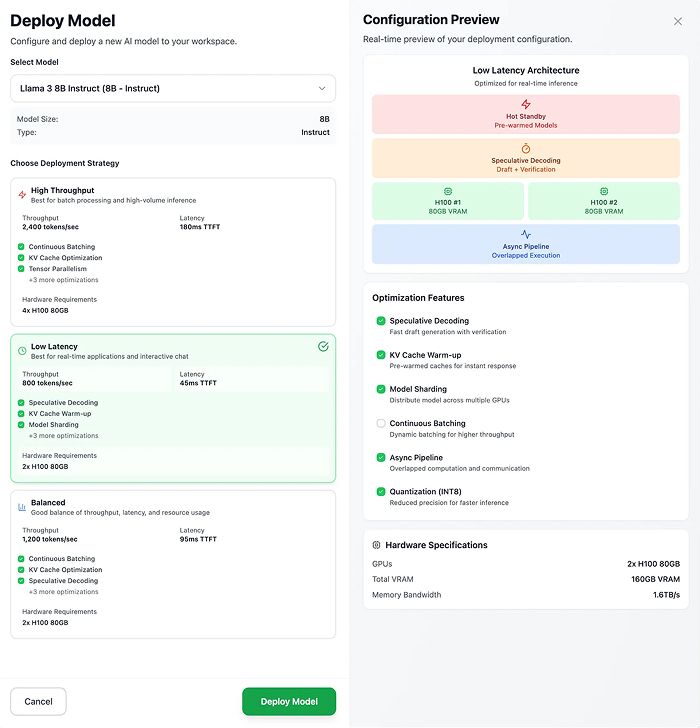
Bento’s inference stack is built for easy customization. Tune every layer of your deployment to balance speed, cost, and quality for your use case.

Optimize for your goals
Automatically find the optimal configuration based on your latency, throughput, or cost requirements.
Advanced performance tuning
Fine-tune every component to squeeze maximum efficiency from your hardware.
Distributed LLM inference
Run large models across multiple GPUs for faster, scalable inference.




Faster Path to Production AI
Everything developers need to build, ship, and scale AI inference.

Dev Codespace
Iterate in the cloud as fast as you do locally
From local edits to instant cloud GPU runs in seconds

LLM Gateway
Unified interface for all LLM providers
One unified API for all LLMs, giving you centralized cost control and optimization

Streamlined Operations
Complete deployment lifecycle management
Version control with rollbacks, plus canary, shadow, and A/B testing for faster, safer releases

Full Observability
Comprehensive monitoring and insights
Track compute and performance, monitor LLM-specific metrics, and stay on top of system health
Built For Enterprise
Enterprise-grade security, compliance, and operational capabilities for mission-critical AI deployments.
Self-hosted Anywhere
Deploy on any cloud or on-premises







Reliability
Infrastructure you can count on
Forward Deployed Engineering
Dedicated technical experts for your team
Data Sovereignty
Full control over your data
In Their Words
Hear from the teams who have transformed their AI/ML operations with BentoML.








